
この記事では前半にOpenAI Gym用の強化学習環境を自作する方法を紹介し、後半で実際に環境作成の具体例を紹介していきます。
こんな方におすすめ
- 強化学習環境の作成方法について知りたい
- 強化学習環境の作成の具体例が知りたい
強化学習環境とは
強化学習環境を作成するにあたり、強化学習環境とは何か再確認しておきたいと思います。
強化学習は、制御器(Agent)と環境(Environment)の2つを定義し、制御器から環境へは行動(action)が、環境から制御器へは観測(observation)と報酬(reward)が渡されるという問題設定のもと実行されます。ここで、制御器と環境は以下のように定義します。
| 語句 | 定義 | 例 |
|---|---|---|
| Agent | 環境を制御するプログラム | 深層強化学習プログラム |
| Environment | 制御対象 | 移動型ロボットと迷路 |
環境は制御対象の状態や報酬を計算可能なシステムである必要があり、例えばロボットの動きを強化学習で扱いたい場合、実世界であればロボットそのもののハードウェアがあればいいですが、仮想世界で学習させる場合は、物理エンジンを使用して物理的な環境を実現するところも含む必要があります。
ここまでの内容を図示すると以下のようになります。
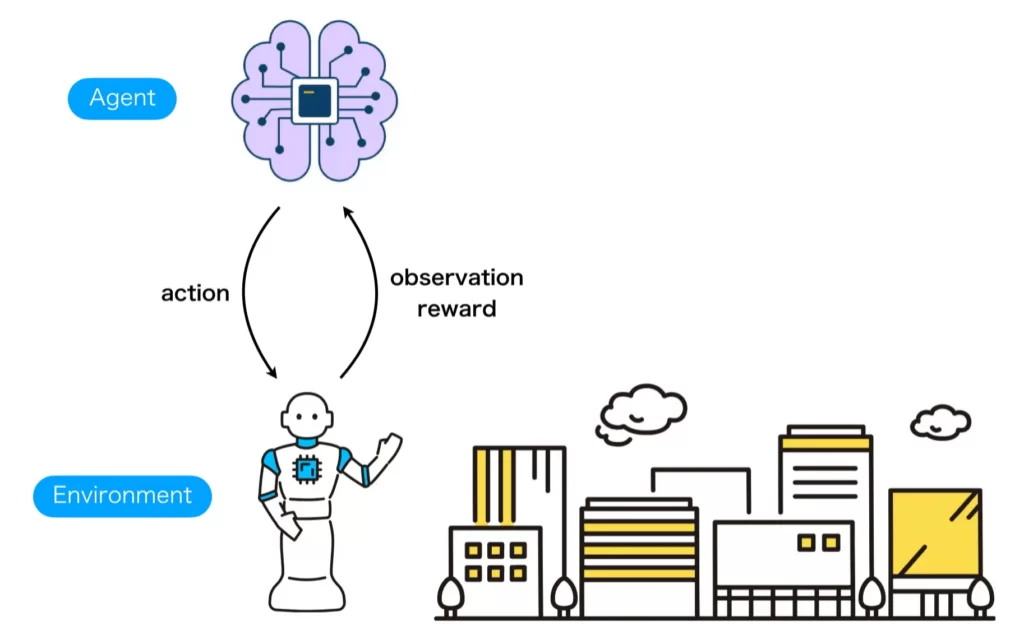
一般的に描かれる強化学習の説明イラストではAgent部分にロボットのイラストが使われることが多い印象を受けますが、ロボットは制御対象でありEnvironment側で定義すべきものです。既述の通りAgentは制御対象を制御するプログラムですので、DQNなどの学習器に対応する部分です。
よって、強化学習環境の作成は上図におけるEnvironment部分を自分で定義する作業になります。
とは言っても、全て自作するのは大変なので、OpenAI Gymが提供するインターフェース形式を利用して作成することが一般的に行われます。
OpenAI Gymのインターフェース形式
OpenAI Gymのインターフェース形式を利用するメリット
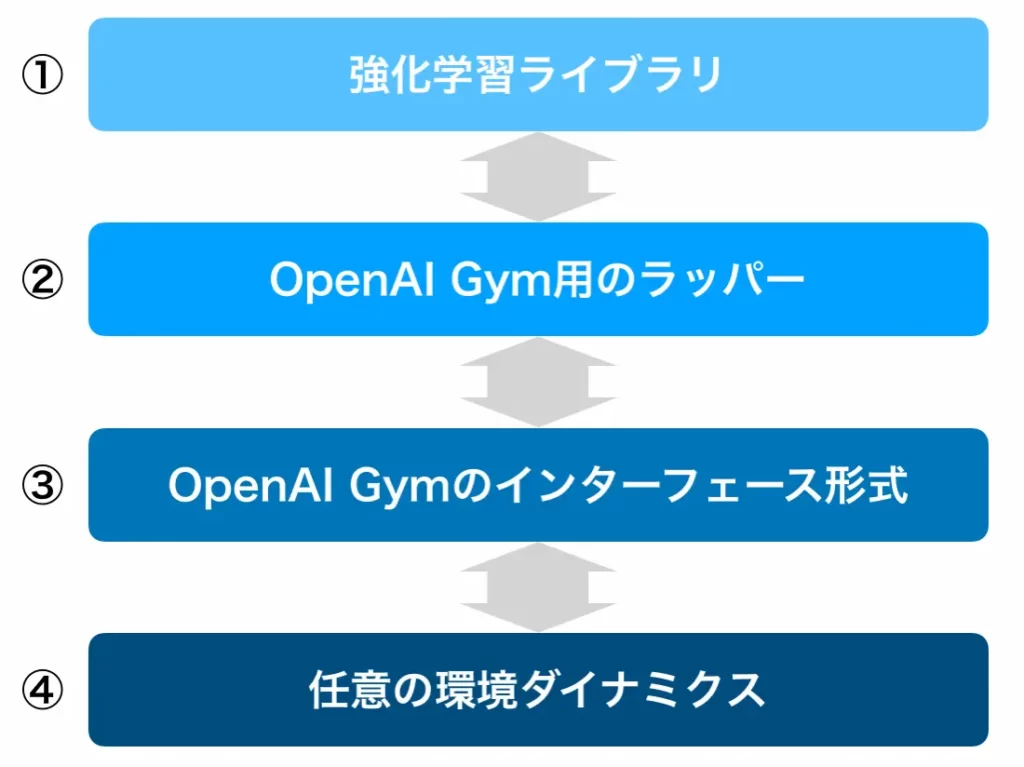
まず最初に、OpenAI Gymのインターフェース形式を利用するメリットについて下図を使用して説明します。OpenAI Gymのインターフェース形式に沿って環境を作成する場合は、以下の図のように4つの階層構造で実現されます。まず最も下層に、各々が学習させたい環境があります(④)。環境とは、ダイナミクスを決定するものであるため、環境ダイナミクスと呼ばれたりします。それをプログラムで扱うために、OpenAI Gymが採用している取り決めに従ってプログラムを作成するのが③になります。③でOpenAI Gymのインターフェース形式で環境ダイナミクスをカプセル化してしまえば、どのような環境ダイナミクスであろうと、OpenAI Gymでの利用を想定したプログラムであれば利用可能になります。これが、OpenAI Gym用のラッパーになります(②)。OpenAI Gym用のラッパーは多くの人が作成&公開しているので、自分の環境に容易に再利用して機能を追加することができますし、自作することもできます。そして、一般的な強化学習ライブラリであれば基本的にOpenAI Gymに対応しているため、これも容易に利用することができます。すなわち、OpenAI Gymのインターフェース形式を採用して強化学習環境を作成すると①や②を省略することができる可能性があります。
もし、OpenAI Gymのインターフェース形式を利用しなかったら、強化学習プログラムを含め、全てスクラッチで作成する必要があり開発効率が悪くなります。
他にも、OpenAI Gymのインターフェース形式で強化学習環境を作成するとプログラムの可読性が向上するなどの利点があります。ここまでで紹介した恩恵を以下にまとめます。
主な恩恵
- OpenAI Gymの利用者にとってプログラムの可読性が向上する
- OpenAI Gymインターフェースにより環境(Environment)と強化学習プログラム(Agent)が互いに依存しないプログラムにできるためモジュール性が向上する
- OpenAI Gym向けに用意されている多種多様なラッパーや強化学習ライブラリが利用できる
本記事で扱う内容は、③の部分になります。②の部分は別記事で紹介しています。
OpenAI Gym用のラッパーを自作してみたい方は以下の記事をご参考ください。

以降では、OpenAI Gymのインターフェース形式をGym形式と呼ぶことにします。
Gym形式の基本事項
Gym形式の強化学習環境を作成する場合に必要となる知識を紹介していきます。
基本ルール
Gym形式の強化学習環境を作成する際に必要になるルールを以下に示します。
基本ルール
- 自作の環境クラスは抽象クラスgym.Envを継承する
- コンストラクタには以下の3つを定義する
- action_space :エージェントが取りうる行動空間を定義
- observation_space:エージェントが受け取りうる観測空間を定義
- reward_range :報酬の範囲[最小値と最大値]を定義
- 少なくとも以下の3つのメソッドを定義する
- reset(self) :環境を初期状態にして初期状態(state)の観測(observation)をreturnする
- step(self, action) :行動を受け取り行動後の環境状態(state)の観測(observation)・即時報酬(reward)・エピソードの終了判定(done)・情報(info)をreturnする
- render(self, mode) :modeで指定されたように描画もしは配列をreturnする
- 必須ではないが極力以下の2つのメソッドも定義する
- close(self) :環境を終了する際に必要なクリーンアップ処理を実施する
- seed(self, seed=None) :シードを設定する
- 返り値は以下を満たす必要がある
- observation :object型。observation_spaceで設定した通りのサイズ・型のデータを格納。
- reward :float型。reward_rangeで設定した範囲内の値を格納。
- done :bool型。エピソードの終了判定。
- info :dict型。デバッグに役立つ情報など自由に利用可能。
上のルールを満たすプログラムは以下のようになります。以下のプログラムでは環境名をCustomEnvとしていますが、各々が作成したい環境名に読み替えてもらい、プログラム中の「...」をプログラムで埋めていきましょう。
import gym
from gym import spaces
class CustomEnv(gym.Env):
metadata = {'render.modes': ['human']}
def __init__(self):
super(CustomEnv, self).__init__()
self.action_space = ... # エージェントが取りうる行動空間を定義
self.observation_space = ... # エージェントが受け取りうる観測空間を定義
self.reward_range = ... # 報酬の範囲[最小値と最大値]を定義
def reset(self):
# 環境を初期状態にする関数
# 初期状態をreturnする
...
return obs
def step(self, action):
# 行動を受け取り行動後の状態をreturnする
...
return obs, reward, done, info
def render(self, mode='human'):
# modeとしてhuman, rgb_array, ansiが選択可能
# humanなら描画し, rgb_arrayならそれをreturnし, ansiなら文字列をreturnする
...
def close(self):
...
def seed(self, seed=None):
...行動空間・観測空間・報酬範囲の定義方法
Gym形式の基本ルールで、コンストラクタには行動空間(action_space)・観測空間(observation_space)・報酬範囲(reward_range)を定義する必要がることを解説しました。以下では、これらの定義方法について説明します。
行動空間と観測空間の定義方法
上のコード(CustomEnv.py)ではgymからspacesとよばれるパッケージを読み込んでいますが、行動空間と観測空間を定義する際はこのパッケージに含まれている型クラスを使って定義します。spacesパッケージには、行動空間及び観測空間の定義に使用可能なクラスが6つ定義されており、それぞれはspacesクラスを継承しています。かなり省略していますが、以下に6つの型クラスに関するクラス図を示します。
6つのうち、TupleとDictを除く4つは、データの型やサイズ、値の上限や下限など、扱う値そのものを定義をする際に使用します。ただ、4つの中でも、DiscreteとBoxのみを使うことが推奨されており、MultiDiscreteやMultiBinaryが利用されているところはあまり見たことがありません。TupleやDictは、DiscreteやBoxなどの型を複数集めて、行動空間と観測空間を定義するときに使用します。
以下に、DiscreteとBoxの定義と使い方について示します。
- Discrete:[0, n-1]で指定したn個の離散値空間を扱う整数型(int)
使い方はDiscrete(n) - Box:[low, high]で指定した連続値空間を扱う浮動小数点型(float)
使い方はBox(low, high, shape, dtype)
lowおよびhighはshapeで与えたサイズと同じndarrayになります。
次に、TupleとDictの使い方について示します。
- Tuple:DiscreteやBoxなどの型をタプルで合体
使い方の例はTuple((Discrete(2), Box(0, 1, (4, )))) - Dict:DiscreteやBoxなどの型を辞書で合体
使い方の例はDict({'position':Discrete(2), 'velocity':Box(0, 1, (4, ))})
報酬範囲の定義方法
報酬範囲(reward_range)の定義方法はとても簡単です。マイナス無限大からプラス無限大までを扱う場合はself.reward_range = (-float("inf"), float("inf"))とします。ただし、この場合は、デフォルトで設定されているので、あえて記述する必要はありません。報酬に具体的な範囲がある場合は、 self.reward_range = (min, max) として定義しましょう。
具体例
OpenAI Gymで提供されている環境の観測空間と行動空間、報酬範囲について幾つか具体例を見てみましょう。[詳細]
複数の種類の環境の観測空間、行動空間、 報酬範囲を調査し、パターンを調べたので以下の表で共有します。Gym形式の環境を作成する際の参考にしてみてください。
| Environment Id | Observation Space | Action Space | Reward Range |
|---|---|---|---|
| FrozenLake-v0 | Discrete(16) | Discrete(4) | (0, 1) |
| GuessingGame-v0 | Discrete(4) | Box(-10000.0, 10000.0, (1,), float32) | (-inf, inf) |
| Copy-v0 | Discrete(6) | Tuple(Discrete(2), Discrete(2), Discrete(5)) | (-inf, inf) |
| CartPole-v0 | Box(-3.4028234663852886e+38, 3.4028234663852886e+38, (4,), float32) | Discrete(2) | (-inf, inf) |
| CubeCrash-v0 | Box(0, 255, (40, 32, 3), uint8) | Discrete(3) | (-inf, inf) |
| Pendulum-v0 | Box(-8.0, 8.0, (3,), float32) | Box(-2.0, 2.0, (1,), float32) | (-inf, inf) |
| Blackjack-v0 | Tuple(Discrete(32), Discrete(11), Discrete(2)) | Discrete(2) | (-inf, inf) |
| KellyCoinflip-v0 | Tuple(Box(0.0, 250.0, (1,), float32), Discrete(301)) | Discrete(25000) | (0, 250.0) |
表においてCartPole-v0の観測空間Box(-3.4028234663852886e+38, 3.4028234663852886e+38, (4,), float32)の最小値-3.4028234663852886e+38および最大値3.4028234663852886e+38はサイズ4の配列全要素に適用化される範囲を示しているわけではないことに注意してください。表示の関係上、最も値が小さいものと最も値が大きいものが示されているだけになります。各要素の正確な値範囲を取得する際は、以下で示すlow及びhighプロパティにアクセスする必要があります。
Boxの最小値および最大値を取得する方法
既にBoxの使い方のところで最小値low及び最大値highの設定を行うことは示しました。強化学習ライブラリでGym形式を扱う際は、頻繁に値の最小値及び最大値にアクセスするので、low及びhightプロパティへアクセスする方法を紹介します。low及びhighプロパティへは以下のようにしてアクセスします。
print("Min:", env.observation_space.low)
print("Max:", env.observation_space.high)CartPole-v0環境の場合、出力は以下のようになります。
Min: [-4.8000002e+00 -3.4028235e+38 -4.1887903e-01 -3.4028235e+38]
Max: [4.8000002e+00 3.4028235e+38 4.1887903e-01 3.4028235e+38]この結果から、4つの成分それぞれに別途、値の範囲が定められていることが分かります。くれぐれも、 Box(-3.4028234663852886e+38, 3.4028234663852886e+38, (4,), float32) を見て、全要素の値範囲が-3.4028234663852886e+38から3.4028234663852886e+38と勘違いしないようにしましょう。
各メソッドの定義方法
resetメソッド
renderメソッドは、以前のエピソードをリセットし、新しいエピソードが生成可能な準備をします。そして、初期化後の観察observationを取得しリターンします。
リセットの際に、乱数seedのリセットはしてはいけないので注意してください。
renderメソッドは以下のように使用することを意識して作成します。
obs = env.reset()stepメソッド
stepメソッドは、action_spaceで定義された型に沿った行動値を受け取り、環境を1ステップだけ進めます。進めた後の観測、報酬、終了判定、その他の情報を生成し、リターンします。infoにはデバックに役立つ情報などを辞書型として格納することができます。唯一、自由に使える変数なので、存分にinfoを活用しましょう。
stepメソッドは以下のように使用することを意識して作成します。
obs, reward, done, info = step(action)renderメソッド
renderメソッドは、引数に応じて適切な挙動を示す必要があります。renderが想定している引数は以下に示す3種類です。
| 引数 | renderの処理 | 返り値 |
| human |
人にとって認識しやすいように可視化 |
なし |
| rgb_array | 返り値の生成処理 | shape=(x, y, 3)のndarray |
| ansi | 返り値の生成処理 | ansi文字列(str)もしくはStringIO.StringIO |
作成例は以下のようになります。
# 作成例
class CustomEnv(gym.Env):
metadata = {'render.modes': ['human', 'rgb_array']}
def render(self, mode='human'):
if mode == 'rgb_array':
return np.array(...)
elif mode == 'human':
...
else:
super(MyEnv, self).render(mode=mode)closeメソッド
環境を閉じるときに、必要な後始末を記述します。
closeメソッドは以下のように使用することを意識して作成します。
obs = env.reset()seedメソッド
seedメソッドでは、NumPyなど各種ライブラリの乱数値を指定します。
seedメソッドは以下のように使用することを意識して作成します。
obs = env.reset()Gymに登録する方法
ここでは、gymのライブラリが持つmakeを使用して自作の強化学習環境を生成できるようにします。
gym.makeから環境を生成するには環境IDを指定する必要があるため、事前に環境IDを設定して登録する必要があります。
# 環境IDを指定して環境を生成する
ENV_ID = 'CartPole-v0'
env = gym.make(ENV_ID)
# 生成済みの環境から環境IDを取得する
env.unwrapped.spec.idgymに環境を登録する
gymライブラリには自作環境をGymに登録するためのregister関数が用意されているのでこれを使用して登録します。
以下のようなディレクトリ構造で自作環境を作成したとします。自作環境のクラスが定義されているスクリプトはcustom_env.pyです。
cuntom-gym-env/
README.md
setup.py
cuntom_gym_env/
__init__.py
envs/
__init__.py
cuntom_env.py
・・・このとき、custom_gym_env直下の__init__.pyに以下の内容を記述することで、環境をGymに登録することができます。
from gym.envs.registration import register
register(
id='CustomEnv-v0',
entry_point='custom_gym_env.envs:CustomEnv'
)ここで決めなければならないことは、環境のID名ですが、名前はそれぞれ分かりやすいものを選び、後ろにバージョン番号”-v番号”を追加します。
これで登録が完了しました。これにより、IDを使用して自作環境を呼び出したり、環境名を確認したりすることが可能になりました。
補足
補足ですが、registerメソッドには、id及びentry_pointの他に、reward_threshold, nondeterministic, max_episode_steps, order_enforceといった引数を渡すことができます。これらの変数について以下の表にまとめました。
| 引数 | 型 | デフォルト値 | 定義 | その他 |
|---|---|---|---|---|
| id | str | 環境ID | ||
| entry_point | str | None | 自作環境のクラスのPythonエントリポイント | Optional |
| reward_threshold | int | None | タスクが解決されたとみなされる前の報酬の閾値 | Optional |
| nondeterministic | bool | False | シードを決めてもなお環境が非決定的なふるまいをするかどうか | |
| max_episode_steps | int | None | エピソードにおける最大ステップ数 | Optional |
| order_enforce | int | True | 環境をorderEnforcingラッパーでラップするかどうか | Optional |
迷路のGym形式強化学習環境の作成
ここまで説明した内容を踏まえて、迷路を題材にGym形式の強化学習環境を作成した具体例を紹介します。
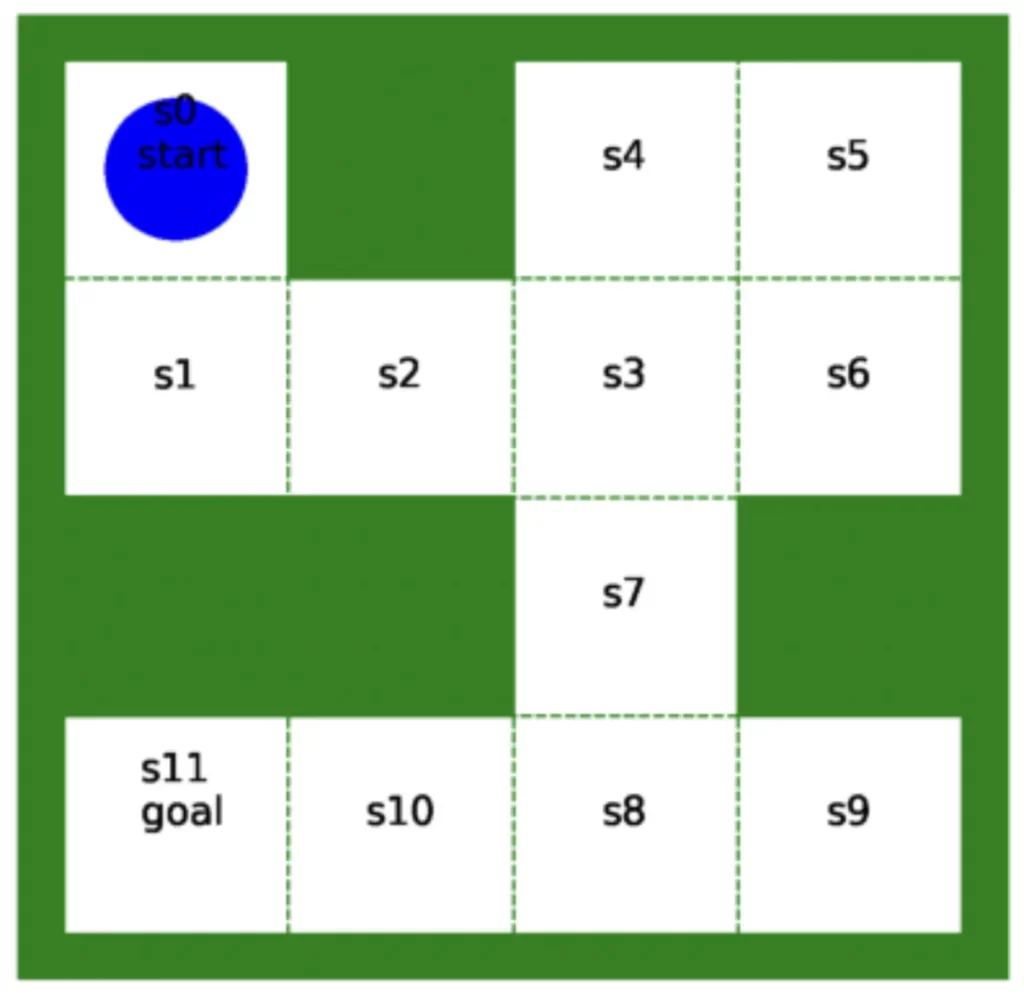
ここで作成した迷路環境は、以下のようなものです。枠が緑色で、移動可能なマスが12個、青色のエージェントで構成されています。
スクリプトの全体
ここで作成した迷路の強化学習環境のスクリプトの全体は以下のようになっています。
詳細はコメントとしてスクリプトの内部に書き込んであります。
# ライブラリのインポート
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as patches
import gym
from gym import spaces
# gym.Envを継承したEasyMazeクラス
class EasyMaze(gym.Env):
# この環境ではrenderのモードとしてrgb_arrayのみを用意していることを宣言しておく
# GymのWrapperなどから参照される可能性がある
metadata = {'render.modes': ['rgb_array']}
m = 0.2 # 迷路の周りの外枠の幅
c = 1 # 各セルの幅
agent_color = "blue" # エージェントの色
maze_color = "green" # 迷路の色
# 迷路の枠の描画関連情報
maze_info_rec = {"xy":[(0, 0), (0, m+4*c), (m+4*c, 0), (0, 0),
(m, m+c), (m+c, m+3*c), (m+3*c, m+c)],
"width":[m, 2*m+4*c, m, 2*m+4*c,
2*c, c, c],
"height":[2*m+4*c, m, 2*m+4*c, m,
c, c, c]}
# 迷路内の点線の表示関連情報
maze_info_line = {"s_xy":[(m, m+c), (m, m+2*c), (m, m+3*c),
(m+c, m), (m+2*c, m), (m+3*c, m)],
"e_xy":[(m+4*c, m+c), (m+4*c, m+2*c), (m+4*c, m+3*c),
(m+c, m+4*c), (m+2*c, m+4*c), (m+3*c, m+4*c)]}
# 状態テキストの表示位置情報
maze_state_pos = {"xy":[(m+0.5*c, m+3.5*c), (m+0.5*c, m+2.5*c), (m+1.5*c, m+2.5*c),
(m+2.5*c, m+2.5*c), (m+2.5*c, m+3.5*c), (m+3.5*c, m+3.5*c),
(m+3.5*c, m+2.5*c), (m+2.5*c, m+1.5*c), (m+2.5*c, m+0.5*c),
(m+3.5*c, m+0.5*c), (m+1.5*c, m+0.5*c), (m+0.5*c, m+0.5*c),],
"text":["s0", "s1", "s2", "s3", "s4", "s5", "s6",
"s7", "s8", "s9", "s10", "s11"]}
# 状態と行動に対する遷移先状態(ダイナミクス)
# 一般的にMDPにおけるダイナミクスは確率P(s'|s,a)で表されるが、ここでは決定論的なダイナミクスを採用
# 左から順番に行動入力が"left","top","right","down"の場合の各状態の遷移先を示す
# 例)状態"s0"のとき、
# "left"を受け取っても移動ができないので遷移先は現在と同じ"s0"
# "top"を受け取っても移動ができないので遷移先は現在と同じ"s0"
# "right"を受け取っても移動ができないので遷移先は現在と同じ"s0"
# "down"を受け取ったら下へ移動できるので遷移先は"s1"
# その他全ての状態も同様
dynamics = {"s0":["s0", "s0", "s0", "s1"],
"s1":["s1", "s0", "s2", "s1"],
"s2":["s1", "s2", "s3", "s2"],
"s3":["s2", "s4", "s6", "s7"],
"s4":["s4", "s4", "s5", "s3"],
"s5":["s4", "s5", "s5", "s6"],
"s6":["s3", "s5", "s6", "s6"],
"s7":["s7", "s3", "s7", "s8"],
"s8":["s10", "s7", "s9", "s8"],
"s9":["s8", "s9", "s9", "s9"],
"s10":["s11", "s10", "s8", "s10"],
"s11":["s11", "s11", "s10", "s11"]}
def __init__(self):
super(EasyMaze, self).__init__()
self.fig = None
self.ax = None
self.state = None
# 行動空間として0から3までの4種類の離散値を対象とする
# ちなみに、0は"left"、1は"top"、2は”right”、3は"down"に対応させた
self.action_space = gym.spaces.Discrete(4)
# 状態はエージェントが存在するセルの位置(12種類)
self.observation_space = gym.spaces.Discrete(12)
# 即時報酬の値は0から1の間とした
self.reward_range = (0, 1)
def reset(self):
# 迷路のスタート位置は"s0"とする
self.state = "s0"
# 初期状態の番号を観測として返す
return int(self.state[1:])
def step(self, action):
# 現在の状態と行動から次の状態に遷移
self.state = self.dynamics[self.state][action]
# ゴール状態"s11"に遷移していたら終了したことをdoneに格納&報酬1を格納
# その他の状態ならdone=False, reward=0とする
if self.state == "s11":
done = True
reward = 1
else:
done = False
reward = 0
# 今回の例ではinfoは使用しない
info = {}
return int(self.state[1:]), reward, done, info
# 描画関連の処理を実施
def render(self, mode='rgb_array'):
# matplotlibを用いて迷路を作成
self.make_maze()
# 現在位置にエージェントを配置
self.plot_agent(self.state)
# matplotlibで作成した図を配列にRGB配列に変換
rgb_array = self.fig2array()[:, :, :3]
# RGB配列をリターン
return rgb_array
# 迷路を描画する関数
def make_maze(self):
self.fig = plt.figure(figsize=(7, 7), dpi=200)
self.ax = plt.axes()
self.ax.axis("off")
# 迷路の外枠を表示
for i in range(len(self.maze_info_rec["xy"])):
r = patches.Rectangle(xy=self.maze_info_rec["xy"][i],
width=self.maze_info_rec["width"][i],
height=self.maze_info_rec["height"][i],
color=self.maze_color,
fill=True)
self.ax.add_patch(r)
# 点線による枠の表示
for i in range(len(self.maze_info_line["s_xy"])):
self.ax.plot([self.maze_info_line["s_xy"][i][0], self.maze_info_line["e_xy"][i][0]],
[self.maze_info_line["s_xy"][i][1], self.maze_info_line["e_xy"][i][1]],
linewidth=1,
linestyle="--",
color=self.maze_color)
# 状態のテキストを表示(スタート状態とゴール状態は後で描画)
for i in range(1, len(self.maze_state_pos["xy"])-1):
self.ax.text(self.maze_state_pos["xy"][i][0],
self.maze_state_pos["xy"][i][1],
self.maze_state_pos["text"][i],
size=14,
ha="center")
# スタート状態のテキストを描画
self.ax.text(self.maze_state_pos["xy"][0][0],
self.maze_state_pos["xy"][0][1],
"s0\n start",
size=14,
ha="center")
# ゴール状態のテキストを描画
self.ax.text(self.maze_state_pos["xy"][11][0],
self.maze_state_pos["xy"][11][1],
"s11\n goal",
size=14,
ha="center")
# エージェントを描画
def plot_agent(self, state_name):
state_index = self.maze_state_pos["text"].index(state_name)
agent_pos = self.maze_state_pos["xy"][state_index]
line, = self.ax.plot([agent_pos[0]],
[agent_pos[1]],
marker="o",
color=self.agent_color,
markersize=50)
# matplotlibの画像データをnumpyに変換
def fig2array(self):
self.fig.canvas.draw()
w, h = self.fig.canvas.get_width_height()
buf = np.fromstring(self.fig.canvas.tostring_argb(), dtype=np.uint8)
buf.shape = (w, h, 4)
buf = np.roll(buf, 3, axis=2)
return buf使ってみる
上で紹介した迷路クラスは、以下のようにしてインスタンス化して使用できます。
env = EasyMaze()適当にランダム行動をしてみます。Gym形式に沿って作成しているので、env.action_space.sample()からランダムな行動を生成することができます。
obs = env.reset()
for _ in range(200):
action = env.action_space.sample()
obs, re, done, info = env.step(action)
if done:
env.reset()上のプログラムを実行したとき、エージェントはどのような動きを行ったのか可視化したものが以下です。
※ここでは可視化のプログラムは示しません(結構複雑なので別の機会に紹介できればと思っています)が、興味があればrenderでステップ毎にRGB配列を取得して、animation化に挑戦してみてください!
最後に
長い記事になりましたが、OpenAI Gymのインターフェース形式に沿って強化学習環境を作成するメリットと、作成方法をご理解いただけたと思います。
とても複雑なように見えて、最終的には、以下に再掲する内容を守って作成すれば実現できる内容です。最後に、もう一度目を通してみてください。
基本ルール
- 自作の環境クラスは抽象クラスgym.Envを継承する
- コンストラクタには以下の3つを定義する
- action_space :エージェントが取りうる行動空間を定義
- observation_space:エージェントが受け取りうる観測空間を定義
- reward_range :報酬の範囲[最小値と最大値]を定義
- 少なくとも以下の3つのメソッドを定義する
- reset(self) :環境を初期状態にして初期状態(state)の観測(observation)をreturnする
- step(self, action) :行動を受け取り行動後の環境状態(state)の観測(observation)・即時報酬(reward)・エピソードの終了判定(done)・情報(info)をreturnする
- render(self, mode) :modeで指定されたように描画もしは配列をreturnする
- 必須ではないが極力以下の2つのメソッドも定義する
- close(self) :環境を終了する際に必要なクリーンアップ処理を実施する
- seed(self, seed=None) :シードを設定する
- 返り値は以下を満たす必要がある
- observation :object型。observation_spaceで設定した通りのサイズ・型のデータを格納。
- reward :float型。reward_rangeで設定した範囲内の値を格納。
- done :bool型。エピソードの終了判定。
- info :dict型。デバッグに役立つ情報など自由に利用可能。
最後までお読みいただきありがとうございました。