
畳み込みニューラルネットワークと聞いて、画像処理を真っ先に思いつくのが普通だと思います。でも、実は別の分野でも大きな成果を出しています。今回扱う1次元畳み込みニューラルネットワークは自然言語処理などの時系列情報を認識する性能で再帰型ニューラルネットワークを凌いでいます。
畳み込みニューラルネットワークとは
畳み込みニューラルネットワーク(Convolutional Neural Network;CNN)とは、主に画像認識の場で使用される深層ニューラルネットワークで、局所的受容野と重み共有という特徴を生かし、全結合ニューラルネットワークに比べて少ないパラメータ数で空間的な特徴を高精度で認識することを可能にしています。
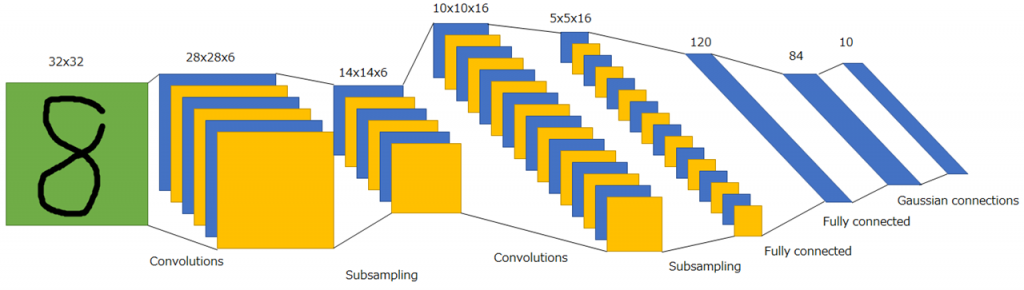
CNNの起源は視覚野のモデルであるネオコグニトロンで、現在の形に最も近い初代のCNNは、LeNetといわれます。
CNNの基礎については以下のページで扱っていますので、ぜひご覧ください。
1次元畳み込みとは
画像認識で使用される畳み込みに関する説明は、上に示したリンクの記事にゆずり、ここでは、1次元畳み込みについて説明します。
以下のGIF画像のように、入力として時刻tのベクトル、時刻t+1のベクトル、・・・、と並んでいる状態を考えてみます。これは時系列データであることに注意します。ここでは、入力が既に適切な形状に変換され、1次元畳み込みに入力される時点のことを考えていますが、この前の段階として、自然言語処理であれば、トークン化やベクトル化という操作が行われなければなりません。今回は、これについては省略します。1次元畳み込みでは、今までカーネルサイズとして(3,3)のように指定していたものを、ウィンドウサイズとよび、1つの値(例えば7)を指定します。7と指定した場合は、7時刻分のベクトルに渡る畳み込みをすることを示します。時間方向にベクトルが並べられると、2次元のマップのように見えますが、あくまでも時間方向軸が今まででいう空間方向で、縦はチャンネル軸になっています。画像認識で使用される畳み込み層が特徴マップの空間方向軸に対してて畳み込み処理を行うのと同様に、系列データに対して1次元畳み込みを適用する際には、時間軸上に対してのみ畳み込みを実施し、最後にチャンネル方向で足し合わせます。ここのポイントを一言でまとめると、「1次元畳み込みは時間軸方向に畳み込み処理を行っている」です。
図に記載し忘れてしまいましたが、入力データの横軸が時間軸、縦軸がチャンネル軸です。1次元畳み込みを適用後のチャンネル数はフィルタの枚数と等しくなります。
イメージは掴んでいただけたと思いますが、まだモヤモヤが残っていると思うので、次では具体例として今回使用するMNISTを使用して説明します。
MNISTデータで時系列処理
MNISTデータが持つデータの例を画像化しました。画像化の際に説明の便宜上、各マスを区切り、値を書き込みました。見ての通り、以下の図は7の手書き文字です。各ピクセルには、値が格納されており、色の濃さを表しています。まさにこれは画像認識で使用するときの形です。これを時系列データとして扱うにはどのようにしたらよいのでしょうか。それは、すべてを列もしくは行で分割し、そのベクトルは自然言語がトークン化およびベクトル化された結果として生じたものと考えればよいのです。

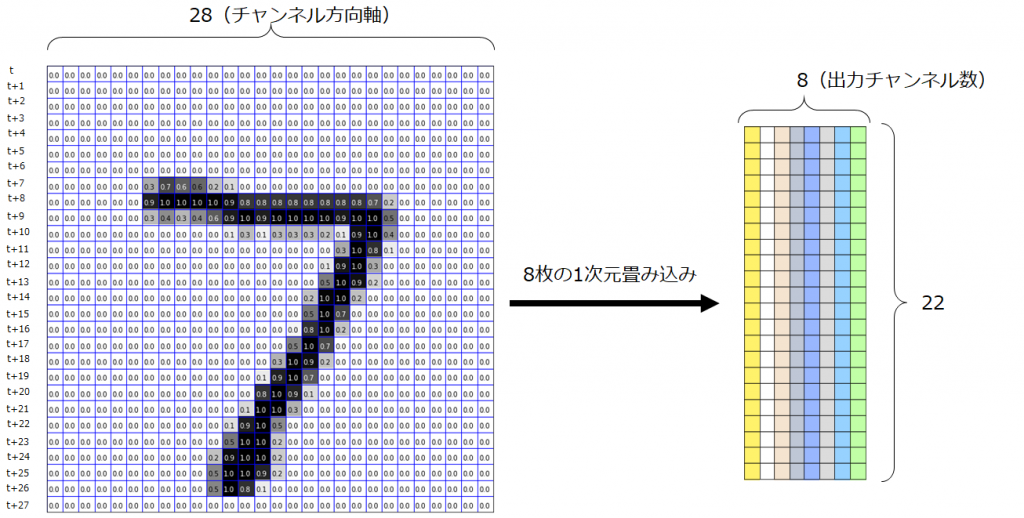
今回は、行方向を各トークンに対するベクトルと解釈して考えてみます。ここに、ウィンドウサイズを7として1次元畳み込みを実行することを考えます。時間軸方向としなかった軸はチャンネル軸となるので、1つの1次元畳み込みフィルタは、画像認識の畳み込みフィルタのときと同様にチャンネル方向にも複数枚フィルタを保持しています。そのため、1種類の1次元畳み込みフィルタをMNISTデータに適用する場合は、チャンネル方向に28個フィルタを持つことを意味します。その後、チャンネル方向で各要素ごとに足し合わせ、閾値を足し活性化関数を適用します。
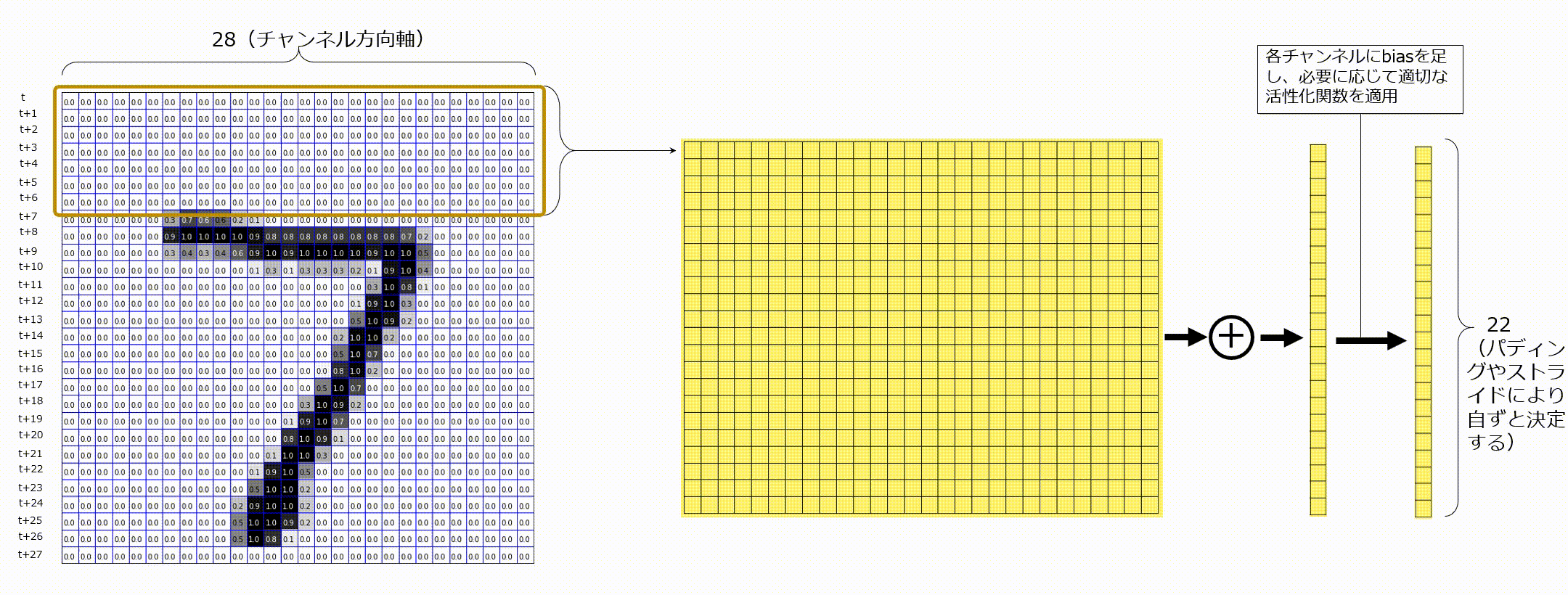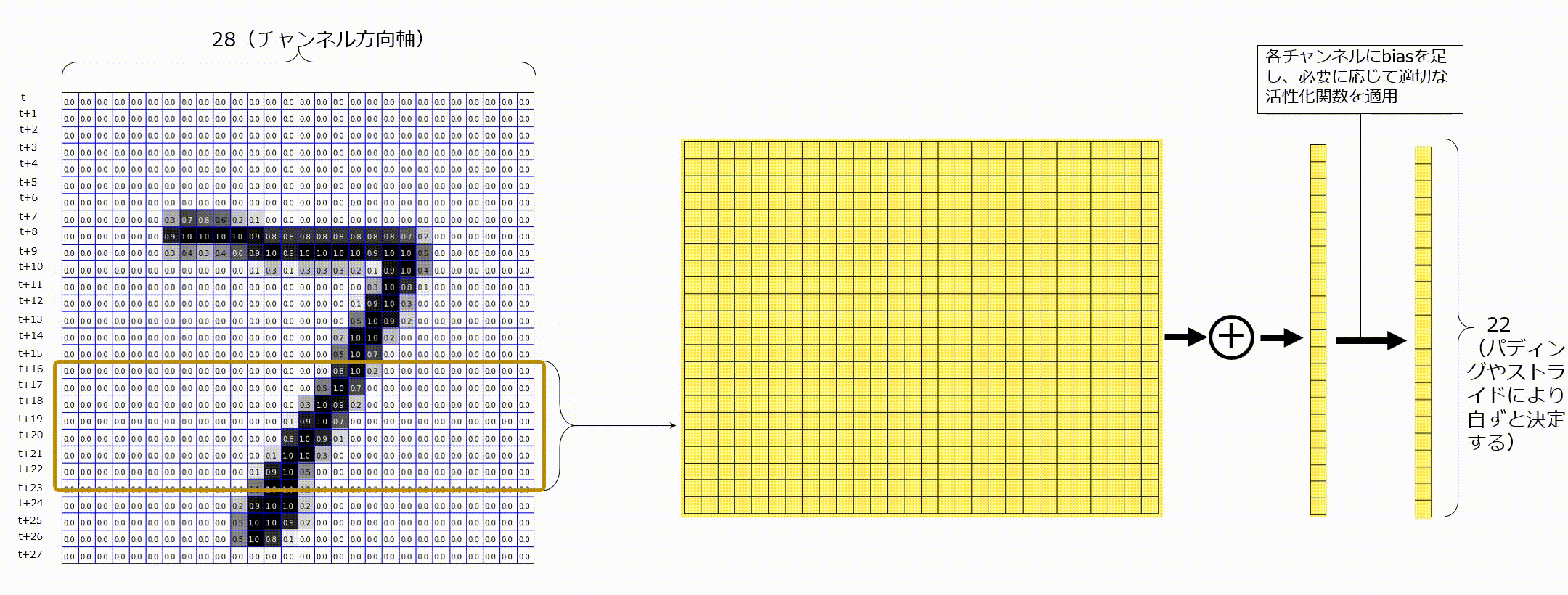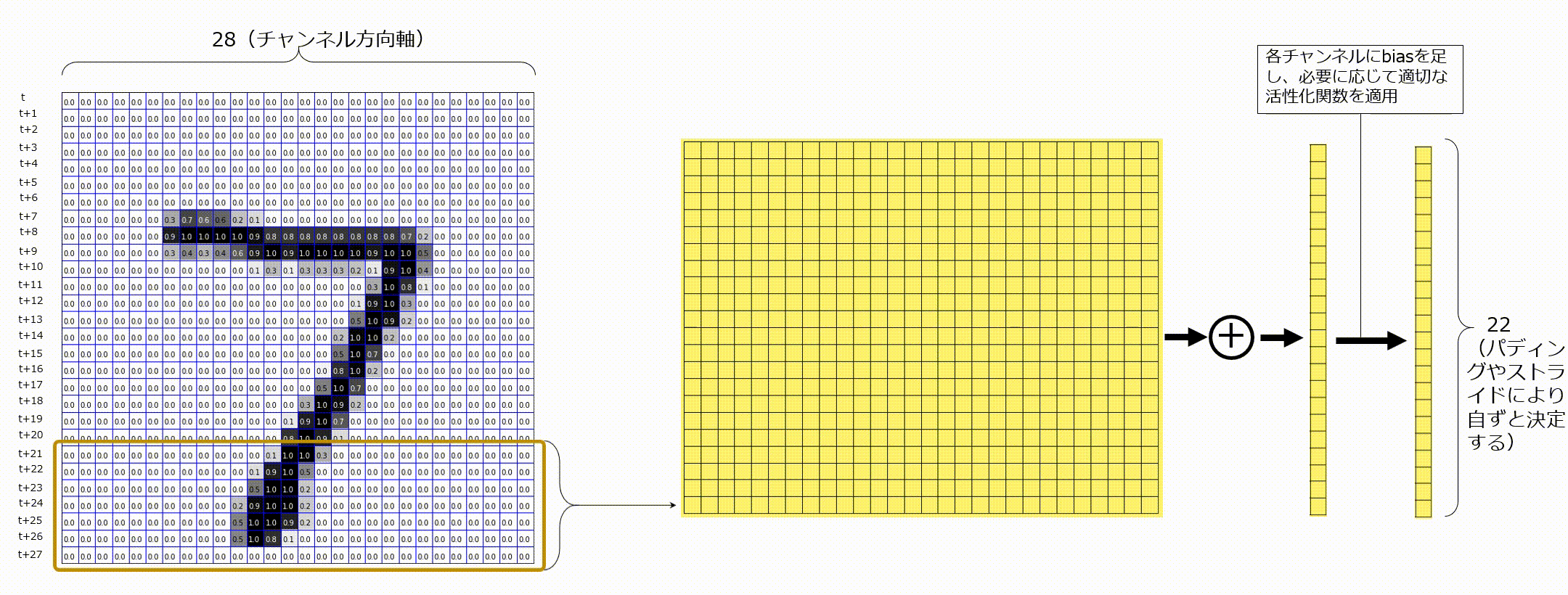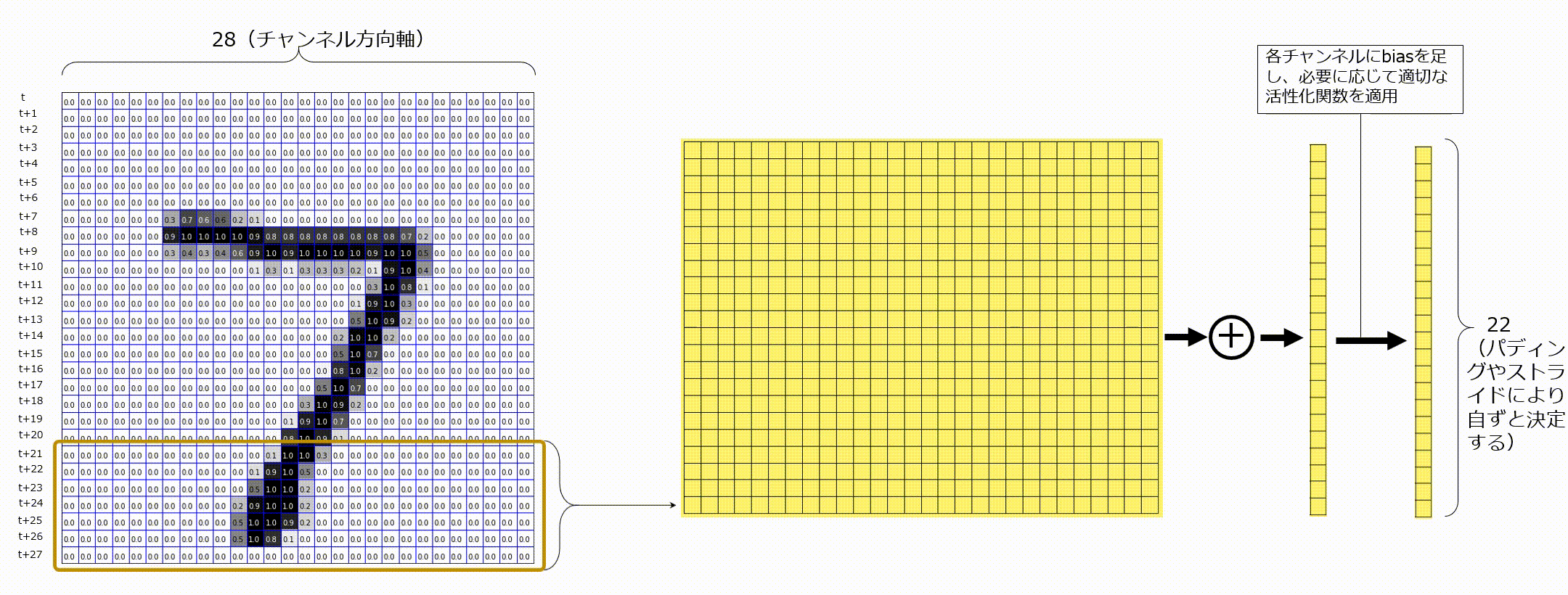
複数枚の1次元畳み込みフィルタを適用する場合は、次のようにそれぞれの畳み込みフィルタから出力されるものをチャンネル方向に並べます。
プーリングも畳み込みと同様で時間軸方向に対してサンプリングを行います。
RNN(GRU)との比較
時系列データ処理では再帰型ニューラルネットワーク(RNN, LSTM, GRU など)が一般的なイメージだと思うので、RNNの代表として高性能なGRUと、1次元CNNを処理速度と認識性能で比較したいと思います。
※RNN、LSTM、GRUについての説明は、以下の記事で説明しているので、気になったら読んでみてください。
MNISTデータを時系列処理
MNISTで時系列処理を行う場合は、上で説明したようにベクトルに分け、時系列分析を行います。
※「いち、に、さん、...」という自然言語をトークン化及びベクトル化すると、各数字に1つのベクトルが割り当てられるだけになるだけなので、1つの数字を28時刻分のベクトルの時系列で表すには無理がありますが、今回は、ベクトル化した結果、28時刻分の時系列データになったと仮定します。
今回は、kerasを使用して、モデルを構築していきます。
1次元CNNの場合
プログラムを以下に示します。
from tensorflow.keras.models import Sequential
from tensorflow.keras import layers
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
# 学習データをロード
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 正規化する
x_train = x_train / 255
x_test = x_test / 255
# onehotベクトル表現にする
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# モデルを定義
model = Sequential()
model.add(layers.Conv1D(32, 7, activation='relu', input_shape=(28, 28)))
model.add(layers.MaxPool1D(3))
model.add(layers.Conv1D(32, 5, activation='relu'))
model.add(layers.GlobalAveragePooling1D())
model.add(layers.Dense(10, activation='softmax'))
model.summary()
model.compile(optimizer=RMSprop(lr=1e-4),
loss='categorical_crossentropy',
metrics=['acc'])
# モデルのトレーニングを実施
history = model.fit(x_train, y_train, epochs=100, batch_size=128, validation_split=0.2)summaryで表示されるものを示します。conv1d_1のパラメータ数の求め方を確認しておきます。ウィンドウサイズ7の1次元畳み込みフィルタをチャンネル数28のデータ(ベクトルの成分数)に適用することを考えており、それを32種類適用するので、
\(
\begin{eqnarray}
\begin{array}{rcl}
&&\mbox{window_size}×\mbox{input_channels}×\mbox{output_channels}+\mbox{num_bias}\\
&=&7×28×32+32\\
&=&6304
\end{array}
\end{eqnarray}
\)
となります。2つ目のconv1d_2のパラメータ数は、\(5×32×32+32=5152\)です。
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv1d_1 (Conv1D) (None, 22, 32) 6304
_________________________________________________________________
max_pooling1d_1 (MaxPooling1 (None, 7, 32) 0
_________________________________________________________________
conv1d_2 (Conv1D) (None, 3, 32) 5152
_________________________________________________________________
global_average_pooling1d_1 ( (None, 32) 0
_________________________________________________________________
dense_1 (Dense) (None, 10) 330
=================================================================
Total params: 11,786
Trainable params: 11,786
Non-trainable params: 0
_________________________________________________________________学習最中に表示されるログを最初と最後のみ示します。注目していただきたいのは、モデルの処理の軽さと学習の速さです。1エポックが3秒で終わっていて、また以下では省略していますが、5エポック目、すなわち学習開始から15秒後には検証データでの正解率が91%になりました。学習に要した時間は約5分です。(ここではRMSPropを使用しましたが、Adamaxを使用して最適化したら2エポック目で90%以上の正解率を達成しました。)
Epoch 1/100
375/375 [==============================] - 3s 8ms/step - loss: 1.9473 - acc: 0.4046 - val_loss: 1.4880 - val_acc: 0.6587
Epoch 2/100
375/375 [==============================] - 3s 7ms/step - loss: 1.1329 - acc: 0.7218 - val_loss: 0.8373 - val_acc: 0.7905
Epoch 3/100
375/375 [==============================] - 3s 7ms/step - loss: 0.7130 - acc: 0.8121 - val_loss: 0.5769 - val_acc: 0.8497
・
・
・
Epoch 98/100
375/375 [==============================] - 3s 7ms/step - loss: 0.0522 - acc: 0.9846 - val_loss: 0.0661 - val_acc: 0.9817
Epoch 99/100
375/375 [==============================] - 3s 7ms/step - loss: 0.0519 - acc: 0.9847 - val_loss: 0.0662 - val_acc: 0.9809
Epoch 100/100
375/375 [==============================] - 3s 7ms/step - loss: 0.0516 - acc: 0.9845 - val_loss: 0.0659 - val_acc: 0.9817結果のグラフを以下のプログラムで表示してみます。
import matplotlib.pyplot as plt
import numpy as np
acc = history.history['acc']
loss = history.history['loss']
val_acc = history.history['val_acc']
val_loss = history.history['val_loss']
# x軸としてepochsを用意
epochs = np.arange(1, len(acc) + 1, 1)
plt.figure(figsize=(20, 5))
plt.subplot(1, 2, 1)
plt.plot(epochs, acc, label='training_acc')
plt.plot(epochs, val_acc, label='validation_acc')
plt.xlabel('epochs')
plt.ylabel('accuracy [%]')
plt.grid()
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(epochs, loss, label='training_loss')
plt.plot(epochs, val_loss, label='validation_loss')
plt.xlabel('epochs')
plt.ylabel('loss')
plt.grid()
plt.legend()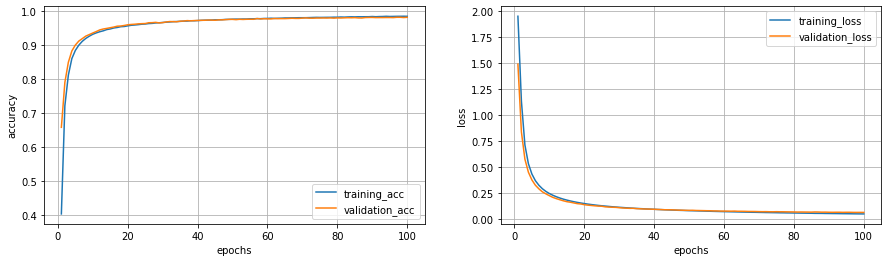
これだけ見せられても比較対象がないと1次元CNNの凄さが分からないと思うので、計算コストが軽くて性能が良いGRUと比較してみたいと思います。
GRUの場合
上記のプログラム内において、modelの部分を以下で定義するmodel_1に書き換えます。
model_1 = Sequential()
model_1.add(layers.GRU(32, activation='relu', return_sequences=True, input_shape=(28, 28)))
model_1.add(layers.GRU(32, activation='relu'))
model_1.add(layers.Dense(10, activation='softmax'))このとき、summaryは、以下のようになります。先に示した1次元畳み込みの時のsummaryと比較していただくと、パラメータの数がほぼ同じであることが分かると思います。畳み込みフィルタの場合、以前の記事で説明していますが、重み共有が行われるため、実際のパラメータ数よりもはるかに大きな表現能力があることが予想されるため、パラメータ数のみで比較するのが良いとは言えませんが、一つの指標として比較してみます。
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
gru (GRU) (None, 28, 32) 5952
_________________________________________________________________
gru_1 (GRU) (None, 32) 6336
_________________________________________________________________
dense_2 (Dense) (None, 10) 330
=================================================================
Total params: 12,618
Trainable params: 12,618
Non-trainable params: 0
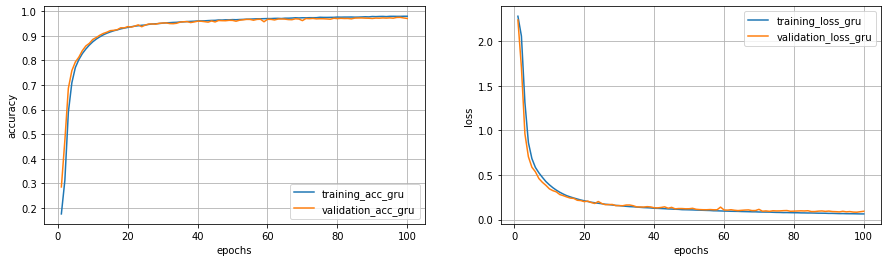
_________________________________________________________________学習ログの最初と最後を示します。1エポック終了するのに9秒ほどで、検証データの正解率が90%を超すのは、12エポック目です。
Epoch 1/100
375/375 [==============================] - 9s 24ms/step - loss: 2.2791 - acc: 0.1755 - val_loss: 2.2371 - val_acc: 0.2853
Epoch 2/100
375/375 [==============================] - 9s 23ms/step - loss: 2.0579 - acc: 0.3122 - val_loss: 1.7070 - val_acc: 0.4748
Epoch 3/100
375/375 [==============================] - 9s 23ms/step - loss: 1.3151 - acc: 0.5895 - val_loss: 0.9624 - val_acc: 0.6867
・
・
・
Epoch 98/100
375/375 [==============================] - 9s 23ms/step - loss: 0.0651 - acc: 0.9792 - val_loss: 0.0834 - val_acc: 0.9751
Epoch 99/100
375/375 [==============================] - 9s 23ms/step - loss: 0.0643 - acc: 0.9797 - val_loss: 0.0888 - val_acc: 0.9727
Epoch 100/100
375/375 [==============================] - 9s 23ms/step - loss: 0.0642 - acc: 0.9796 - val_loss: 0.0939 - val_acc: 0.9707正解率と誤差関数の値の変化の結果を示します。
結果からわかること
まずは、二つのグラフを合わせてみましょう。今までのグラフだと少し小さいので、それぞれ大きくしました。
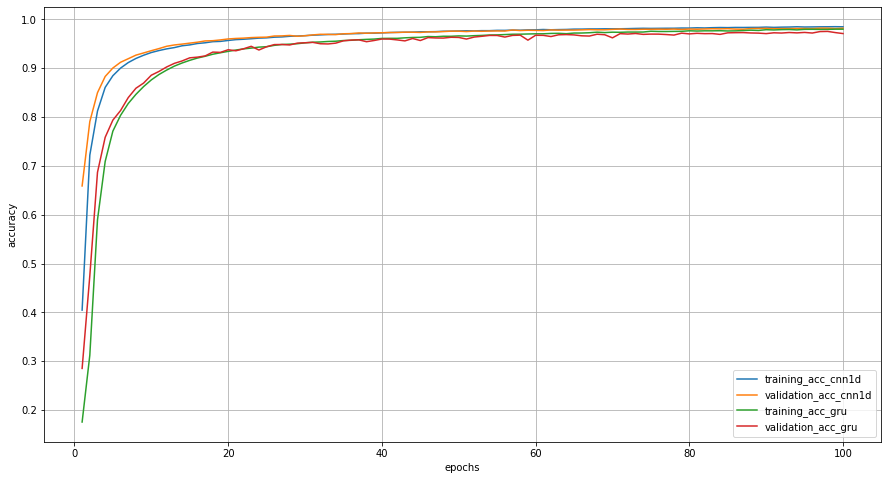
正解率は全体的に1次元CNNの方が高い状態を維持していました。100エポック目では両者の正解率の幅が縮まりましたが、それでも、1次元CNNにわずかに負けています。
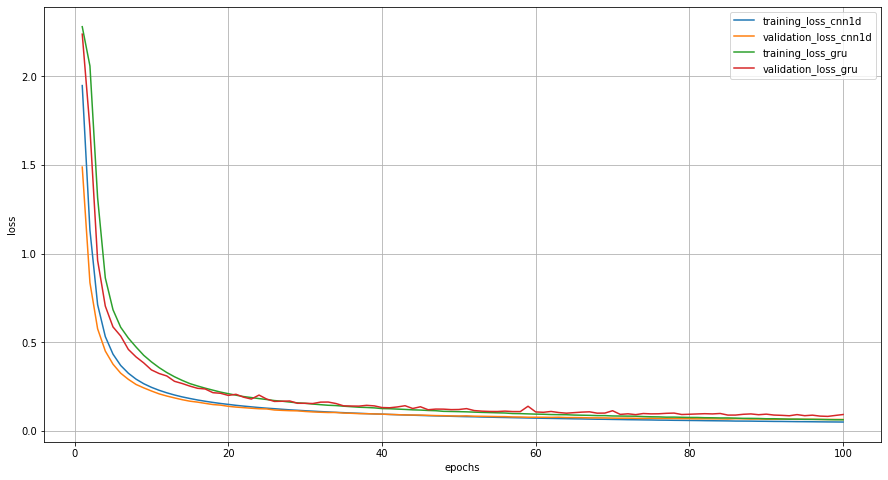
誤差関数のグラフは正解率の推移を逆にしたようなものになりました。
他には、先ほどの実行結果のログから、1エポックに要する時間は1次元CNNが約3秒、GRUが約9秒となっており、処理速度に関しても1次元CNNの圧勝となりました。
まとめ
示した結果のみからは、再帰型ニューラルネットワークより1次元CNNの方が、処理時間および正解率の観点から圧倒的に高性能であることが分かります。とはいえ、1次元CNNの場合は、考慮できる時刻数がウィンドウサイズで固定されるため、より長期間の記憶を保持できるLSTMやGRUには劣る面があると考えるべきです。そのため、入力に近い側で1次元CNNを、高次な領域でGRUを適用するなど、2つを混ぜて深層ニューラルネットワークを構築する小式を採用すると良いと考えられます。機会があったら1次元CNN+GRUについて扱えればと思います。