
本記事は、当サイトのYouTubeチャンネルで公開している動画「[Weekly RL with code]DQNでCartPole問題を解く」の内容を記事として書き起こしたものです。記載内容は、動画で話している内容と全く同じです。動画で学びたい方でも、記事として読みたい方でも楽しみながら強化学習について学ぶことができます。それでは内容に入っていきます。
※Weekly RL with codeシリーズに関する説明は省略します。気になる方は動画の冒頭をご視聴いただければと思います。
今回の内容
さて、今回のテーマはOpenAI Gymで提供されているCartPole環境をDQNで解くことを通じて強化学習について理解を深めることです。この動画を通して一緒に理解を深めていきましょう。今回は次のような流れで進めていきます。
まず最初に強化学習の基礎知識について初めての方でもわかるように説明します。その後に今回扱う強化学習環境のCartPole環境について説明をします。次に、ここまでの内容を踏まえて、コードを実行していきます。コードはgoogle colaboratoryで実行します。今回扱ったコードはノードブック形式で公開していますので、ぜひご利用ください。リンクは概要欄に記載の通りです。最後に、今回の内容をまとめて今回の内容を終わりにしたいと思います。

強化学習の基礎知識
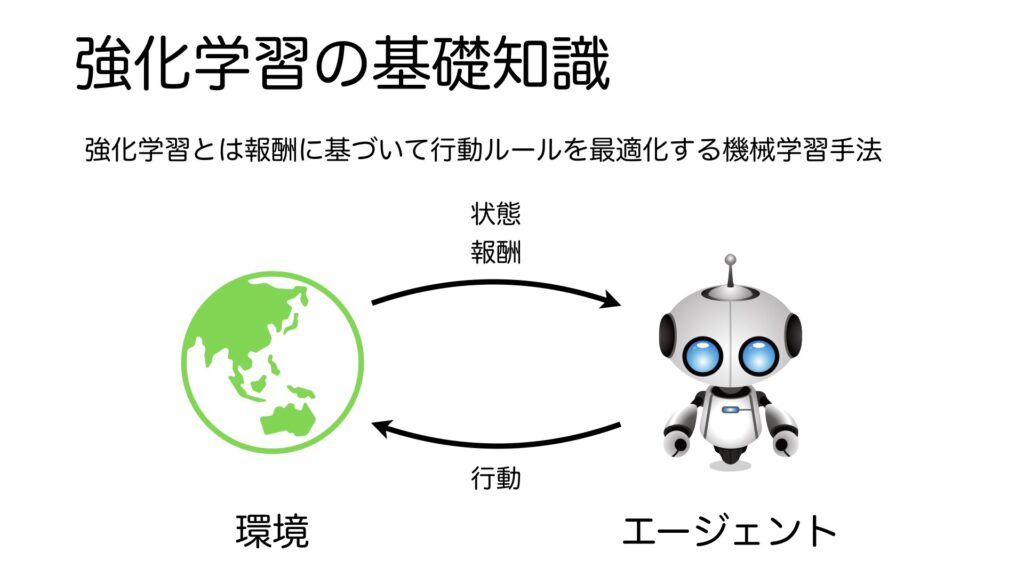
それでは、強化学習の基礎知識について説明します。強化学習とは、報酬に基づいて行動ルールを最適化する機械学習手法です。強化学習は制御器と制御対象に分けてモデル化されています。制御器のことをエージェント、制御対象のことを環境と呼びます。エージェントが行動することで環境へ作用すると、その結果、変化した後の環境の状態とその評価としての報酬を環境から受け取ります。
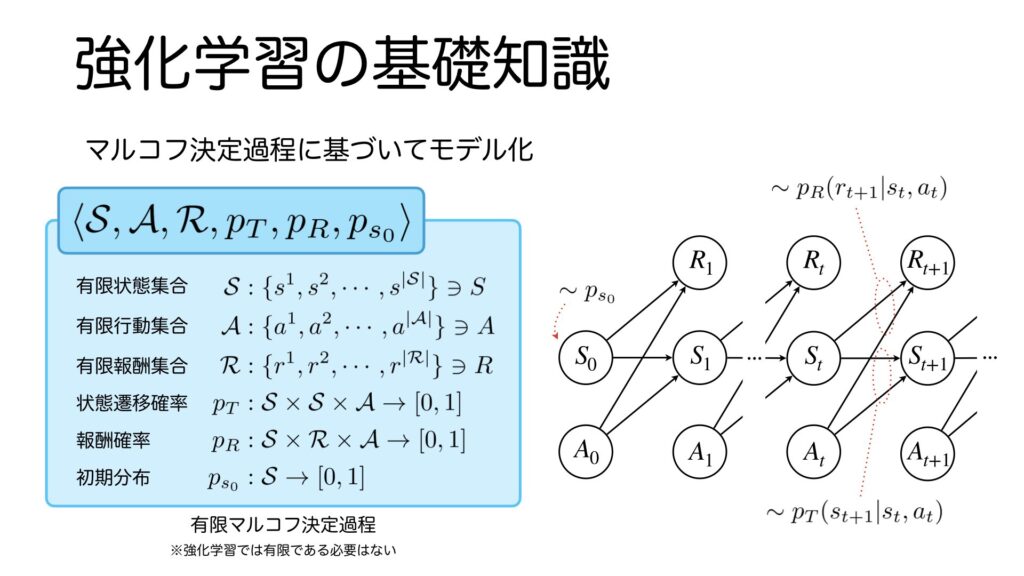
環境のモデルはマルコフ決定過程と呼ばれる確率過程に基づいています。少し難しそうな数式が出てきましたが、これは有限マルコフ決定過程を表しています。オートマトンを学んだことがある方でしたら心当たりのある表記ではないでしょうか。ここでは、難しい部分は扱わず、要点を絞って分かりやすく手短に説明します。有限マルコフ決定過程の構成要素は、有限状態集合、有限行動集合、有限報酬集合、状態遷移確率、報酬確率、初期分布です。有限マルコフ決定過程をグラフで表すと右の図のようになります。ここで大文字は確率変数を小文字は実測値を表します。まず一番初めの状態\(S_0\)は初期分布に基づいて生成されます。任意の時刻\(t\)において、状態が\(s_t\)、エージェントの行動が\(a_t\)のとき、時刻\(t+1\)において状態\(s_{t+1}\)へ遷移する確率は状態遷移確率に従います。遷移は確率的に行われます。同様に、報酬\(r_{t+1}\)は報酬確率に従って確率的に得られます。ここで各時刻で得られた報酬に時間割引を導入して足し合わせた値の期待値が最大になるような行動を強化学習は学習します。
ここでは、説明の都合上、有限マルコフ決定過程を用いましたが、強化学習ではアルゴリズムによって、状態や行動が有限でなくても問題ないものがあります。今回扱うDQNは状態は無限、すなわち連続値でも扱えるものになります。
CartPole環境
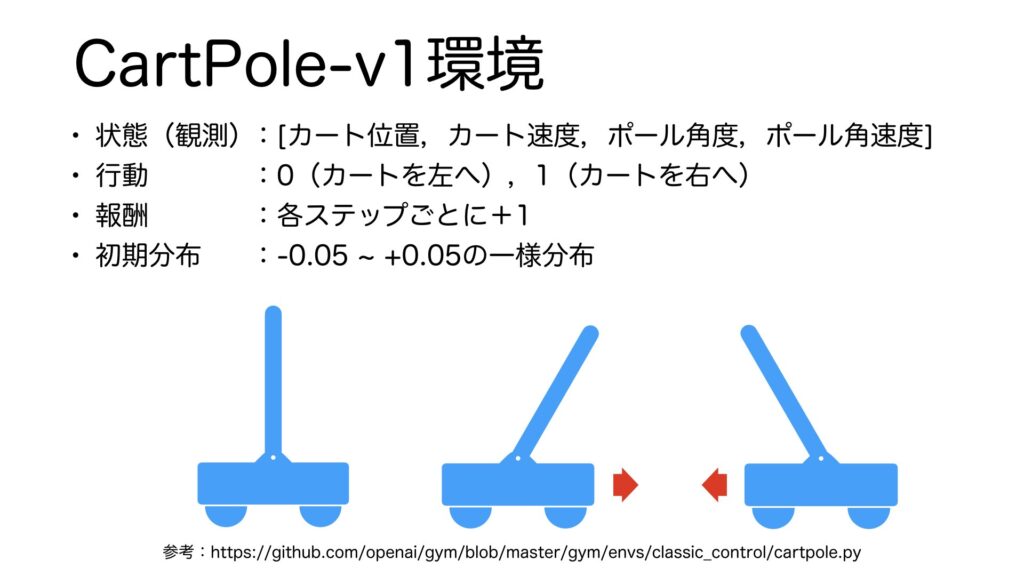
それでは、CartPole環境について説明します。CartPole環境とは、車輪がついた台車の上に、棒を立てて、それを倒さないように台車を動かすことを扱います。皆さんは小学生の頃に手の上でほうきをさかさまにして倒さないようにする遊びをしたことがあると思います。それとほぼ同じことを強化学習にさせるための環境です。CartPole環境についてマルコフ決定過程に則り、状態、行動、報酬、初期分布について説明していきます。状態遷移確率は物理演算に従うため説明は省略します。まず、CartPole環境から得られる状態情報は、カートの位置、カートの速度、ポールの角度、ポールの速度の4つを格納した配列です。その情報を受け取って、強化学習アルゴリズムは0もしくは1の行動を出力します。0はカートを左に、1はカートを右に移動させる行動情報です。少しでも長く棒を立てていてほしいので、報酬は各ステップごとに+1が与えられます。初期分布は、-0.05から0.05の一様分布となっています。
ポールが立っている状態を保てるように、もしポールが右に倒れ掛かったら、右へ動かしてポールが立つような方向に力が働くようにします。同様に、左に倒れ掛かったら、左へ動かしてポールが立つような方向に力が働くようにします。
次にエピソードの終了条件について説明します。終了条件は3つあり、1つ目と2つ目は、ポールの角度、カートの位置が閾値を超えたとき、即ち倒れたと判断されたときに終了することを表しています。3つ目は、十分に学習が進みエピソードが終了できなくなることを防ぐために設けられているもので、最大ステップ数に到達したときに終了することを表しています。

コードの実行
ここまでの内容を踏まえて、コードを実行してみようと思います。Google Colaboratoryを開きましょう。
注意点ですが、ここで紹介しているコードは、現時点ではエラーなく実行できるものです。今後、Google Colaboratoryやライブラリがアップデートされて実行できなくなる可能性があります。その場合は、コメント欄で教えていただけましたら、可能な限り対応いたします。
まず、以下の3行を実行して、必要なものをインストールします。1行目はStable Baselines3と呼ばれる強化学習ライブラリのインストールです。2行目はおまじないです。3行目は、私が作成したythonモジュールで、Colaboratory上でエピソードの実行結果を簡単に可視化したり保存したりするものです。
%%bash
pip install stable-baselines3
pip install pyglet==1.5.27
git clone https://github.com/aakmsk/gymvideo.git問題なくインストールできたら、以下のコードを実行してインポートします。1行目のgymは、OpenAIが提供している強化学習インターフェースで、CartPoleを含むあらゆる強化学習環境を使用するときに使用するものです。2行目は、Stable Baselines3からDQNのモデルをインポートしています。今回は、DQNの詳細な説明は省いていますが、行動価値をTD学習する方策オフ型の強化学習手法であるQ学習に深層学習を取り入れたもので、Deep Q Networkとよばれ、DQNはその略称になります。3行目のGymVideoはColabでエピソードの実行結果を可視化したり保存したりするためのGym形式のラッパーです。
import gym
from stable_baselines3 import DQN
from gymvideo.scripts.gymvideo import GymVideo次に以下のコードを実行して、CartPole環境のインスタンス化と学習を実行します。stable baselines3はとても簡単に強化学習が試せるので便利ですね。まずは10000万ステップだけ学習してみましょう。学習回数が少ないと失敗することを確認します。
env = gym.make("CartPole-v1")
env = GymVideo(env)
total_timesteps = 10000 # 1万ステップ
model = DQN("MlpPolicy", env, verbose=1)
model.learn(total_timesteps=total_timesteps)学習結果を用いて1エピソード実行してみます。
env.execute_one_episode(model)
env.save_video()結果は以下のようになります。
12度以上傾いたためエピソードが終了しています。このことから、まだ学習が足りないことが分かります。
では10ステップの学習を行うとどうでしょうか。total_timesteps = 100000に変更して再実行してみましょう。結果は以下の通りです。
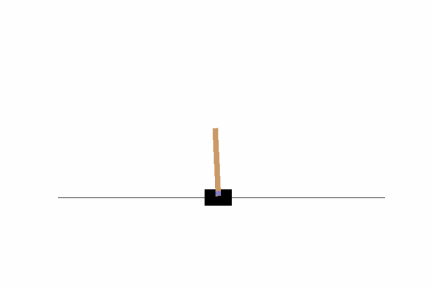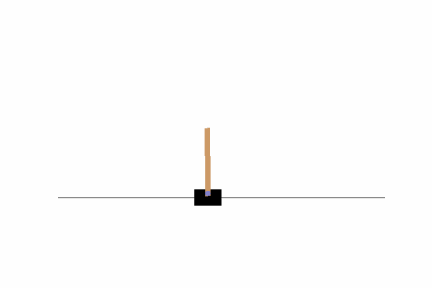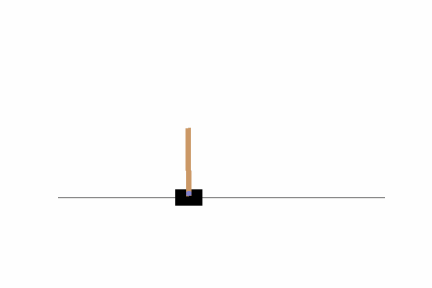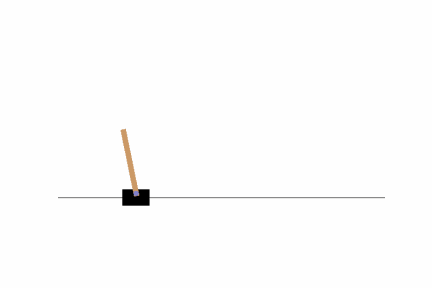
そこそこバランスがとれるよう学習ができていますね。ただし、画面の隅の方では上手くバランスが取れないようなので、100万ステップに学習ステップ数を増やしてみましょう。結果はどうでしょうか?私の場合は以下のようになりました。
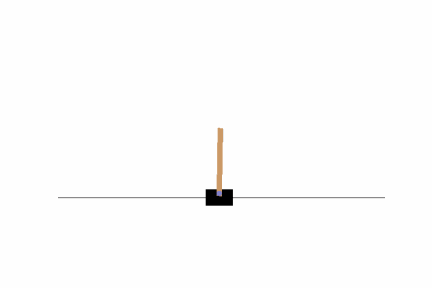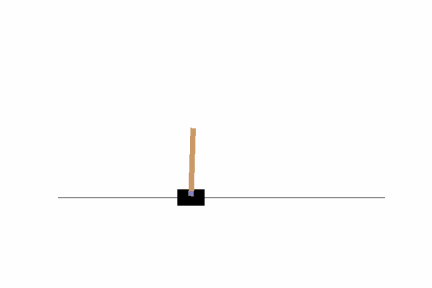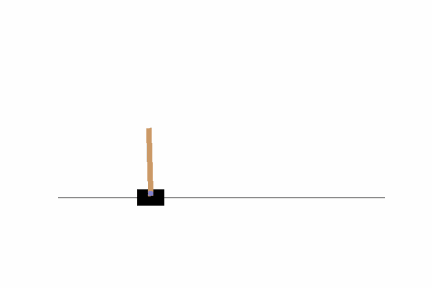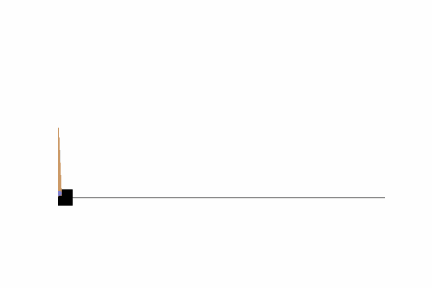
やはり、端に弱いようですが、10万ステップよりは安定している印象を受けます。これより精度を上げるには、学習ステップ数を増やすことも考えられますが、その他に、報酬設計や方策ネットワークの変更などをする必要があるかもしれません。
MlpPolicyについて
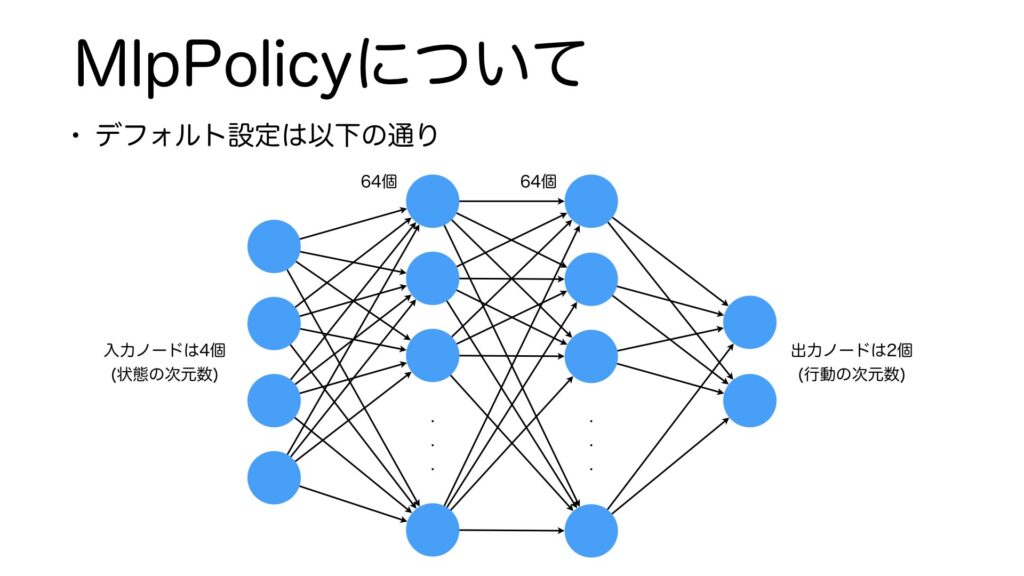
先ほど、Stable Baselines3のDQNの引数に、MlpPolicyというものがありました。この説明をしていなかったので、簡単に説明をして今回のまとめに入りたいと思います。MlpPolicyとはStable Baselines3が提供する方策ネットワークで、自分で設計しなくても自動で方策ネットワークを生成してくれる便利なクラスです。今回の場合は、以下のようなネットワークが自動で生成されます。入力には4個のノード、中間層は2層でそれぞれ64個のノード、出力層は2個のノードからなっています。入力層と出力層は学習環境に依存しますが、中間層は自分で設計することも可能です。今回は使用しませんでしたが、MlpPolicyの他にも様々な便利な方策ネットワークがあるので、気になったら調べてみてください。
まとめ
さいごに簡単にまとめたいと思います。今回の、Weekly RL with codeでは、強化学習の基礎知識として環境とエージェント、そしてマルコフ決定過程について説明をしました。このマルコフ決定過程に沿って、CartPole環境について要点を説明し、Stable Baselines3のDQNで学習をしてみました。学習ステップ数が増えると、精度が向上してより長い時間、安定して棒を立てられることを説明しました。
動画は以上になります。今後も、週1でWeekly RL with codeを公開していきますので、ぜひチャンネル登録をよろしくお願いいたします。
最後までご視聴ありがとうございました。それでは次の動画でお会いしましょう。