
皆さん、こんにちは!
この記事では「ヒューマノイドロボット時代の幕開けか!? Figure 01の衝撃 その仕組みや今後の動向について考察」というテーマでお話しします。この内容は動画でも配信していますので、興味があればぜひご覧ください。
留意事項
まず初めに、留意事項についてお伝えします。この動画では、Figure 01のデモ動画に使用されているであろう技術についての解説や考察を行っています。ただし、これらの解説や考察は公開されている情報に基づいていますが、基本的には私個人の見解に基づくものです。したがって、Figure 01が実際にこの動画で紹介されている方法で実現されているという保証はありません。あくまで一つの意見として参考にしていただければ幸いです。
Figure 01のデモ動画
それではまず、本動画で取り上げるFigure 01のデモ動画について簡単にご説明します。このデモ動画は、人間とロボットが同じ空間におり、人間がロボットにタスクを音声で依頼するところから始まります。ロボットは音声で応答しながらタスクを実行します。実行するタスクには、リンゴを人に手渡す、ゴミをカゴに入れる、コップとトレーを元の位置に戻すなどがあり、これらの動作が非常にスムーズに行われました。また、このロボットはこれまでの行動履歴を記憶しており、自身がどのような動作を行ってきたか、それが現在十分であるかどうかの判断もできる点が、これまでの人型ロボットと大きく異なり、大きな反響を呼びました。このような機能はどのような仕組みによって実現されているのでしょうか。この記事では、その仕組みを解き明かしていきます。
Figure 01の想定される仕組みの概要
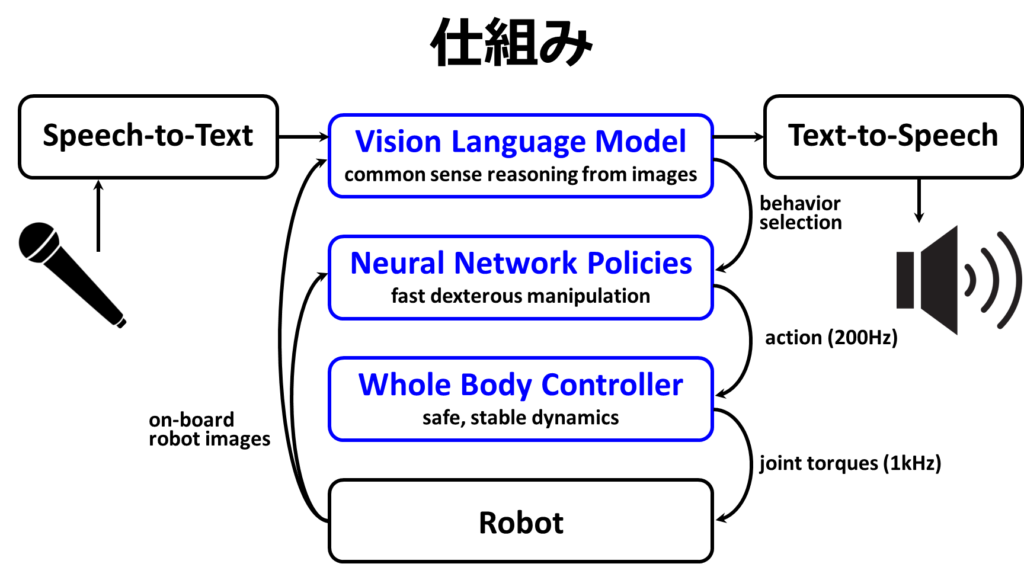
それでは、その仕組みについて説明します。ロボットはマイクを通じて人間の音声を受け取り、その音声情報をSpeech-to-Text技術を用いてテキスト情報に変換します。この変換されたテキスト情報は、Vision Language Model(VLM)に入力されます。VLMは、画像と言語を処理することが可能な機械学習モデルであり、ここから返答としてのテキストを生成することができます。生成されたテキストはText-to-Speechによって音声に変換され、スピーカーから再生されます。また、VLMはNeural Network PoliciesからどのPolicy(方策)を採用するか、つまりどの行動を選択するかを決定します。選択された方針は、約200HzでWhole Body Controllerに行動情報を送信し、Whole Body Controllerからは約1kHzで関節トルク情報をロボットに送信します。さらに、ロボットからは画像情報がNeural Network PoliciesとVLMに送られます。このような階層構造によって動作が実現されています。これまでの説明は既に公開されている情報に基づいていますが、これだけでは仕組みの説明としては不十分だと感じる方もいるでしょう。そのため、ここからは私の考察を交えつつ、VLMがどのようにNeural Network Policyを選択するかに焦点を当てて、さらに詳しく説明していきます。
Vision Language Model(VLM)
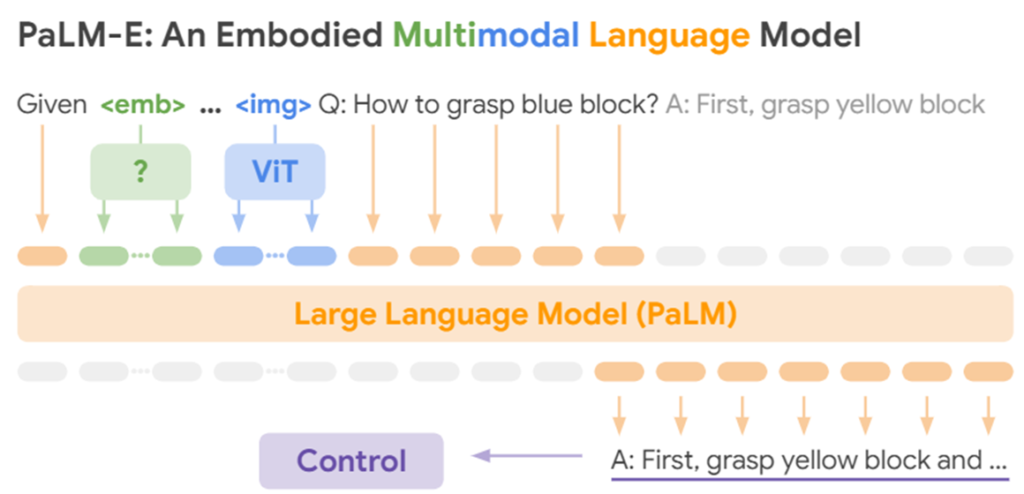
Vision Language Model(VLM)について説明します。VLMは、画像と言語という異なるモードを統合的に扱うことが可能な機械学習モデルです。最近では、画像を入力として与え、その内容を踏まえて言語で対話を行うモデルや、言語を入力して画像を生成するモデルなど、この種の機械学習モデルが増えています。皆さんの中には、ChatGPTのGPT-4のような、この分野で特に性能の高い代表的なモデルを利用している方もいるかもしれません。以下で紹介するのは、PaLM-Eと呼ばれるVLMのアーキテクチャです。簡単に説明すると、このモデルは画像情報をVision Transformer(ViT)を使って言語情報に変換し、その後、その言語情報を言語の入力と融合させてLLM(Large Language Model)で処理を行います。VLMには他にもさまざまな手法が存在するため、興味がある方はぜひ調べてみてください。
Neural Network Policies
まず、「Policy」とは何かから始めましょう。Policyは、強化学習の中で重要な役割を果たす概念です。強化学習とは、環境とエージェントが行動と報酬に関する情報をやりとりする形で定義され、この枠組みの中で、エージェントがどのように意思決定をし、その意思決定プロセスをどのように学習するかが、強化学習の重要トピックとなります。この意思決定のメカニズムを「Policy」と呼びます。日本語では、「方策」や「方針」と訳されることがあります。そして、「Neural Network Policy」とは、ニューラルネットワークを使った方策を指します。つまり、エージェントが状態や観測を受け取り、それに基づいて行動を出力するニューラルネットワークのことを言います。
さて、PolicyとNeural Network Policyについて理解いただけたと思いますが、なぜこのタイトルに「Policies」と複数形で記載されているのか、その理由について次に説明します。

オプションフレームワーク
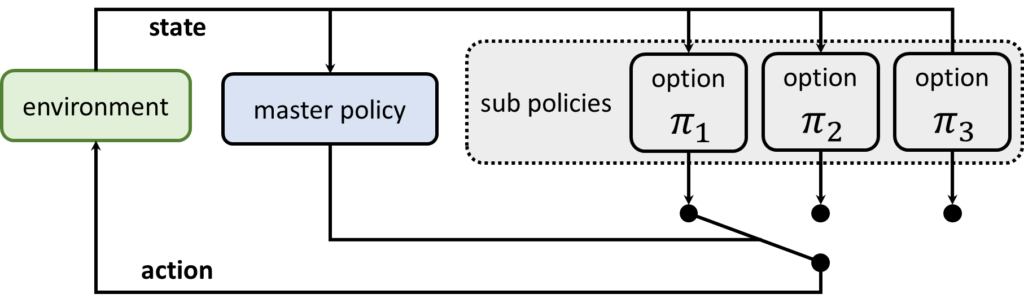
その理由として、Figure 01のデモ動画では、オプションフレームワークが採用されていると考えられるためです。オプションフレームワークとは、階層的強化学習フレームワークの一種です。階層的強化学習では、方策がマスター方策と複数のサブ方策で構成されています。サブ方策は、特定のタスクに特化した動作を習得するためのものです。マスター方策は、メタ的な情報を獲得し、状況に応じて適切なサブ方策を選択します。以下の図で「オプション」と記載されたものは、一つのNeural Network Policyとして機能し、タスクごとに分けられていることから、これらがサブ方策を形成していると考えられます。そのため、「Neural Network Policies」と複数形で記載されているのは、このような背景があると推測されます。
Neural Network Visuomotor Transformer Policies
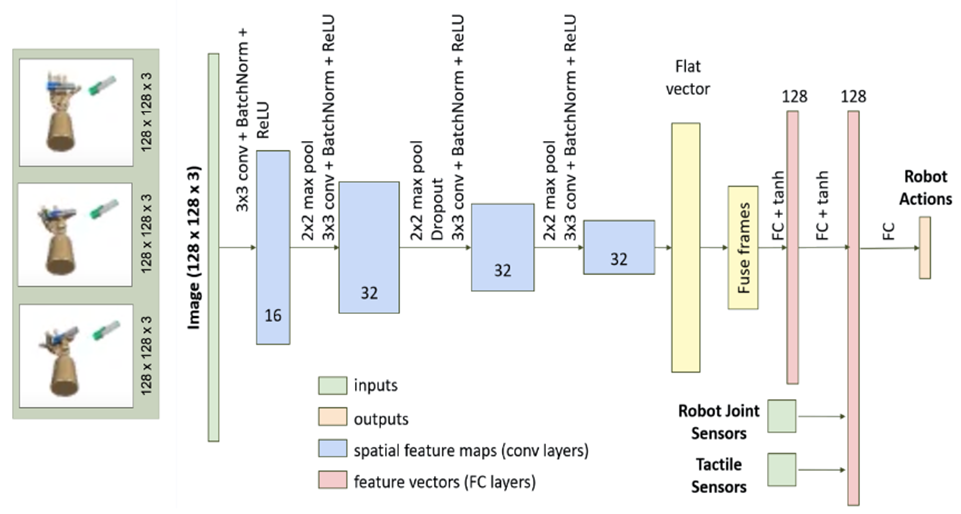
さて、Neural Network Policyについては、Neural Network Visuomotor Transformer Policyが使用されているという情報があります。このNeural Network Visuomotor Transformer Policyとは一体何でしょうか?まずは、Deep Visuomotor Policyについて確認してみましょう。Deep Visuomotor Policyは、視覚特徴(Vision)と運動特徴(Motor)を統合し、行動を生成する方策ネットワークです。ここで紹介する具体的なDeep Visuomotor Policyでは、画像情報のほかに、ロボットのセンサー情報や関節情報などが統合され、ロボットの次の行動を生成するための学習が行われます。このアプローチにより、複雑な動作の習得が可能となり、画像情報を利用することで、単に動作を模倣するだけでなく、特定の画像に基づいた条件付けられた動作の習得も可能です。例えば、「蓋を開ける動作」をする際には、適切な状態で蓋を持ってから開けなければならないなど、その動作を行うための条件を画像情報を通して設定することができます。
そして、Neural Network Visuomotor Transformer Policyは、Deep Visuomotor Policyのニューラルネットワーク部分にTransformerを使用したバージョンです。Transformerは、ChatGPTのような大規模言語モデルで使用される代表的なアーキテクチャであり、自己注意機構により非常に高い性能を発揮し、系列情報の学習に適しています。このため、単純なニューラルネットワークよりもより複雑なタスクの学習が可能になることが期待されます。Figure 01のデモ動画では、このNeural Network Visuomotor Transformer Policyが採用されています。また、このポリシーをタスクごとに用意するため、「Neural Network Visuomotor Transformer Policies」という複数形での表記になるのでしょう
さて、このNeural Network Visuomotor Transformer Policyは、模倣学習で一般的に使用されます。模倣学習のためには、エキスパートデータが必要になります。次では、エキスパートデータの収集について説明します。
エキスパートデータの収集
模倣学習を行うには、「エキスパートデータ」と呼ばれるデータが必要です。エキスパートデータとは、模倣したい特定の動作を具体的に示すデータのことを指します。例えば、4脚ロボットの歩行を模倣学習で習得する場合、犬や猫の関節にトラッカーを取り付けて動きを記録し、そのデータを学習のために用います。また、人間が他の人にリンゴを手渡す動作のような場合、その具体的な動作を多数収集したデータがエキスパートデータとなります。このエキスパートデータは、遠隔操作用コントローラーや関節や指のトラッキングを利用して収集されることが一般的です。最近では、Vision Proのような技術により、複雑な遠隔操作コントローラーを必要としない研究も進んでいます。Figure 01においては、おそらく遠隔操作コントローラーを使用してエキスパートデータを収集したと考えられます。具体的には、手のひらが机と平行になる状態をタスクの開始と終了の姿勢として設定し、遠隔操作によりタスクごとのエキスパートデータを収集したと推測されます。開始時と終了時の手の姿勢を統一することにより、タスクの再配列が可能となり、データの再利用性が向上します。

VLMによる振舞い選択
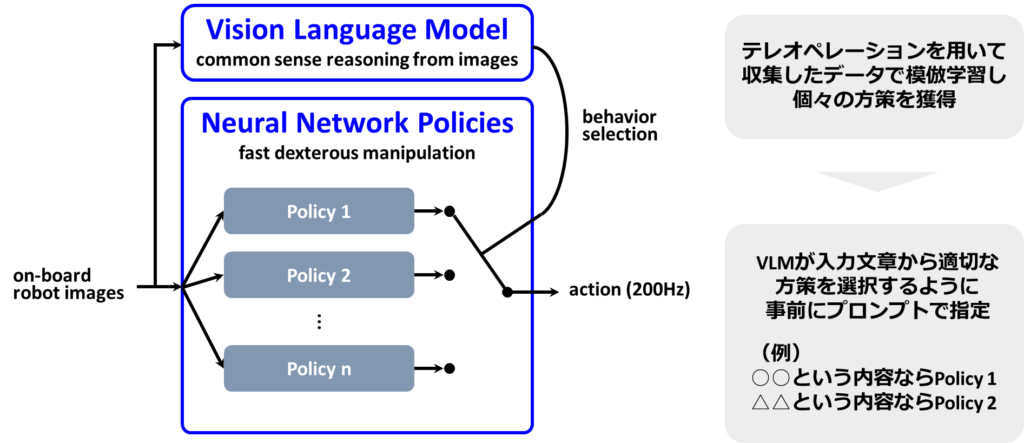
では、このようなNeural Network Policyのセットから、VLMを用いてどのように行動を選択するのでしょうか。ここでは、VLMによる行動選択のメカニズムを説明します。下図は、先に説明したオプションフレームワークの方策形状そのものです。マスター方策はVLMが担い、サブ方策はNeural Network Policiesとなっています。方策全体の入力は、ロボットから取得された画像情報であり、出力は200Hzの行動情報です。
※公開情報されている図に基づくとNeural Network Policiesへの入力にロボットの関節角度情報は含まれていないような感じに描かれていますが、実際には関節角度情報も入力されていると思います。
各ポリシーはテレオペレーションを用いて収集したデータで模倣学習されたものと考えられます。そして、これらのポリシーはVLMによって選択されます。この選択プロセスは非常にシンプルで、VLMでは事前に定めたプロンプトに従って行われます。例えば、特定の内容を受け取った場合にはポリシー1を、別の内容を受け取った場合にはポリシー2を選択するように番号を出力する仕組みです。この方法により、VLMがText-to-Speechに送るテキスト情報に加えて、選択すべきNeural Network Policyの番号インデックスも出力するようにします。そのインデックスに基づき、選択されたポリシーを実行すればよいわけです。タスクが終了するまで、つまり手のひらがスタート地点からタスクを開始し、最初と同じ位置に戻るまで、そのポリシーを実行します。
Figure 01のデモ動画で見られたリンゴを取って手渡す動作について補足します。VLMはリンゴの存在を理解していますが、リンゴが具体的にどこにあるのかまでは把握していないと考えられます。リンゴを手渡すために実行されるポリシーが、リンゴの位置を理解し、アームを適切に制御しているというわけです。
Whole Body Controller
次に、Whole Body Controllerについて簡単に説明します。Whole Body Controllerは、ロボットの全身を統合的に制御し、最適な動作計画を作成するシステムです。以下は一般的な説明ですが、主な機能について紹介します。
- 動作計画: 全身の状態を考慮して、効率的な動きを計画するプロセスです。
- 逆運動学: 目的地点や目標姿勢を達成するために必要な関節角度を計算します。この計算では、ロボットのリンク長や可動範囲などの物理的特性を考慮に入れます。
- ダイナミクスの計算: 動作に伴う力やトルクを予測し、動きを最適化するプロセスです。
- 軌道計画: 障害物を避けながら目的地点までの最適な経路を計画します。
- センサーフィードバックの統合: 環境からのリアルタイムフィードバックに基づいて、動作計画を調整します。
これらの機能をWhole Body Controllerで実現しており、1kHzで関節トルク情報をロボットに送信しています。
今後の研究の方向性
今後の研究の方向性について、私の考えを述べます。
① サブ方策の増やし方
オプションフレームワークに基づいた手法を継続する場合、サブ方策をどのように増やしていくかが課題となります。サブ方策の増加は、実行可能なタスクの数を増やすことを意味しますが、これにはタスクごとに大量のエキスパートデータの収集が必要になります。この課題に対しては、主に二つの解決策が考えられます。一つ目は、多数のロボットを用いて大規模なデータ収集を行うこと、二つ目は、人間の動作映像から模倣学習を可能にすることです。後者が実現可能になれば、大規模言語モデルがテキスト情報から会話を学習するように、動画から動作を自動的に学習することができ、革命的な進歩が期待されます。最近、NVIDIAが発表したGROOTは、人の動きを観察して模倣する仕組みを備えているとのことです。したがって、研究の方向性としては、エキスパートデータを直接収集するのではなく、動作映像から間接的にデータを収集し学習する方法へと進化していくと考えられます。
② オプションフレームワークの課題
また、オプションフレームワーク自体の課題にも触れたいと思います。オプションフレームワークでは、基本的に1つのタスクにつき1つのサブ方策が必要とされ、これはマスター方策とは異なる性質を持っています。VLMのようなマスター方策は、1つのモデルで多様な汎用的な意思決定が可能です。しかし、サブ方策は特定のタスクごとに準備される必要がありますから、オプションフレームワークを使用するとサブ方策の数が膨大になる可能性があります。これにより、マスター方策が適切なサブ方策を選択できるかが問題となります。今後の研究の方向性としては、サブ方策の融合による数の削減、あるいはオプションフレームワーク以外の手法、例えばVision Language Action(VLA)モデルの探求といった方向が考えられます。
まとめ
最後に、本内容をまとめます。Figure 01のデモ動画が短期間で開発されたと推測されることから、本動画で解説したような仕組みと類似の方法で実現している可能性が高いと考えられます。オプションフレームワークを使用した手法には、解決すべき多くの研究課題が存在します。そのため、多様なタスクを実行できるロボットの開発には、まだ数年かかるかもしれません。ただし、オプションフレームワーク以外の手法によって大きなブレイクスルーが生じる可能性もあり、その場合、今年中や来年にも、あらゆるタスクを実行できるロボットが登場する可能性があります。いずれにせよ、このデモ動画は未来がすぐそこまで来ていることを示唆しており、非常に意義深いものです。今後もAIやロボット技術の最新動向に注目していくことが重要でしょう。
最後までお読みいただき、ありがとうございました。