
Transformer[1]は、自然言語処理の領域を超えて、画像処理などの分野でも高いパフォーマンスを達成することができる、という大きな特徴を持っています。一般的に、Transformerがこのような高いパフォーマンスを出せる理由は、内部に採用されているAttention[1]という仕組みが優れているからだと考えられています。ところが、この記事で取り上げるMetaFormer[2]では、Attentionの性能よりも、Transformerの抽象的な設計が優れているからこそ高いパフォーマンスを達成できる、という主張がされています。本記事では、その主張を簡潔に紹介します。
Transformer
概要
Transformerは、2017年にGoogleがAttention is All You Need[1]という論文でニューラル機械翻訳として提案した手法です。ニューラル機械翻訳というのはニューラルネットワークを用いて翻訳タスクを実現しようとする自然言語処理タスクの1つで、従来一般的に使用されてきた再帰的ニューラルネットワーク(Recurrent Neural Network: RNN)の欠点を解決する形で登場しました。その課題というのは、位置依存性に弱い点と、並列化による計算の高速化ができないというものです。特に、性能面で言うと位置依存性に弱いというのは、「マクロな情報は捉えられる一方で、ミクロな情報は捉えられない」ということになるため、正確な機械翻訳を実現するうえで大きな課題となっていました。それを解決することができる手法として提案されたTransformerは本当に大きなブレイクスルーだと思います。
それ以降、BERT[3]やGPT[4]などTransformerを用いたモデルが大きな成果を上げています。話題のChatGPTもTransformerを用いて構築されたGPT-3.5やGPT-4[5]が使用されています。
※
Transformerは自然言語処理分野で登場したアーキテクチャですが、画像や音声など、他の分野でも高性能を達成できることが明らかになり、現在は多種多様な分野で使用されています。
Transformerについては以下の記事で要点を分かりやすく解説していますので、詳細を知りたい方はぜひそちらもご参照ください。

アーキテクチャ
Transformerとは、下図(左)に記載したようにエンコーダデコーダの構造をしており、機能単位でみると、Multi-Head AttentionとFeed Forwardを1セットとしたブロック構造(=Transformer Block)を複数スタックしたものとなっています。
Multi-Head Attentionについて詳しく知りたい方は以下の記事を参考にしていただければと思います。

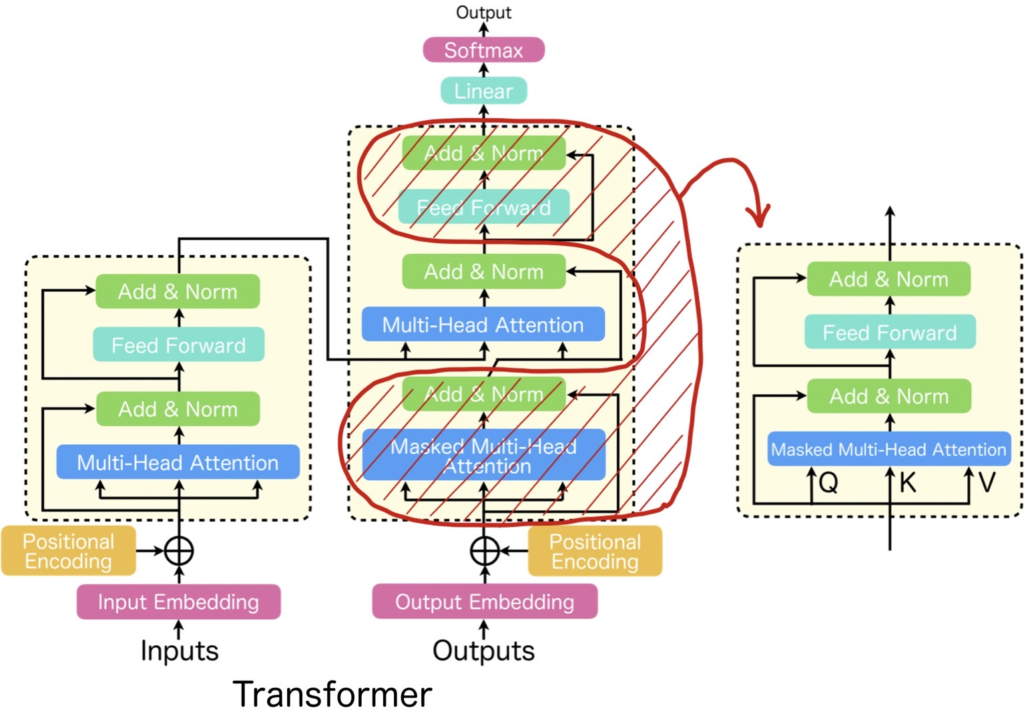
現在、主流となっているTransformer Blockは上に示した初代Transformerで使用されたものとは少し異なっていて、下図のように、Normalizationが先に来るような構造になっています。
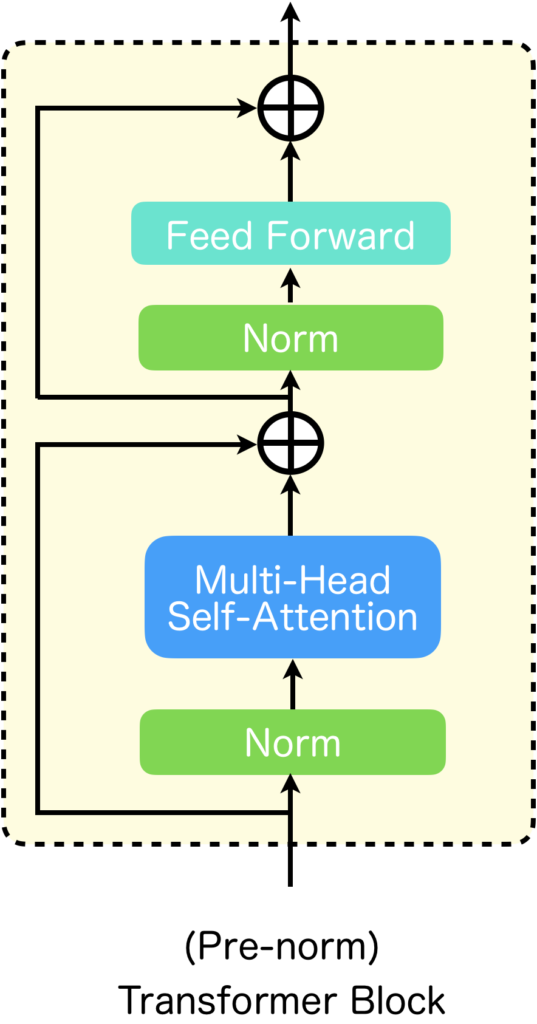
MetaFormerでは、このTransformer Blockに焦点を当てています。
MetaFormer
概要
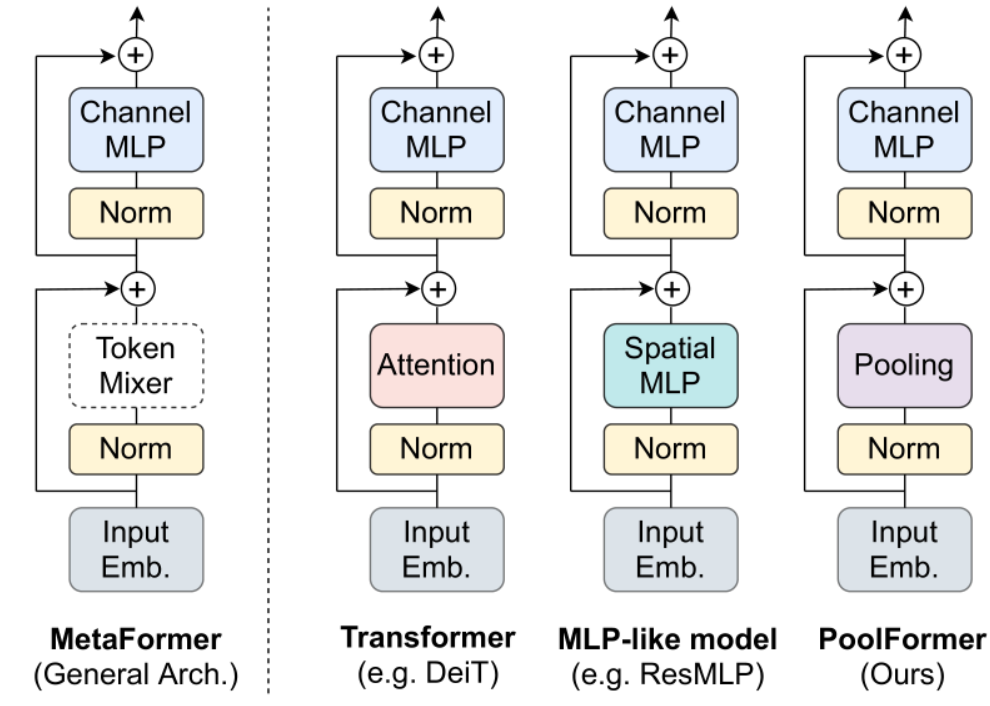
それでは、MetaFormerについて説明します。MetaFormerの理解は決して難しくなく、直感的に把握できるものです。以下の図は、MetaFormerの論文から引用したものです。左から二つ目のイラストが、Transformer Blockを示しています。Transformer系の研究ではよく、Attention部分を別の機構に変更してみるという試みが行われます。MetaFormerの論文では、Attention部分をPoolingに置き換えたPoolFormerを構築し、それが高い性能を発揮することを示すことを通じて、AttentionであったりPoolingであったりする部分が、トークンを混合して処理する機構、すなわちトークンミキサーであれば、良いのではないかというメタ的なモデル、MetaFormerを提案しています(左の図)。
MetaFormerは、特定のモデルを指すものではなく、Transformer Blockの抽象的な構造に大きな意義があり、その構造を表す名前だと考えてください。
トークンミキサー
MetaFormerでは、Attentionを「注意機構」としてではなく、「トークンミキサー」として解釈しています。つまり、これは複数のトークンを跨いで情報を処理できるツールの一つであるという見方です。
この視点で考えると、計算の過程で特定の注意が必要かどうかは、実はあまり重要ではないのかもしれません。MLPであれPoolingであれ、それらがトークンをミックスして情報を処理することができるように設計されているならば、それらは十分に機能するというのがMetaFormerの考え方です。
MetaFormerの成果とNLPとの関係
MetaFormerの成果
論文[2]では、MetaFormerの優位性について画像処理タスクでのみ証明しており、その成果はNLP(自然言語処理)タスクにまで適用できるかはまだ確認されていません(MetaFormerの論文ではNLPタスクへの応用は今後の課題として触れている)。しかし、Transformerの抽象的なモデルアーキテクチャに対して、画像処理タスクにおける優位性を示すとともに名前を命名したところは、NLPなど他のタスクにも影響を及ぼす大きな可能性を持っていると考えます。
MetaFormerとNLP
自然言語処理(NLP)におけるTransformerのスケーリングに関しては、計算コストが主なボトルネックとなっています。この原因は、Transformerが利用している内積注意にあると考えられており、その解決策として様々な手法が提案されています。これらの研究の大半は、Transformerの抽象的な構造を保持したまま、内積注意を改良あるいは置き換える方向性を持っています。私の認識では、MetaFormerを引用している論文の大部分は、画像処理タスクを対象としたもので、NLP分野でMetaFormerを引用した論文はそれほど多く見られません。しかし、現在の研究トレンドを鑑みると、NLPにおけるTransformerの研究においても、MetaFormerの考え方が有効に機能していると思われます。
イメージしやすいように具体例を紹介します。紹介するのはRWKV[6]です。RWKVは、TransformerとRNNの利点を組み合わせたモデルとなっていて、学習時は並列化により従来のTransformrerと同じように学習ができ、推論時はRNNの特性を利用して、小さな計算コストでテキストを生成することを可能にしています。以下の図には、Transformer BlockとRWKV Blockを両方示しています。RWKV Blockでは、Transformer BlockのFeed Forward部分は再帰構造を持つChannel Mixingに、Multi-Head Attentionは再帰構造を持つTime Mixingに置き換えられています。このようにブロックを構成する要素について処理レベルで見ると幾つか置き換えられていることが分かります。ですが、要素の処理内容をブラックボックスとして考えて、それらの接続関係など抽象的な視点で見ると、MetaFormerで示されたようなTransformerの抽象的な構造を保っているのがよく分かると思います。
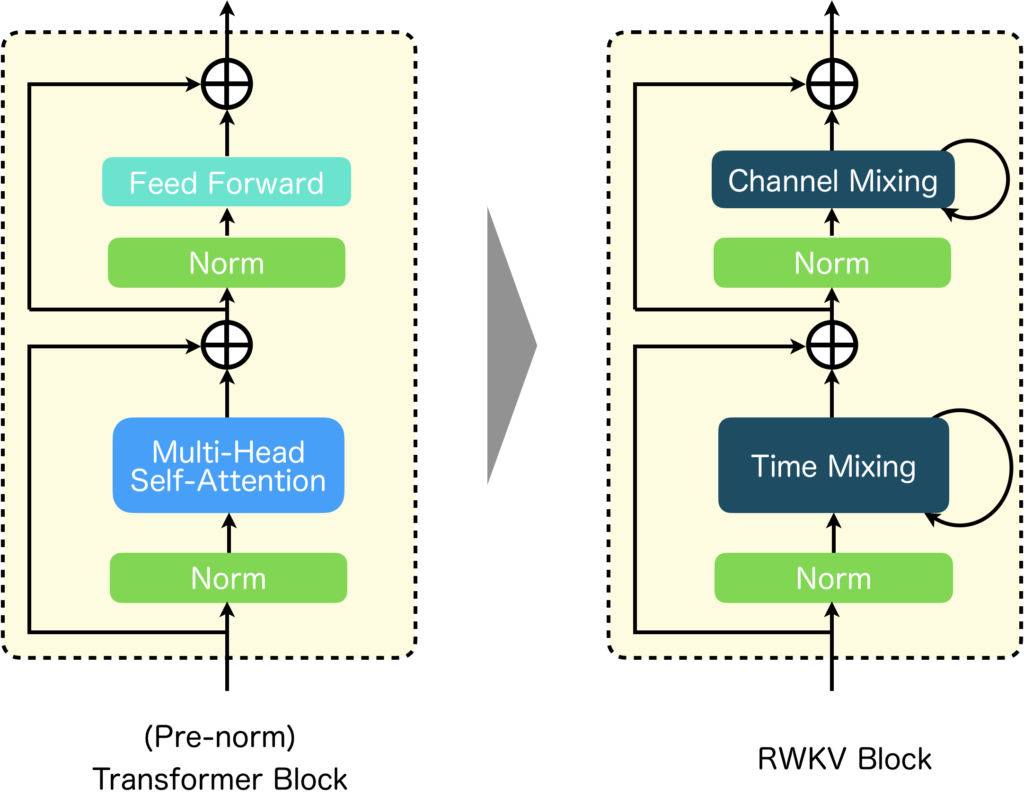
RWKV以外にも多くのモデルで、同様の傾向がみられるので、興味がありましたら調べてみてください。
まとめ
本記事では、Transformerが画像処理タスクにおいて高い性能を達成できるのは、Attentionの優れた性能よりも、Transformer Blockの抽象的な構造が優れているからではないのか、という考えから生まれたMetaFormerについて紹介しました。 MetaFormerの考え方がNLPにも適用できるかはまだ確認されていませんが、現在の研究動向を見る限り、NLPにおけるTransformerでもMetaFormerの考え方が適用可能であると推測できます。今後も、Transformer Blockの抽象的な構造を維持しつつ、計算コストを削減し、性能を向上させる手法が多数登場すると予想されます。 この視点を持ちつつ、Transformer系の最新論文を追っていければと考えています。
参考文献
[1] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin, "Attention is all you need," in Proc. NeurIPS, 2017.
[2] Weihao Yu, Mi Luo, Pan Zhou, Chenyang Si, Yichen Zhou, Xinchao Wang, Jiashi Feng, and Shuicheng Yan. "MetaFormer is Actually What You Need for Vision," in Proc. CVPR, 2021.
[3] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova, "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding," arXiv, 2018.
[4] Alec Radford and Karthik Narasimhan, "Improving Language Understanding by Generative Pre-Training," 2018.
[5] OpenAI, "GPT-4 Technical Report," arXiv, 2023.
[6] Bo Peng, Eric Alcaide, Quentin Anthony, Alon Albalak, Samuel Arcadinho, Huanqi Cao, Xin Cheng, Michael Chung, Matteo Grella, Kranthi Kiran GV, Xuzheng He, Haowen Hou, Przemyslaw Kazienko, Jan Kocon, Jiaming Kong, Bartlomiej Koptyra, Hayden Lau, Krishna Sri Ipsit Mantri, Ferdinand Mom, Atsushi Saito, Xiangru Tang, Bolun Wang, Johan S. Wind, Stansilaw Wozniak, Ruichong Zhang, Zhenyuan Zhang, Qihang Zhao, Peng Zhou, Jian Zhu, and Rui-Jie Zhu, "RWKV: Reinventing RNNs for the Transformer Era," arXiv, 2023.