
はじめに
本記事では、Attention Free Transformer[1]と呼ばれるモデルのアーキテクチャについて解説します。
はじめに大枠を説明します。近年ではTransformer[2]と呼ばれる手法が大きな成果をあげています。Transformerの中心的な仕組みは注意機構[2]であり、その注意機構は内部に内積注意と呼ばれる仕組みを持っています。この内積注意がTransformerの高いパフォーマンスの源であると考えられている一方で、それがTransformerをスケーリングするうえで大きなボトルネックとなっている現状があります。理由は、内積注意とは入力された全てのトークンの組み合わせに対して、内積を計算する全注意と呼ばれる方法を採用しているからです。内積の計算結果は、行列形式で保持され、これを注意行列と呼びます。内積計算の数および注意行列の成分数は、系列長に対して2乗のオーダで増加します。つまり、長い入力系列を扱うには、それなりの計算量とメモリ容量が必須になります。これを解決する方法として、内積注意を近似することて計算コストを軽量化する手法と、内積注意すら使用しない新しい注意機構を実現する手法がとられています。本記事で扱うAttention Free Transformerは、内積注意を使用しないTransformerです。注意機構が無いTransformerであるという誤解を生みそうな名前をしていますが、内積注意(厳密には内積注意を用いたMulti-Head Attention)を使用しないというだけです。Attention Free Transformerは、別の記事で解説するRWKV[3]などのモデルのもととなっており重要な手法です。
概要は以上ですが、このアーキテクチャについて詳しく説明するには、元祖Transformerの内積注意からしっかりと理解する必要があります。そこで、本記事では、内積注意について詳しく説明したうえで、Attention Free Transformerのアーキテクチャについて説明していきます。
内積注意
まずは、元祖の注意機構である内積注意について説明します。
内積注意は、QueryとKey、Valueと呼ばれる3つの入力を受け取ります。そして、QueryとKeyの内積を計算し、(ソフトマックス関数を適用して)注意行列を生成します。この注意行列の各成分を係数とし、Valueを線形結合します。これが内積注意です。よって、出力の系列長はQueryの系列長と同じで、出力のベクトルサイズはValueのベクトルサイズと同じです。
以下に、\(t\)番目出力ベクトルの計算式を示します。
$$\begin{eqnarray}
\text{Attention}(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V})_t &=& \left(\text{softmax}\left(\frac{\boldsymbol{QK}^N}{\sqrt{d}}\right)\boldsymbol{V}\right)_t \\
&=& \frac{\sum_{n=1}^N \text{exp}(\frac{\boldsymbol{q}_t\boldsymbol{k}_n^T}{\sqrt{d}}\boldsymbol{v}_n)}{\sum_{n=1}^N \text{exp}(\frac{\boldsymbol{q}_t\boldsymbol{k}_n^T}{\sqrt{d}})} \in \mathbb{R}^{d}
\end{eqnarray}$$
式中、\(\boldsymbol{Q, K, V}\)は、行ベクトルで表されたトークンベクトルを並べて行列にしたもので、\(\boldsymbol{q}_t\)などのQuery、Key、Valueのそれぞれに対応する小文字はトークンベクトルを表します。また、\(N\)は系列長(一般的には\(T\)を用いるが転置の記号と重なるため\(N\)とした)、\(d\)はKeyのベクトルサイズを表しています。
より詳細な計算のイメージを持っていただくために、以下に計算式をイラストで表したものを載せます。
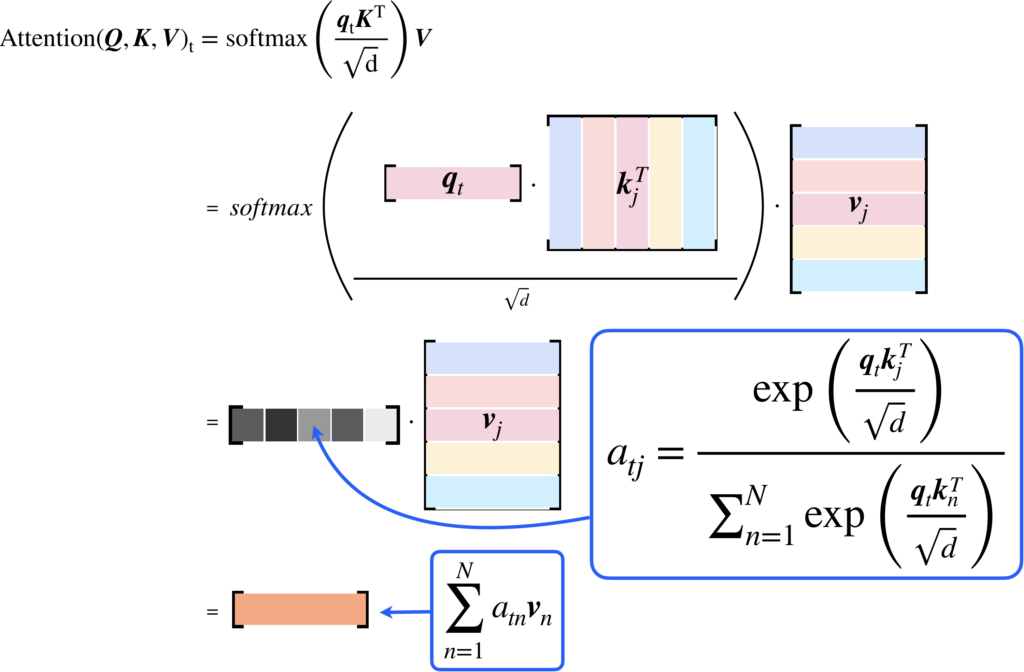
最後の部分のみに注目してもらうと、内積注意が何を計算するものかをイメージしやすいでしょう。まず絶対に理解しておくべき事の1つ目は、出力はValueの重み付き和であることです。2つ目は、その線形結合における係数を決める際に、KeyとValueの内積に基づく注意行列を計算している点です。
そして、この内積を計算するのが物凄く大変なのです。例えば、1万個のトークン列を入力とする場合、注意行列を生成するには、1万×1万=1億の内積計算が必要になり、かつそれを保持するメモリもそれだけ必要になります。1つの成分を保存するに32bit(=4バイト)使用する場合、1億個の成分を持つ行列の保存に必要な容量は約400MBになります。それに、1層のみで済む話ではありませんから、何十層もスタックすることを考えると、必要な計算コストやメモリーサイズは恐ろしいほど膨大です。内積注意を軽量化しなければ、Transformerをスケーリングするのが難しいことをご理解いただけるのではないかと思います。
ちなみに、今回紹介する、Attention Free Transformerは、内積注意だけではなく、Multi-Head Attention全体を置き換える手法なので、Multi-Head Attentionについても解説しておきます。Multi-Head Attentionは内積注意(Scaled Dot-Product Attention)を用いて以下のように計算されます。
$$\begin{eqnarray}
\text{MultiHead Attention}(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V}) &=& \text{Concat}(head_1, head_2, \cdots, head_h)\boldsymbol{W_O}\\
\text{where}\ head_i &=& \text{ScaledDotProductAttention}(\boldsymbol{QW^Q}_i, \boldsymbol{KW^K}_i, \boldsymbol{VW^V}_i)
\end{eqnarray}$$
特に難しいことは行っておらず、内積注意のQuery, Key, Valueの各入力の直前に重みを\(\boldsymbol{W^Q}, \boldsymbol{W^K}, \boldsymbol{W^V}\)とする線形層を追加したSingle-Head Attentionが、並列に並んでいて、任意のヘッドの出力を\(\rm{head}_i\)とするとき、それらを合体して、重みを\(\boldsymbol{W_O}\)とする線形層に適用しているだけです。要するに、多種多様な特徴を学習できるように並列化したのです。図に描くと以下のような感じです。
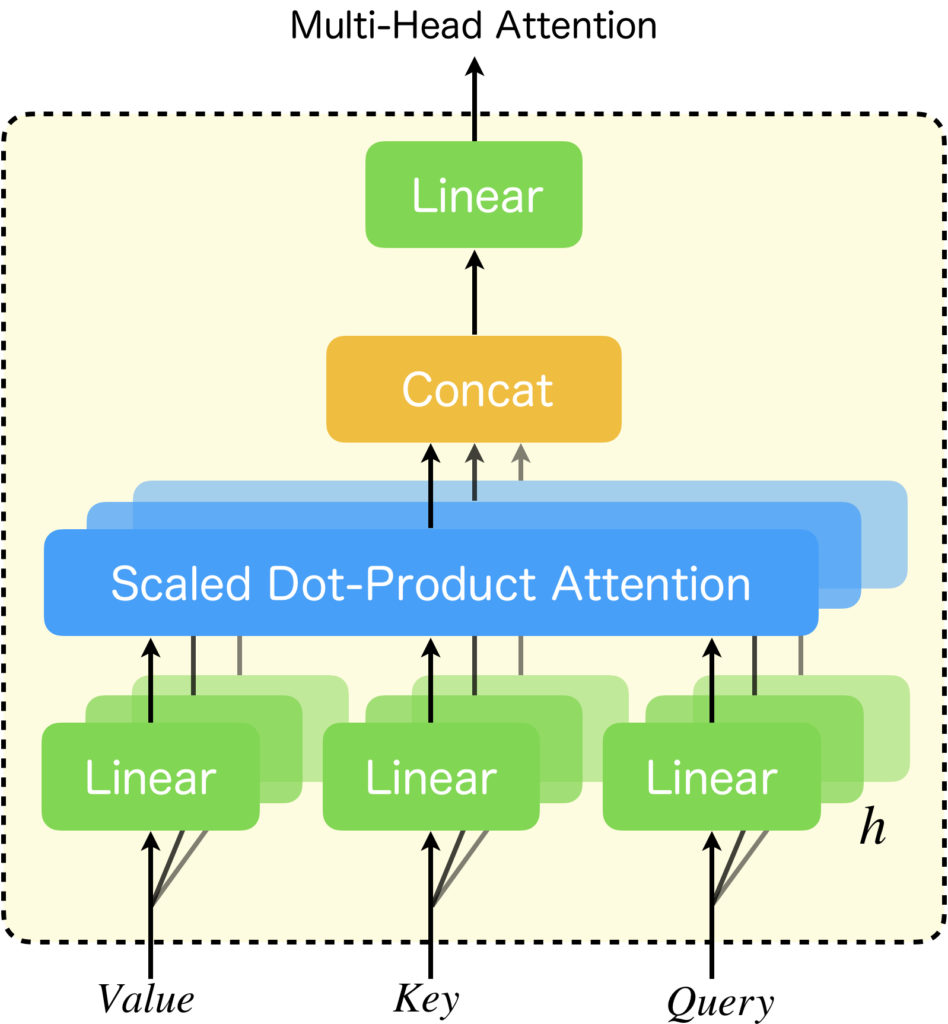
Multi-Head Attentionについて詳しく知りたい方は以下の記事を参考にして下さい。

Attention Free Transformer
Attention Free Transformer(以降、AFT)の論文では、AFTについてTransformerのMulti-Head Attentionの置き換え手法として提案しています。つまり、下図の左側を右側で置き換えるのです。名前にTransformerとついているので、つい、Transformer全体のことを指しているのかと思ってしまいますが、論文に記載の定義からは、あくまでもMulti-Head Attentionの置き換え手法にすぎません。
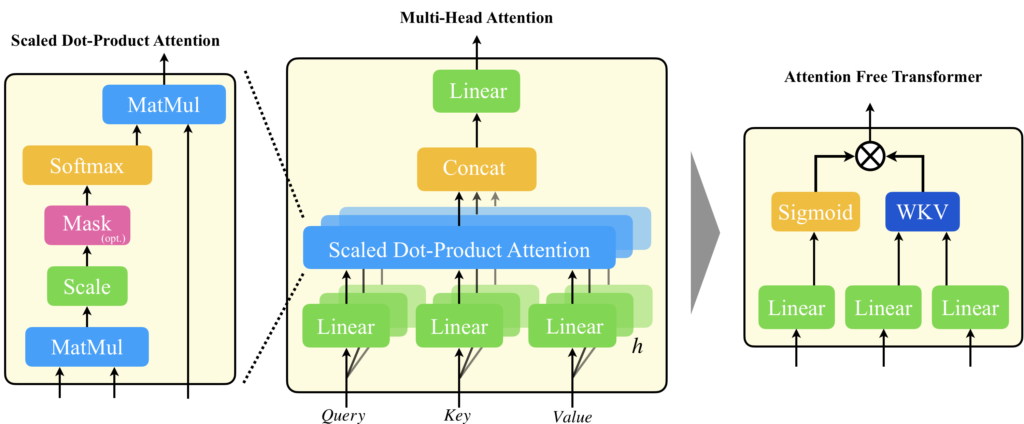
ここでは、一旦、Self-Attention型のAttention Free Transformerを考えていくことにします。
入力を\(\boldsymbol{X}\)、それらを変換するQuery, Key, Valueの線形層の重みを\(\boldsymbol{W^Q}, \boldsymbol{W^K}, \boldsymbol{W^V}\)とするとき、\(\boldsymbol{X}\)は、\( \boldsymbol{Q} = \boldsymbol{XW^Q}\)、\( \boldsymbol{K} = \boldsymbol{XW^K}\)、\(\boldsymbol{V} = \boldsymbol{XW^V}\)に変換されます。そのうえで、以下の関数を適用します。
$$\begin{eqnarray}
Y(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V})_t = \sigma(\boldsymbol{q}_t)\odot\frac{\sum_{i=1}^T \text{exp}(w_{t, i} + \boldsymbol{k}_i)\odot\boldsymbol{v}_i}{\sum_{i=1}^T \text{exp}(w_{t,i} + \boldsymbol{k}_i)}\in \mathbb{R}^{d}
\end{eqnarray}$$
この式は、時刻\(t\)における計算式を表しています。ここで特徴的なのは、新しくパラメータ\(w_{t, i}\)を導入していることです。このパラメータは、\( \boldsymbol{w}\in\mathbb{R}^{T\times T}\)において、時刻\(t\)の\(i\)番目の成分を取り出してきたものです。従来は、QueryとKeyの内積を計算することで\(T\times T\)の注意行列を計算していましたが、内積計算自体をやめてしまう代わりに、位置埋め込みに類似した機構を導入するという考え方です。そして、Queryは、LSTMやGRUなどで見られるようなゲートとして利用されています。
改めて、AFTは以下のような計算式として定義されます。
$$\begin{eqnarray}
\text{AFT}(\boldsymbol{X})_t &=& \sigma(\boldsymbol{q}_t)\odot\frac{\sum_{i=1}^T \text{exp}(w_{t, i} + \boldsymbol{k}_i)\odot\boldsymbol{v}_i}{\sum_{i=1}^T \text{exp}(w_{t,i} + \boldsymbol{k}_i)}\in \mathbb{R}^{d}\\
&& \text{where }\boldsymbol{q}_t = (\boldsymbol{XW^Q})_t, \boldsymbol{k}_t = (\boldsymbol{XW^K})_t, \boldsymbol{v}_t = (\boldsymbol{XW^V})_t
\end{eqnarray}$$
この計算を図で表すと以下のようになります。
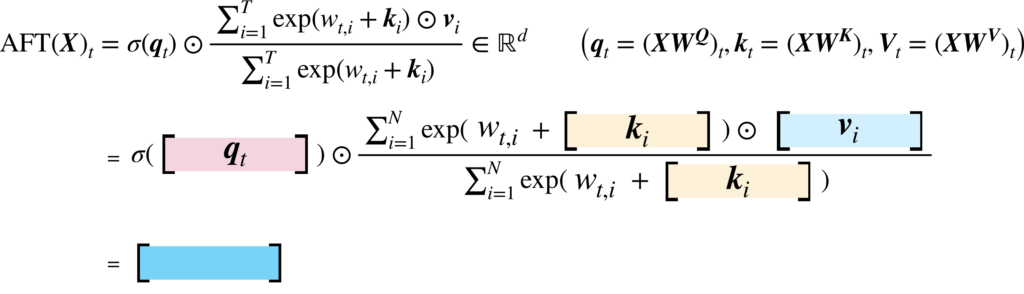
図にしてみたものの、なぜこのような計算式が思いつくのか、という疑問が私には残っていますが、内積計算を無くした代わりに少し複雑な仕組みを導入したんだろうな、という解釈で留めております...
AFTの種類
AFTには幾つかの種類が考えられています。上で紹介したものが基本的な式となり、それをAFT-fullと呼びます。ここで、\(w_{t,i}\)において、窓を持たせ、その範囲外では0にすることで、局所性を持たせたものがあり、それをAFT-local、そもそも重み自体を無くしてシンプルにしたAFT-simple、畳み込みを追加した、AFT-convなどがあります。
興味がありましたら、論文を見てみてください。
さいごに
内容は以上になります。
本記事を通じて、AFTがどのようなアーキテクチャを用いて従来の内積注意を代替しているのかをご理解いただけましたでしょうか?
AFTの内積注意自体を置き換えてしまうというアプローチは、ひょっとしたらTransformerのアーキテクチャについてある程度理解していないと躓いてしまう難しい方法かもしれません(私自身もまだ完全に理解したとは思っていません)。AFTは別の記事で紹介するRWKVのベースとなる手法となっているように、実は重要な仕組みです。とはいえ、重要なのはAFTの細かい計算方法というより、QueryによるゲーティングとWKV(Weighted Key Value)による新しい注意機構の考え方であるように感じます。ですので、最低でもその点をご理解いただければ十分かと思います。
もし興味がありましたら、RWKVの記事も読んでいただけると幸いです。最後までお読みいただきありがとうございました。
参考文献
[1] Shuangfei Zhai, Walter Talbott, Nitish Srivastava, Chen Huang, Hanlin Goh, Ruixiang Zhang, and Josh Susskind, "An Attention Free Transformer," arXiv, 2021.
[2] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin, "Attention is all you need," in Proc. NeurIPS, 2017.
[3] Bo Peng, Eric Alcaide, Quentin Anthony, Alon Albalak, Samuel Arcadinho, Huanqi Cao, Xin Cheng, Michael Chung, Matteo Grella, Kranthi Kiran GV, Xuzheng He, Haowen Hou, Przemyslaw Kazienko, Jan Kocon, Jiaming Kong, Bartlomiej Koptyra, Hayden Lau, Krishna Sri Ipsit Mantri, Ferdinand Mom, Atsushi Saito, Xiangru Tang, Bolun Wang, Johan S. Wind, Stansilaw Wozniak, Ruichong Zhang, Zhenyuan Zhang, Qihang Zhao, Peng Zhou, Jian Zhu, and Rui-Jie Zhu, "RWKV: Reinventing RNNs for the Transformer Era," arXiv, 2023.