
ついにGPT-4が発表されましたね!
それも、既にChatGPT Plusで利用できる状態で。
性能向上は勿論のこと、マルチモーダル化が実現されたため、AIサービスの可能性が一気に広がりそうです。
今回は、そのようなGPT-4について、何が凄いのか解説していきます。
GPT-4が発表されました!
GPT-4とは、OpenAIが公開した新しいAIモデルです。より正確に言うと、LLM+と呼ばれるもので、大規模言語モデル(Large Language Model: LLM)をマルチモーダルにしたものです。これまでChatGPTで使用されていた、GPT-3.5の中身は実質的にGPT-3で、それ以前のGPT-2やGPT-1を含め、これらはテキストのみを扱うシングルモーダルAIでした。しかし、GPT-4ではテキストに加え、画像も扱えるようになりました。このように複数種類のデータ(モダリティ)を扱うことができるAIをマルチモーダルAIと言います。
また、GPT-4は言語能力においてもGPT-3.5よりも遥かに優れています。GPT-4の日本語能力はGPT-3.5の英語能力を凌駕しています。また、高度な知識や専門性の要するテストにおいて、GPT-3.5を遥かに上回る成果を多数出しています。また、嘘をついたり間違った答えを返す可能性が大幅に改善し、GPT-3.5よりも内容の信用性が向上しました。
ChatGPT Plusを契約している方々は既にGPT-4が利用可能になっているようです。現時点では、無料版では使えないようですが、OpenAIの方のあるツイートによると、今後は無料版にも展開されることが予想されますね。
ChatGPT Plus、月額2,400円、「未来」を「先に」試せます。
— シェイン・グウ (@shanegJP) March 14, 2023
まだ使用制限があり、全ての機能(画像など)が出てないですが、「お楽しみはこれから」です。https://t.co/qHUmBrjsIg https://t.co/xLMQCVwWDc
それでも待てない、今すぐにでも無料でGPT-4を試したいという方向けに、後でその方法をご説明します。
GPTとは
まず最初にGPTについて説明します。GPTとは、Generative Pretrained Transformerの頭文字をとったもので、2017年にGoogleが開発したTransformerと呼ばれる機械翻訳モデルのデコーダ部分を使って、言語モデルを学習したものです。言語モデルというのは、言語を単語の出現確率でモデル化したものを言います。一般的なものは、次の単語の生成確率を、これまでの単語列で条件付ける言語モデルです。数式で書くと以下のようになります。
$$L_1(\mathcal{U}) = \sum_i \log P(u_i|u_{i-k},\cdots, u_{i-1};\mathcal{\Theta})$$
$$\mathcal{U} = {u_1, u_2, \cdots, u_n}$$
ここで、\(\Theta\)はニューラルネットワークなどの学習器のパラメータです。\(\mathcal{U}\)は単語列、コーパスです。GPTは、この学習を行い、コーパスに含まれている文章を、前から後ろに向かって正しく単語を予測するように学習することで言語モデルを獲得します。余談ですが、GPTとしばしば対比されるものに、BERTがありますが、これは双方向の情報を用いてマスクされた部分の単語を条件付確率で表して学習するもので、マルク言語モデルとよばれます。
言語モデルの性能を高めるには、関数近似器であるニューラルネットワークのパラメータ数を大きくすることと、コーパスのサイズを大きくすることが必要です。特に前者は、Transformerのスケーリング則と呼ばれ、サイズを大きくすればするほど性能が高くなるとされています。後者については細かいことを言うと、コーパスの質というのも重要ですが。
GPTを開発したOpenAIは、その流れに則り、GPT-2、GPT-3とよりパラメータ数の多い、より多くのデータで学習された言語モデルを開発してきました。このような言語モデルを大規模言語モデル(Large Language Model: LLM)と呼びます。
GPT-3は、96層のTransformer Blockをスタックしたものになっていて、パラメータ数は1750億と言われています。実は、人間のシナプスの数(約100兆個)に比べるとまだまだなので、これだけのパラメータ数で人間に近い知能を言語だけで実現できるのはとても凄いことだと思います。ちなみに、今のニューラルネットのニューロンは平均発火ニューロン、一方で、生体のニューロンはスパイキングニューロンで情報処理が異なるため、単純比較はできないとされています。
GPT-3は、その表現能力の高さ故、テキストのみのやり取りだと、人間かどうかわからないという状況になっており、意識や感情を持っているのではないかと錯覚を覚えてしまいそうなほどです。まさに、哲学的ゾンビです。

GPT-4は更にパラメータ数が増えたとされていますので、獲得された知識量は大幅に増え、以前に増して、人間の応答なのか、AIの応答なのか分からなくなりそうです。OpenAIは、GPT-4の仕組みやパラメータ数については公開しなかったため、何とも言えないですが、確実にGPT-3よりはパラメータ数は多いでしょう。公開される以前は、パラメータ数が100兆になるのではと噂されていたので、もしこれが本当ならば、人間の脳内のシナプス数に匹敵する量になるのですが、GPT-4の性能からして、それはありえないですね。後で考察しますが、5000億~1兆の間くらいではないでしょうか。
GPTをチャットサービスにしたのがChatGPTですが、言語モデルを獲得しただけのGPTでは人間の好む出力はしてくれないので、人手による評価から強化学習を行う手法であるRLHF(Reinforcement Learning from Human Feedback)を採り入れて、モデルを微調整したうえでサービスに適用されています。GPT-4でもRLHFは使用されています。

GPT-4の仕組みを考えてみる
言語モデルと画像を組み合わせる領域は、Vision&Languageと呼ばれていて、数年ほど前からホットな研究分野です。代表的なところで言うと、OpenAIが開発したCLIP(Contrastive Language-Image Pre-Training)で、これは言語特徴と画像特徴の特徴空間を近づけてあげることで、写真の中に映っているものと、対応する単語を関係付ける仕組みです。代表的な使用例に、Stable Diffusionがあります。Stable Diffusionは文字入力から画像を生成することができる手法です。その他、ロボットのモーションと言語を結びつけることも可能で、CLIPは現在のマルチモーダルAIにおいて重要な基礎を築いています。
マルチモーダルな言語モデルに、ついこの前公開されたPaLM-E[2]があります。これは、ViTとPaLM[3]を合体させたもので、GPT-4と同様に画像と言語を扱うことができます。そして手順を出力し、ロボットを制御することが可能です。論文では、身体化言語モデル(Embodied Language Models)と呼んでいます。PaLM-Eは以下のような構造をしていて、トークンの中に画像をViTで埋め込んだものを入力しているので、GPT-4も類似した方法でマルチモーダルにしている可能性があります。
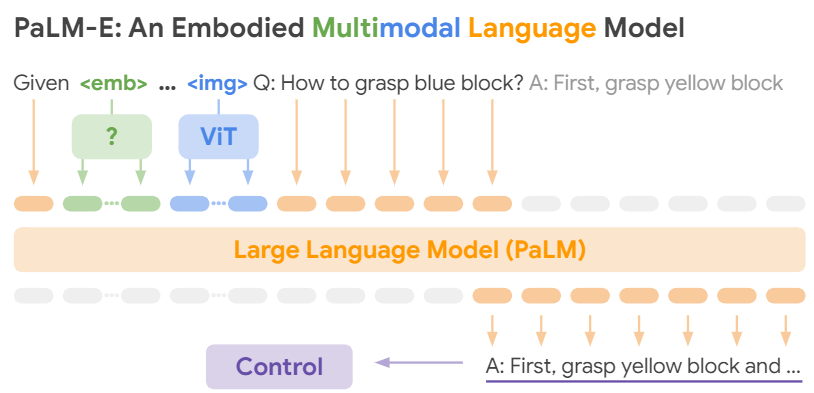
ここまで色々紹介しておいて恐縮ですが、後で示すようにGPT-4のVinsion&Language能力は半端ないので、上記よりも画期的なフュージョンをしている可能性があります。
次に、パラメータ数を考えてみたいと思います。まず、代表的な大規模言語モデルのパラメータ数を見てみましょう。
| LLM | param_size(Billion) |
|---|---|
| GPT-1 | 0.117 |
| GPT-2 | 1.5 |
| Chinchilla | 70 |
| Flamingo | 80 |
| LaMDA | 137 |
| GPT-3 | 175 |
| BLOOM | 176 |
| Gopher | 280 |
| PaLM | 540 |
棒グラフにすると以下のようになります。
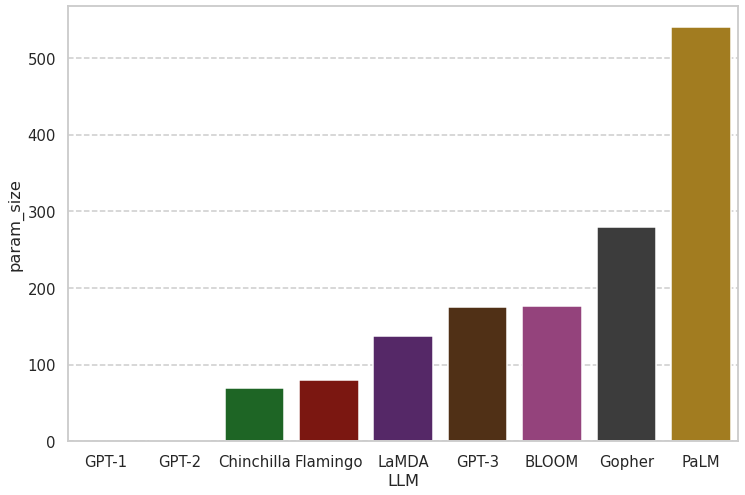
ChatGPTで、あれだけ凄いと言われたGPT-3は、パラメータサイズは大きいことは確かですが、そこまで騒ぐほど大規模かと言われると微妙で、上には上があります。Googleが開発したPaLMは5000億パラメータを超えています。GPT-4は今回、幾つかのタスクでPaLMを凌駕したらしいので、最低でも5000億パラメータはあると予想されます。
以上が、GPT-4のアーキテクチャやパラメータス数の予測になります。いつか、OpenAIからアーキテクチャやパラメータ数などの詳細情報が公開されるといいですね。
GPT-4の凄さ
OpenAIは、GPT-4 Technical Report[4]を公開しているので、その中で興味深いところを抜粋して紹介します。
テストの成績が向上
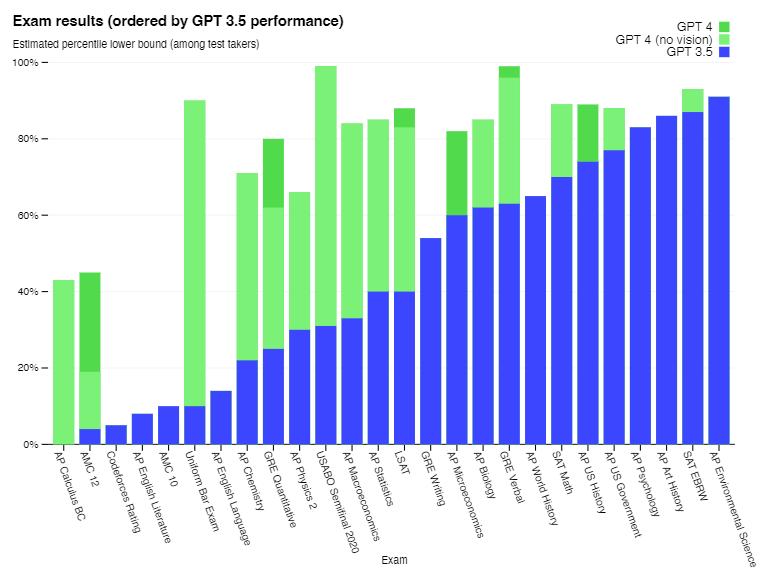
下のグラフは、各種テストの成績を表しています。青色が、GPT-3.5の結果で、その順番にソートされています。GPT-4の結果を見ると、GPT-3.5では低かったテストでも高い精度を達成できていることが分かります。特に、米国の司法試験(Uniform Bar Exam)の結果の違いは大きく、GPT-3.5では10%程度しかなかった一方で、GPT-4では90%に達するほどです。
言語理解能力が向上
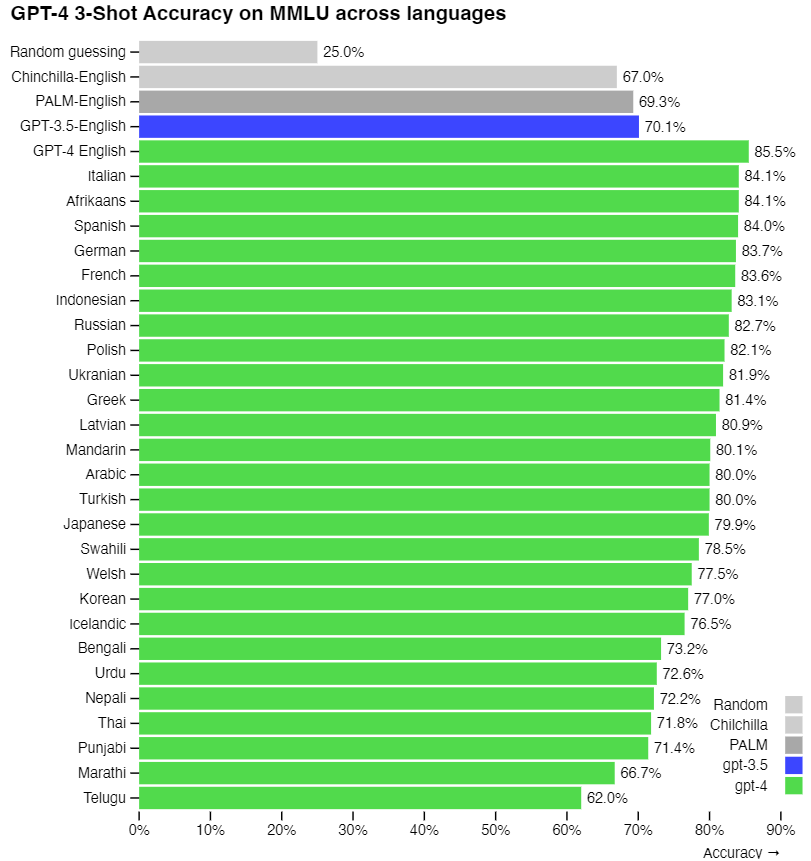
マルチタスク言語理解(Multi-task Language Understanding: MMLU)ベンチマークを用いて、3ショットの正解率をグラフ化したものです。
多くの言語において、GPT-3.5を凌駕する正解率を達成しています。もちろん、日本語もです。GPT-3.5を用いたChatGPTでは、日本語で質問するよりも英語で質問した方が正確な答えが返ってくると言われていたので、多くの方が英語で対話していたと思いますが、とうとう、GPT-4の日本語の理解力はGPT-3.5の英語の理解力を超えました。
信頼性が向上
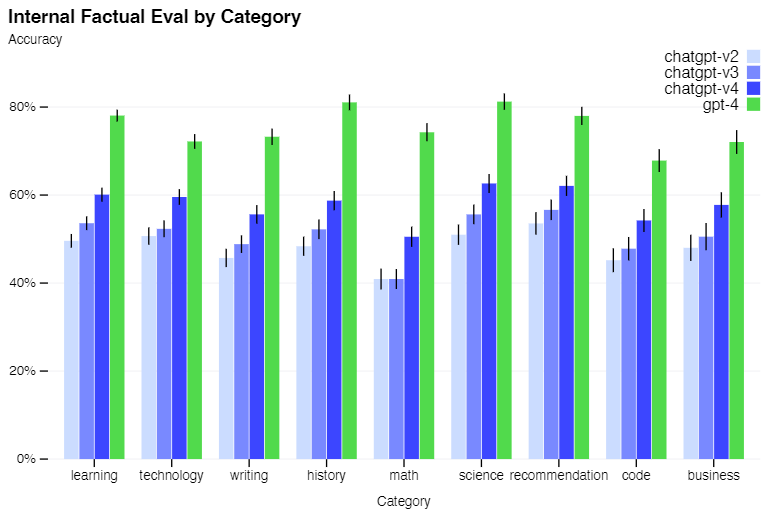
ChatGPTが登場したときに、嘘をつく問題、即ち応答の信頼性が大きな問題とされていました。GPT-4では、かなり改善されているようです。以下のグラフを見る限り、概ね8割程度は信頼していいのではと考えられます。むしろ、従来のGPT-3.5ベースのChatGPTの信頼性はこんなに低かったのですね。
RLHFによる精度が向上
GPT-4でも、GPT-3.5と同様に人間によるランク付けに基づく強化学習であるRLHFが行われています。RLHFについては、以下の記事で詳しく説明しているので、気になりましたら以下の記事もご参照ください。
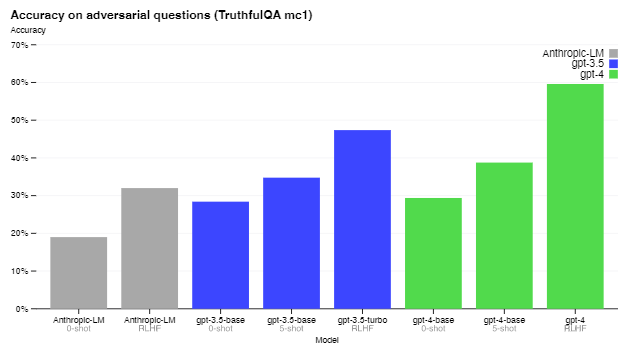
ここでは、RLHFがGPT-4の出力の正確性にどのくらい寄与しているかを紹介します。以下のグラフは、TruthfulQA[5]と呼ばれるベンチマークを用いて評価したものです。TruthfulQAとは、2022年に発表されたばかりの新しいベンチマークで、質問に対する答えが正しいかどうかを測るものです。TruthfulQAタスクは幾つか種類がありますが、以下のグラフはMC1に対する結果です。MC1とは、質問が与えられて、その答えの候補が複数用意されているときに、正しい答えを選択するというタスクです。グラフを見ると、GPT-4ではRLHFの伸びがGPT3.5に比べて大きいです。むしろ、0-shotの場合は、GPT-3.5もGPT-4も大差がないのは意外です。とはいえ、人間は90%を超えることができるのに、GPT-4であっても60%程度なのですね。
画像を含むプロンプトの例
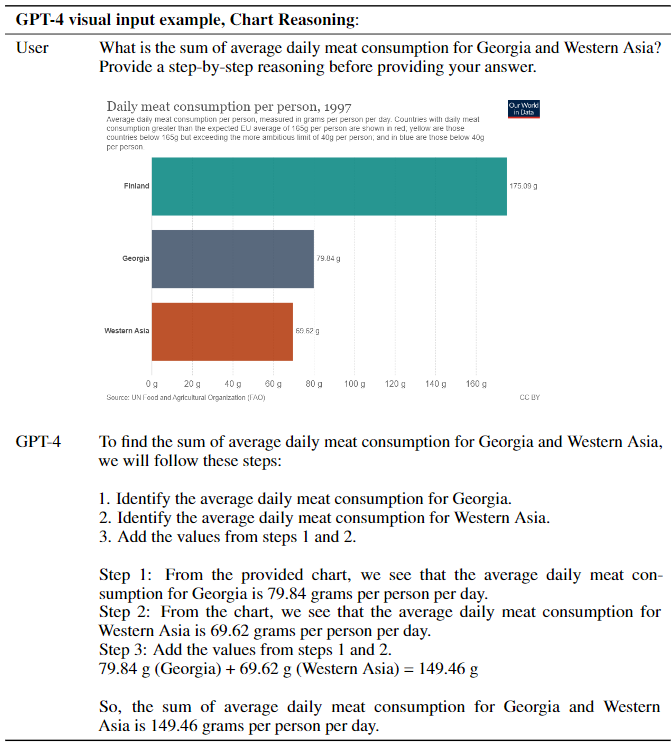
以下は、図に記載されたチャートから質問に従って情報を読み取り答えを出す例です。質問内容は、ジョージアと西アジアの1日の平均肉消費量の合計を、いきなり答えを出すことはせず段階的な理由付けをして答えてください、というものです。チャートには、ジョージアや西アジア以外に、フィンランドの情報も入っているので、適切なグラフを認識する必要があるのと、グラフの右に記載されている数値を認識する必要があります。それでも、正しく処理することができているようです。
次に、より難しい問題を画像を見せて解かせる例です。これは本当に凄いですね。問題Ⅰ.1.aが画像中のどこを示すのか判定し、何が問われているかを考慮して、解くことができるというのは、本当に凄いことだと思います。

次に、画像で論文を入力して、要約することもできるようです。

全てを紹介するのは避けますが、興味がありましたら、GPT-4 Technical Reportを読んでみてください。
これらからVision&Languageの中でもGPT-4は何が凄いのか私なりに考えてみました。
まず1つ目としては、画像内に記載されている文字を的確に認識し、文章として処理できている点です。従来は、画像からテキスト領域を抽出し、文字や単語に変換し、どの様な並びか考慮して処理する必要がありました。しかし、GPT-4では、恐らくこのような泥臭い方法はとっていないでしょう。
2つ目としては、画像と文字の関係が的確に結びついている点です。これは、先に紹介したCLIPでも言えることですが、それを高度に抽象化されたレベルから、個々の文字画像など細かなレベルに至るまで、あらゆる抽象度で的確にプロンプトのテキストなどと結びついているところが凄いです。
3つ目としては、少し2つ目に記載した内容に関連しますが、単一の抽象度や観点だけでなく、多様な抽象度や観点でとらえることができる点です。
これは、どうやって実現しているのか気になって仕方がありません。アーキテクチャを公開して欲しいですね。
無料でGPT-4を試す方法
長らくお待たせしました。先ほど、GPT-4は既にChatGPT Plusで利用可能であることを説明しました。ここでは、GPT-4を無料で使う方法を説明します。そんな方法があるのか?と思われると思いますが、実はあります。その方法とはBing AIを使うということです。ChatGPTを知っている方であれば、Bing AIについて知っている方が多いと思いますが、どうやら、Bing AIの中で動いているAIはGPT-4のようなのです。これは、Microsoft Bing Blogsで公開された記事に記載されていた内容なで信頼できる情報でしょう。
Bing AIでは画像に対応していません。現時点では、ChatGPT Plusも画像に対応していないので、Bing AIに話しかけるのもありかもしれませんね。Google検索では画像検索が可能なように、Bing AIでも将来的には画像が扱えるようになる可能性が高いでしょう。今後が楽しみです。
さいごに
最後になりますが、GPT-4は凄いと言ってばかりでは良くないとという点について私なりの考えを述べたいと思います。
皆さんは、DeepLをご存じですよね?とても優秀な翻訳アプリですよね。私は、DeepLが登場したばかりの頃から使用していますが、最近、あることに気が付きました。それは、英語を見ると反射的にDeepLを使用していることです。DeepLにより英語をあまり読む必要がなくなったというのは、英語が苦手な人にとってはとても革命的なことですが、DeepLの登場により、ほぼ英語を読まなくなってしまったことから、自分自身の英語力が大きく低下していると感じるのです。これが、GPT-4の登場により、思考や創造性などの領域にも及び始めるのではないかと懸念しています。AI研究者として、GPT-4のような高性能なAIの登場は嬉しく思いますが、上手に使用しないと、私たちはGPT-4が無いと生きていけなくなってしまいます。もし、そのような世の中でAIサービスが急遽停止したら、世界はどうなってしまいうのでしょうか?
AIは人類をダメにするものではなく、人類の成長のためにあるものだと思います。今後、GPT-4よりも凄いAIが登場することが想定されますが、AIと人間はどうかかわっていくべきなのか、今のうちから考えておかなければならないのではないかと思います。
最後までお読みいただきありがとうございました。
参考文献
[1] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever, "Learning Transferable Visual Models From Natural Language Supervision," in Proc. ICML, 2021.
[2] Danny Driess, Fei Xia, Mehdi S. M. Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, Wenlong Huang, Yevgen Chebotar, Pierre Sermanet, Daniel Duckworth, Sergey Levine, Vincent Vanhoucke, Karol Hausman, Marc Toussaint, Klaus Greff, Andy Zeng, Igor Mordatch, and Pete Florence, "PaLM-E: An Embodied Multimodal Language Model," arXiv, 2023.
[3] Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Ben Hutchinson, Reiner Pope, James Bradbury, Jacob Austin, Michael Isard, Guy Gur-Ari, Pengcheng Yin, Toju Duke, Anselm Levskaya, Sanjay Ghemawat, Sunipa Dev, Henryk Michalewski, Xavier Garcia, Vedant Misra, Kevin Robinson, Liam Fedus, Denny Zhou, Daphne Ippolito, David Luan, Hyeontaek Lim, Barret Zoph, Alexander Spiridonov, Ryan Sepassi, David Dohan, Shivani Agrawal, Mark Omernick, Andrew M. Dai, Thanumalayan Sankaranarayana Pillai, Marie Pellat, Aitor Lewkowycz, Erica Moreira, Rewon Child, Oleksandr Polozov, Katherine Lee, Zongwei Zhou, Xuezhi Wang, Brennan Saeta, Mark Diaz, Orhan Firat, Michele Catasta, Jason Wei, Kathy Meier-Hellstern, Douglas Eck, Jeff Dean, Slav Petrov, and Noah Fiedel, "PaLM: Scaling Language Modeling with Pathways," arXiv, 2022.
[4] OpenAI (2023).
[5] Stephanie Lin, Jacob Hilton, and Owain Evans, "TruthfulQA: Measuring How Models Mimic Human Falsehoods," in Proc. ACL, 2022.