
皆さんこんにちは。近年、画像生成AIやテキスト生成AIなどの多数の生成AIが注目を浴びています。そんなか、2022年の末から2023年の初めにかけて多くの世間を驚かせたテキスト生成AIであるChatGPTはまだ記憶に新しいでしょう。本記事では、そんなChatGPTの技術の元となっているGPTの元祖、GPT-1について解説していきます。
GPT-1の概要
GPT-1とは、OpenAIが2018年に公開した大規模言語モデル(LLM)です。Googleが2017年に発表したTransformerと呼ばれる機械学習モデルのデコーダ部分をベースにしたモデルで、BookCorpusと呼ばれる大規模なコーパスで事前学習されました。Transformerはエンコーダデコーダの形状をしており、その生成部分に該当するデコーダを事前学習しているため、Generative Pretrained Transformerと呼ばれています。GPTは、この頭文字をとったものです。以降、GPT-2、GPT-3など多くのモデルが登場しており、初代GPTはGPT-1と呼ばれます。GPT-1のパラメータ数は嘗ての言語モデルに比べて膨大で約1.17億個もあります。本記事では扱いませんが、これ以降に登場したGPT-2は15億、GPT-3は1750億もパラメータを持っており、GPT-1を皮切りに言語モデルの大規模化が進みました。
Transformerとは
先に説明した通り、GPT-1はTransformerと呼ばれるモデルのデコーダ部分を用いています。Transformerとは、下図(左)に記載したようにエンコーダデコーダの構造をしており、機能単位でみると、Multi-Head AttentionとFeed Forwardを1セットとしたブロック構造(=Transformer Block)を複数スタックしたものとなっています。Transformerにおいて重要な働きをするMulti-Head Attentionはエンコーダで使われる場合とデコーダで使われる場合で機能が若干異なり、デコーダにおいては先読みを防止するためにMask機能が付与されます。Mask機能が付与されたMulti-Head AttentionをMasked Multi-Head Attentionと呼びます。GPT-1ではTransformerのデコーダ側、即ち、Masked Multi-Head AttentionとFFN(赤の斜線部分)を抽出したブロック(以降、Decoder型のTransformer Blockと呼ぶ)を用います。
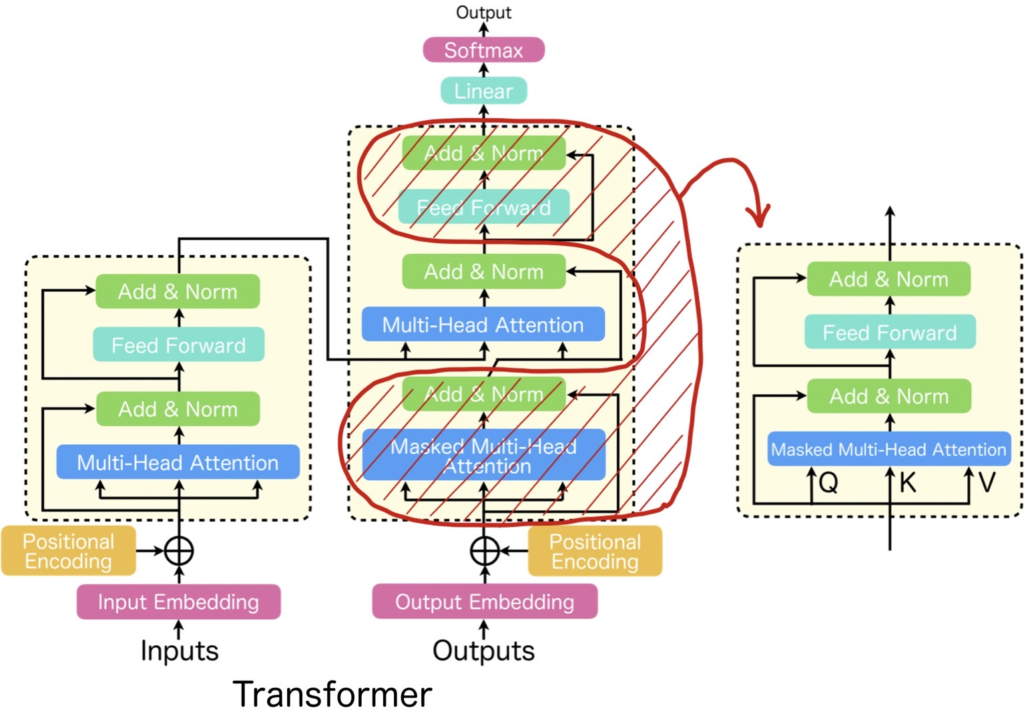
Transformerについては、以下の記事で詳しく説明していますので、気になりましたら読んでいただければと思います。

Multi-Head Attentionについては、以下で詳しく解説していますので、気になりましたら読んでいただければと思います。

GPT-1のアーキテクチャ
GPT-1は、埋め込み層、Positional Encoding、Decoder型のTransformer Blockを12層、出力層で構成されています。順番に説明します。まず、埋め込み層は、onehot形式で与えられた単語ベクトルを、低次のベクトル空間に写像する層です。Word2Vecなどが有名で、分散表現と呼ばれることがあります。Positional Encodingとは位置固有のベクトルが並んだ行列で、Transformerが系列中の位置を考慮して処理することを可能にするために使われます。Transformerの原論文ではsinとcosによる位置エンコーディングが使われましたがGPT-1では学習に基づいて決定されます。Decoder型のTransformer Blockは、既に説明した通り、Masked Multi-Head AttentionとFFNから構成される処理単位のブロックです。出力層は事前学習とファインチューニングでは異なり、事前学習ではDecoder型のTransformer Blockからの出力を単語に変換する層(=埋め込み層の逆)が、ファインチューニングではタスク固有の出力層(クラス分類層など)が使われます。事前学習の時に使われる出力層は、埋め込み層と重み共有をしていて、埋め込み層の重みを転置した行列を掛け合わせsoftmaxを適用するだけになります。
以下に、GPT-1の構造を示します。後でGPT-1の重みの数を数えるので、重み行列とそのサイズも記載しました。重み行列については後で説明するので、ここでは説明を割愛します。
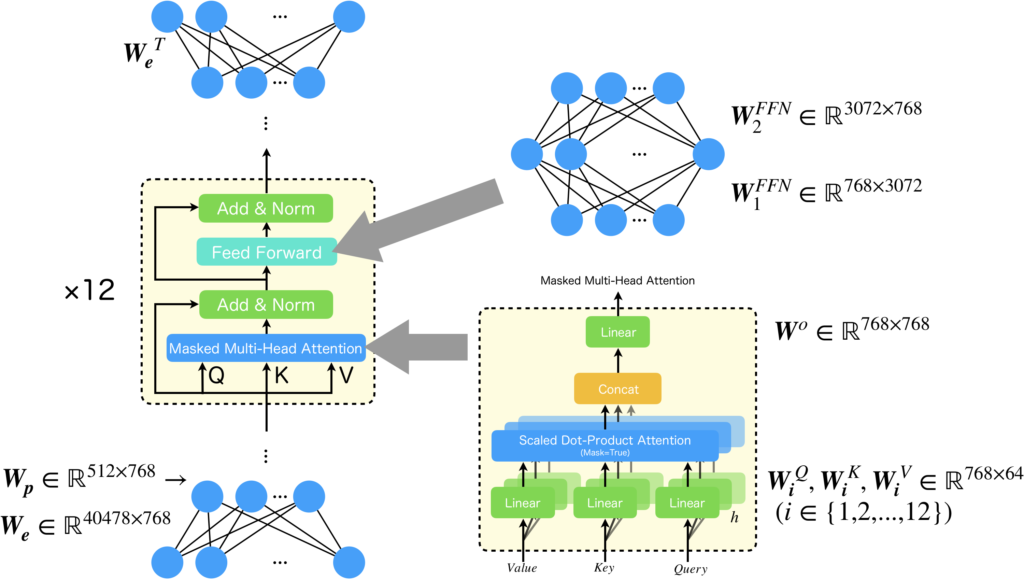
パッと見た感じ、Transformer Blockは12層しかなく、深層ではありません(Multi-Head Attentionの中に2層、FNNは2層として勘定すればx12で48層ではある)し、とても単純な構造をしていると感じると思います。果たしてどこに1.17億ものパラメータがあるのでしょうか?そういった疑問に答えるべく、次でパラメータ数を数えてみます。
GPT-1のパラメータ数の導出
GPT-1のパラメータ数は以下の式で導出することが可能です。
$$
\text{パラメータ数} = \text{埋め込み層のパラメータ数} + 位置エンコーディングのパラメータ数 + (\text{Transformer Blockのパラメータ数}) × 12
$$
計算を始める前に学習パラメータとなる重み行列を明確に定める必要があります。以下のように重みパラメータを定めました。
| \(\boldsymbol{W_e}\in\mathbb{R}^{40478\times 768}\) | 埋め込み層の重み (事前学習で使う出力層と重み共有) |
・40478は学習に使用したBookCorpusの語彙数 |
| \(\boldsymbol{W_p}\in\mathbb{R}^{512\times 768}\) | 位置エンコーディングの重み |
GPT-1の入力シーケンス長は512なので行数は512 |
| \(\boldsymbol{W_i^Q}\in\mathbb{R}^{768\times 64}(\forall i\in[1,12])\) |
Scaled Dot-Product Attetion直前の線形層 | ・64は768をヘッド数(=12)で除算した数でTransformerの原論文によれば計算コストを下げるための工夫 |
| \(\boldsymbol{W_i^K}\in\mathbb{R}^{768\times 64}(\forall i\in[1,12])\) | 同上 | 同上 |
| \(\boldsymbol{W_i^V}\in\mathbb{R}^{768\times 64}(\forall i\in[1,12])\) | 同上 | 同上 |
| \(\boldsymbol{W^o}\in\mathbb{R}^{768\times 768}\) | Concat直後の線形層 | Concatされたベクトルサイズは768で、出力ベクトルはMulti-Head Attentionの入力と同じ |
| \(\boldsymbol{W_1^{FFN}}\in\mathbb{R}^{768\times 3072}\) | FFNの中間層の重み | 中間層の活性化関数はGELU |
| \(\boldsymbol{W_2^{FFN}}\in\mathbb{R}^{3072\times 768}\) | FFNの出力層の重み | 出力層には活性化関数は無し(Linear) |
上の表に示した重み行列のサイズに基づいて、GPT-1のパラメータ数を計算してみます。
まずは、Transformer Blockのパラメータ数は以下のようになります。
$$\begin{array}{lll}
&& \text{Q,K,Vの線形層のパラメータ数}×\text{ヘッド数} + \text{Concat直後の線形層のパラメータ数} + \text{FFNのパラメータ数} + \text{FFNの中間層のバイアス}\\
&=&768\times 64\times 3\times 12 + 768\times 768 + 768\times 3072 \times 2 + 3072\\
&=& 7080960
\end{array}$$
では、全体のパラメータ数を求めてみましょう。全体のパラメータ数は、上記の値を12倍したものに、埋め込み層と位置エンコーディングのパラメータ数を足したものになります。再度述べますが位置エンコーディングに関してはTransformerの原論文ではsinとcosを用いていましたが、GPTでは学習により獲得しますので、これも考慮する必要があるのです。
$$\begin{array}{lll}
&&全体のパラメータ数\\
&=& 7080960\times 12 + 40478\times 768 + 768\times 512\\
&=& 116451840
\end{array}$$
約1.164億です。ほぼ合っていると思います。埋め込み層のパラメータ数が膨大なのは結構意外ですね。約0.267割を占めています。それに、Transformer Block自体のパラメータ数もそこそこ多いこと自体も驚きであったりしますね。
ネットワークの大規模化が比較的進んでいたCNNと比較してみると、152層からなる深層畳み込みニューラルネットワークであるResNet-152のパラメータ数は約6000万個[3]ですので、それと比較してもGPT-1がいかにパラメータ数が多いかが分かると思います。
事前学習
順方向計算
埋め込み層では、以下のような計算をします。
$$
\boldsymbol{h_0} = \boldsymbol{UW_e} + \boldsymbol{W_p}
$$
入力文章\(\boldsymbol{U}\)は行ベクトルで表された各トークンベクトルが縦に並べられた行列です。これを埋め込み層の重み\(\boldsymbol{W_e}\)で埋め込みベクトルに変換します。そして、変換結果に位置情報を追加するために\(\boldsymbol{W_p}\)を足し合わせています(Positional Encoding)。もう一度補足しますが、ここで使われているPositional EncodingはTransformerの原論文で使用されたものとは異なり、学習に基づいたものとなっています。
Transformer Blockでは、以下のような計算をします。
$$
\boldsymbol{h_i} = \text{transformer_block}_i(h_{i-1}) \forall i\in[1,n]
$$
この式は、Transformer Blockが\(n\)か繰り返されることを表しています。GPT-1では、\(n=12\)です。出力層は埋め込み層の重みと共有しており、その転置をTransformer Blockからの出力結果\(\boldsymbol{h_n}\)に適用することで、埋め込み前のonehotベクトルと同じ次元のベクトルに変換し、softmax関数を適用して単語の生起確率に変換します。計算式は以下の通りです。
$$
P(u) = \text{softmax}(\boldsymbol{h_nW_e^T})
$$
これが事前学習における順方向計算です。
損失関数
事前学習に用いる損失関数について説明していきます。\(n\)個のトークンが並んでできているコーパスを以下のように定めます。
$$
\mathcal{U} = \{u_1, u_2, \cdots, u_n\}
$$
このとき、目的関数は以下の対数尤度として表されます。
$$
L_1(\mathcal{U}) = \sum_i \log P(u_i|u_{i-k},\cdots, u_{i-1};\mathcal{\Theta})
$$
即ち、コーパスに含まれている文章を生成できるように学習するのです。
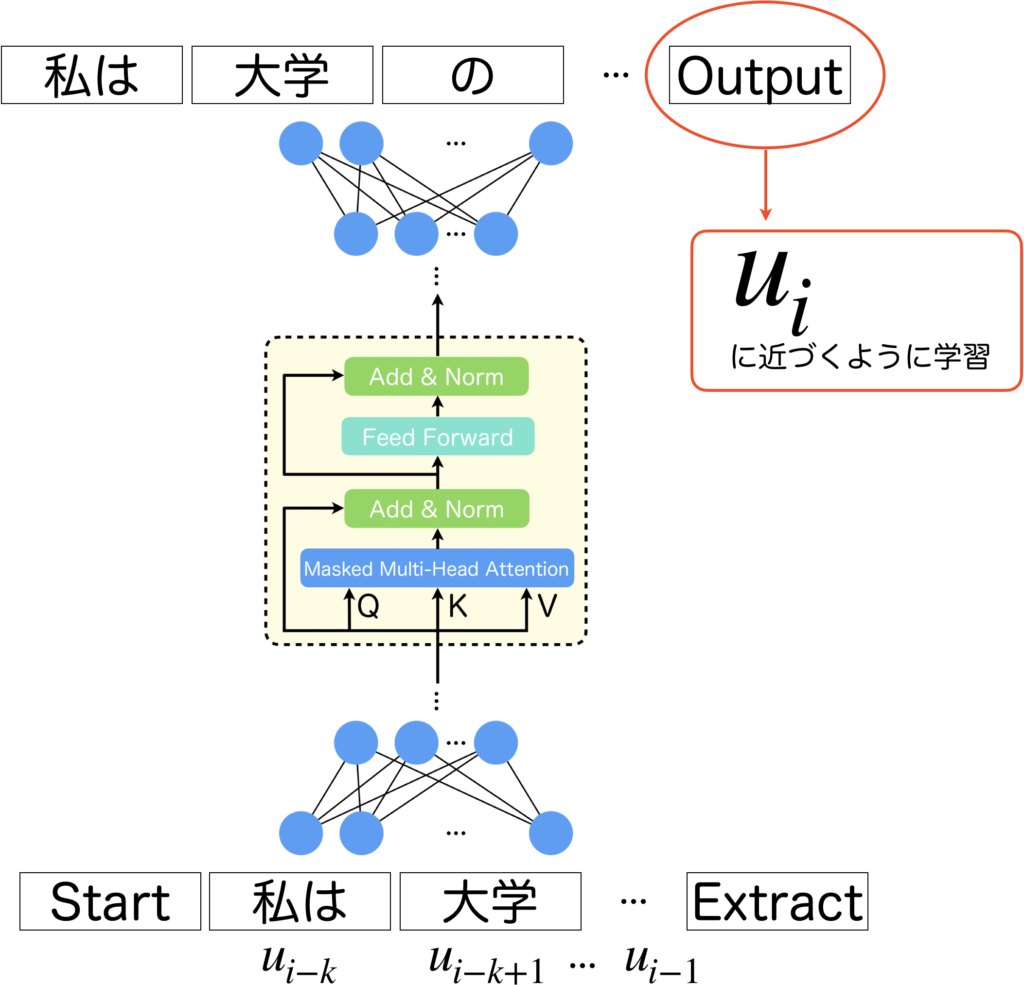
以下の図を見て下さい。GPT-1では、入力をStartとExtractで囲んで入力します。つまり、\(k\)個の連続するトークン\(u_{i-k},\cdots, u_{i-1}\)の両サイドにStartとExtractを追加した、\(k+2\)個の入力を受け取って、\(k+2\)個の出力を出します。最後以外の出力は使用せず、最後の出力が\(u_i\)に近づくように学習を行います。ここで\(i\)をスライドさせていけばコーパス全体に渡り、この学習を適用することができます。
ファインチューニング
次に、タスク依存のファインチューニングをするときに使用するタスク依存の層について説明します。事前学習では、出力層に埋め込み層の重みを転置した重みをもつ層を用いましたが、タスク依存の層では、任意のクラス数のクラス分類層などに交換します。そのときの出力層の重み行列を\(\boldsymbol{W_y}\)とします。GPT-1への入力を\(x_1, x_2, \cdots, x_m\)(\(x_1\)はStart,\(x_m\)はExtract)とすると出力は以下の計算式で導出できます。
$$
P(y|x_1, x_2, \cdots, x_m) = \text{softmax}(h_n^mW_y)
$$
\(h\)の肩についている\(m\)は、\(x_m\)に対する出力です。ファインチューニングで使用するデータセットを\(\mathcal{C}\)としたとき、学習で使用する損失関数は以下のようになります。
$$
L_2(\mathcal{C}) = \sum_{(x,y)}\log P(y|x_1, x_2, \cdots, x_m)
$$
更に、以下のように言語モデル自体の学習も同時に行うと、精度が向上することが発見されています。
$$
L_3(\mathcal{C}) = L_2(\mathcal{C}) + \lambda * L_1(\mathcal{C})
$$
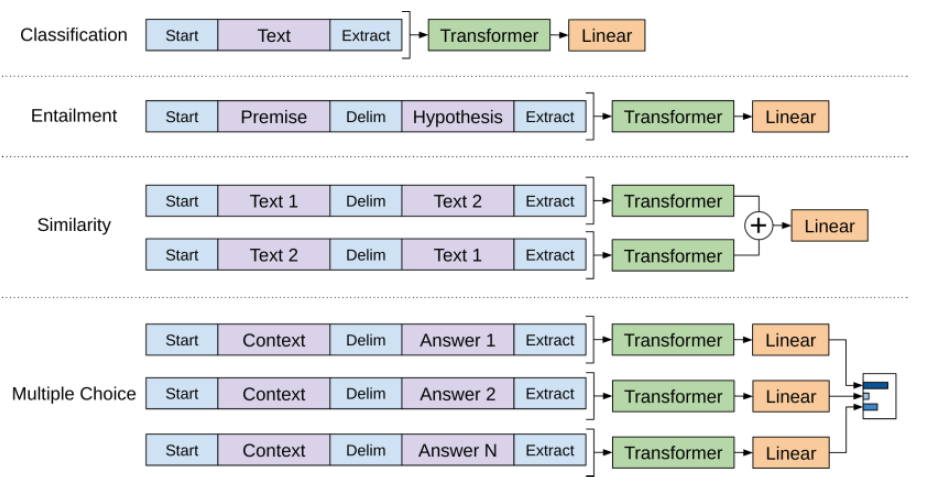
データセット\(\mathcal{C}\)について補足すると、入力データの両サイドはStartとExtractであるのは既述の通りですが、学習させたいタスクによっては、途中にデリミター(Delim)を挿入したものにする必要があります。GPT-1の原論文には以下のように説明がされています。入力された文章のクラス以外は、基本出来に2つの文章をDelimで区切って入力する必要があります。
まとめ
今回は、GPT-1について要点を説明してきました。どのような構造をしているのか、どのような学習を行うのかについてご理解いただけたのではないでしょうか?
GPT-1登場以降に、驚くほどの成果を出したモデルが多く登場しているため、GPT-1の精度よりもアーキテクチャ寄りの解説を行いましたが、重要なエッセンスは説明したつもりです。具体的な実験結果や精度について詳しく知りたい方は原論文を読んで欲しいと思います。最後までお読みいただきありがとうございました。
参考文献
[1] Alec Radford and Karthik Narasimhan, "Improving Language Understanding by Generative Pre-Training," 2018.
[2] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova, "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding," arXiv, 2018.
[3] Sergey Zagoruyko, and Nikos Komodakis, "Wide Residual Networks," in Proc. CVPR, 2016.