
皆さんこんにちは!
以前、Dockerを用いてFlexGenをインストールし、大規模言語モデルを動かしてみました。

これは、NVIDIAのGPUを搭載した一般的なデスクトップPCで動作させたものですが、今回は、なんとJetson AGX Xavierで動作させることができました!!!
ということで、その感動を忘れないうちに、備忘録を書きました。実際にJetsonでFlexGenを通じて大規模言語モデルが動いているところを動画にしていますので、ぜひ見てみてください!
Jetson AGX Xavier
Jetsonとは、自動走行車やロボットなどの機械に深層学習などのAI処理をエッジで行うことを可能にする組込みコンピュータです。以下は、私が持っているJetson AGX Xavierで、今回使用していくものになります。

Jetson AGX Xavierの主なスペックは以下の通りです。
| CPU | 8コア ARM v8.2 64bit CPU |
| GPU | 512コア Volta GPU with Tensor Cores |
| メモリ | 32GB |
| ストレージ | 32GB eMMC 5.1 |
Jetsonには幾つか種類がありますが、大規模言語モデルを動作させられるのは、Jetson AGX XavierとJetson AGX Orinの2機種だけだと思われます。
※Jetson AGX XavierやOrinは、内部にM.2 SSD(タイプは2280)を載せることができます。私の場合は500GBのSSDを載せています。
それが無いと、モデルのダウンロードや圧縮に極端に時間がかかる、または、マシンが落ちるなどの現象が発生することがあるようです。動作しなかった場合は、M.2 SSDを追加して試してみてください。また、AGX Xavierにはメモリサイズが16GBのバージョンもあります。16GBの場合、動作させることが難しいと思われます。
※また、swapファイルを15GB程度用意しておく必要があります。
Dockerfile
JetsonでFlexGenを動作させるためのDockerfileを以下に記載します。Dockerfileは以下のリポジトリのDockerfileを参考にさせていただきました。

ポイントは、Jetsonで動作するPyTorchのイメージを使用している点です。私は、JetPack 5.1を使用しているので、l4t-pytorch:r35.2.1-pth2.0-py3を指定しました。JetPackのバージョンによって対応しているものが異なるため、このページで確認して該当のものに書き換えてください。
FROM nvcr.io/nvidia/l4t-pytorch:r35.2.1-pth2.0-py3
RUN apt-get update && apt-get upgrade -y
RUN git clone https://github.com/FMInference/FlexGen
RUN cd FlexGen && git checkout a8c8aa521e14806d07d01190cf095eb3119ae583 -b develop && pip3 install -e .Dockerfileを作成したら以下のコードを実行してビルドしてください。
sudo docker build . -t jetson:FlexGenビルドが済んだら、以下のコードを実行して、コンテナを起動し中に入りましょう。
sudo docker run -it --runtime nvidia --network host jetson:FlexGenコンテナの中に入ったら以下のコマンドを実行して下さい。
python3 FlexGen/apps/chatbot.py --model facebook/opt-6.7b --compress-weight無事、実行できると下図左のターミナルの最後に記載のように、Humanと表示されます。後は、そこに何か書き込んでみてください。少し時間はかかりますが、ちゃんと応答が返ってきます。
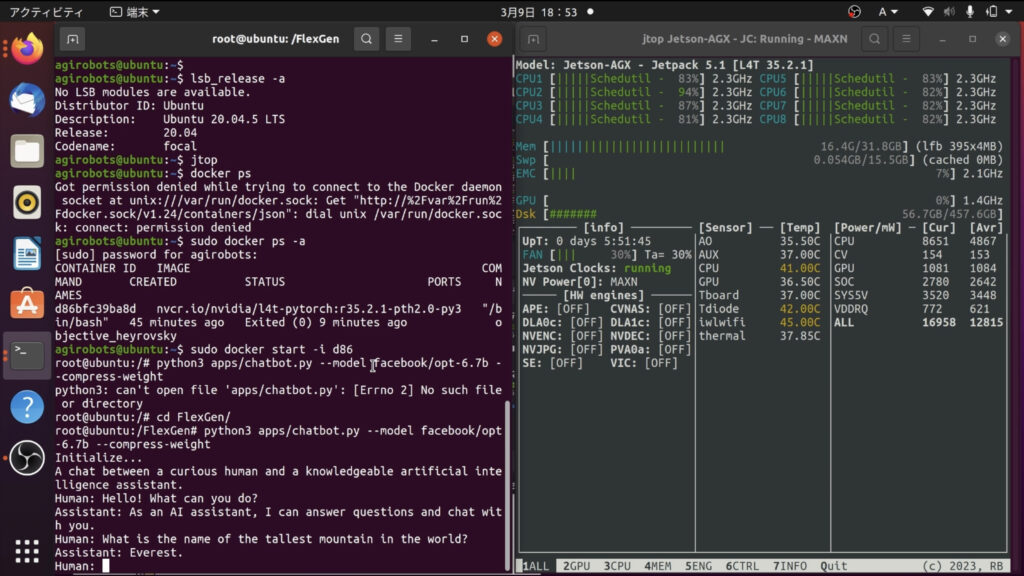
Jetson AGX Xavierは32GBのメモリーを持っていますが、opt-6.7bの重み圧縮モデルなら、16.4GB程度で動作するようです。
応答速度は課題ですが、メモリの容量的に、音声認識のWhisperとかも同時で動かせるかもしれませんね。
夢が広がります!!
今回は、Jetson AGX Xavierを使用しましたが、上位モデルのJetson AGX Orinなどなら、もっと高速で動くはずです!もし、Orinを持ってる方がいましたら、ぜひ試してみてください!!