
本記事では、Dynaと呼ばれるモデルベース強化学習フレームワークについて分かりやすく説明します。このフレームワークは、近年注目を浴びている世界モデルなど強化学習技術の基礎となっています。ぜひ、この機会にDynaについて理解していきましょう!
本記事では、Dynaを理解するうえで必要となる強化学習の基礎知識について説明してからDynaについて解説していきます。
強化学習の概要
逐次意思決定問題とマルコフ決定過程
強化学習とは、逐次意思決定問題と呼ばれる最適化問題において学習を伴う方法のことをいいます。逐次意思決定問題とは人間の意思決定プロセスをモデル化したもので、意思決定を行う主体をエージェント、エージェント以外を環境として定義し、それらが相互作用しながら、エージェントが得られる報酬を最大化するような行動を選択する問題です。
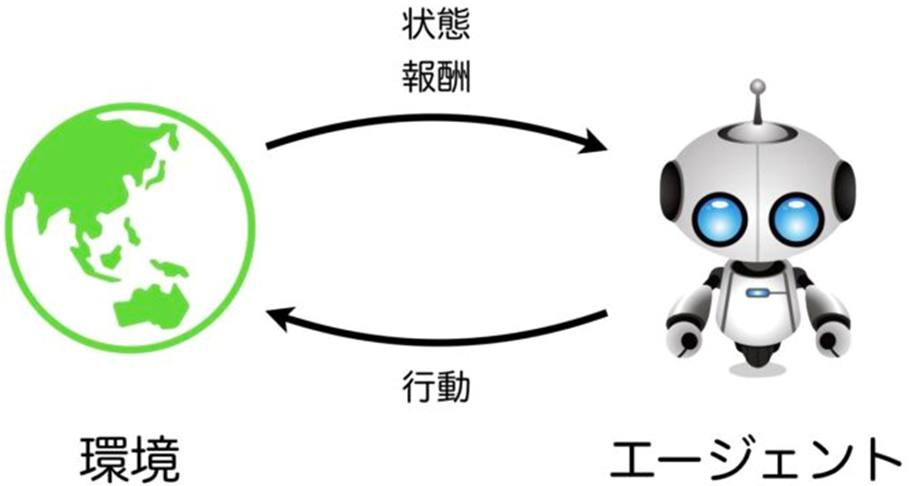
環境からエージェントへは現在の状態\(s_t\)と即時報酬\(r_t\)が、エージェントから環境へは行動\(a_t\)が渡されます。逐次意思決定問題では、これらの関係を定式化するために、環境側にマルコフ決定過程と呼ばれる確率過程を仮定します。このとき、これらの確率変数の関係は下図のグラフとして表すことが出来ます。
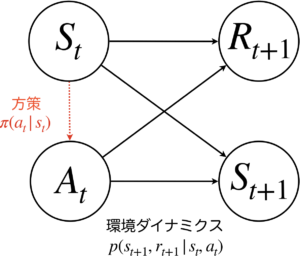
マルコフ決定過程とは、次の状態は直前の状態と行動のみから決定され、それらの変化に対して即時報酬が与えられるという確率過程です。これは確率\(p(r_{t+1}, s_{t+1}|s_t, a_t)\)として表現することができ、これを環境ダイナミクスと呼びます。
プランニングと強化学習
逐次意思決定問題を解く方法には、プランニングと強化学習の2つがあります。これらの違いはエージェントが環境ダイナミクスを知っているかどうかです。エージェントが環境ダイナミクスを知っているということは、実環境のなかで行動しなくても未来を予測できるということです。この場合、エージェントはプランニングを用いることで最適な行動を導き出すことが出来ます。ここには学習は必要ありません。一方で、環境ダイナミクスを知らない場合は、逐一行動を行い、そこで得られた環境の情報から、何が最適な行動なのかを学習していく必要があります。

プランニングと強化学習における行動決定プロセスのイメージを図に表すと上のようになります。プランニングでは幾つかのパス(軌道: Trajectory)を既知の環境ダイナミクスのモデルの中でシミュレートし、最も高評価を得られたパスを見つけ、そのパスにおいて採用された行動を選択します。様々な思考を繰り返すことである程度の最適性を担保することが出来ることから、人間の思考でいうところの熟考的思考を行っているといえます。強化学習は、環境ダイナミクスが未知なので、学習により獲得された方策に基づいて経験則的に良い行動を選択します。これは人間の直感的思考に該当するといえるでしょう。
強化学習の多種多様なアプローチ
プランニングと強化学習のところで、プランニングは熟考的思考で強化学習は直感的思考であると説明しました。厳密にいうと現在の強化学習は直感的思考しかできないわけではないので若干間違っています。これは強化学習理論の成り立ちを考えると、強化学習登場時の考え方としては正しいのですが、強化学習理論が発展するにつれて、強化学習にも熟考的思考を取り入れる方法も登場しています。
直感的思考のみを扱う強化学習とは、状態から行動へのマッピングである方策\(\pi(a_t|s_t)\)(図中の赤色点線矢印)のみを学習する手法で、モデルフリー強化学習と呼ばれます。一方で、熟考的思考を可能にする強化学習は、環境ダイナミクス\(p(r_{t+1}, s_{t+1}|s_t, a_t)\)(図中の黒色実線矢印)を学習する手法で、モデルベース強化学習と呼ばれます。モデルベース強化学習では、近似的な環境ダイナミクスのモデルを獲得することに焦点が当てられており、行動を決定するときは、学習で獲得した環境ダイナミクスのモデルの中でプランニングや方策学習(=モデルフリー強化学習)を行い、行動を決定します。
モデルフリー強化学習やモデルベース強化学習において、”モデル”とは環境ダイナミクスのモデルのことで、それを学習によりモデル化するかどうかにより分けられます。方策のみを学習するものはモデルを考慮しませんのでモデルフリー強化学習で、環境ダイナミクスを学習するものはモデルベース強化学習です。注意点としては、モデルベース強化学習にモデルフリー強化学習による方策学習を取り入れた融合手法もありますが、これも環境ダイナミクスを学習することから、モデルベース強化学習と呼ばれます。少しややこしいですね。
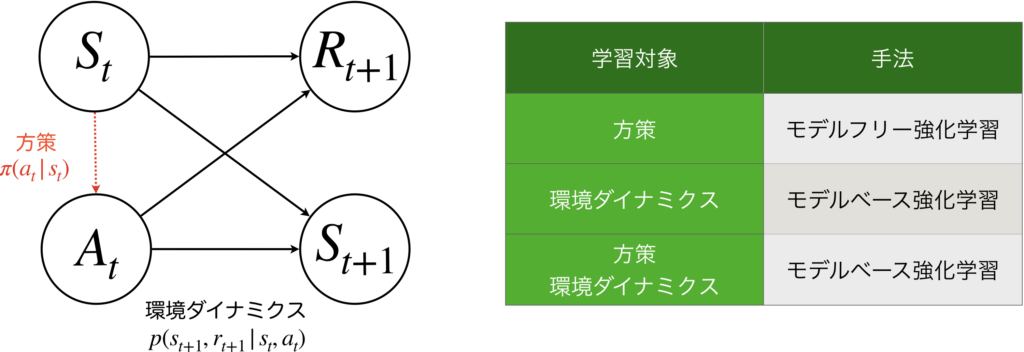
ここで、内容を簡単にまとめると、本来、強化学習は理論の始まりは、状態から行動を決定するプランニングを学習で置き換えることに焦点が当てられていて、強化学習≒モデルフリー強化学習だったわです。しかし、強化学習理論の発展に伴って、環境ダイナミクスを学習する強化学習も登場し、それをモデルベース強化学習といい、そこではプランニングやモデルフリー強化学習と融合して使う、ということです。
モデルベース強化学習の優位性
ここでは、モデルベース強化学習がモデルフリー強化学習よりも優れている点について説明します。
その優れているところとは、環境ダイナミクスの近似モデルを持つところに起因して、
- 行動決定にプランニングを用いることが可能
- 環境とのインタラクション数を減らすことが可能
- 未知の状況にも対応が可能
という点があげられます。①に関しては、すでに説明した通りで、熟考的な知能を実現することができるわけです。②に関してはモデルフリー強化学習と融合した場合のことですが、モデルフリー強化学習単体では、膨大な数の行動を環境に対して実行し、結果を収集する必要があります。しかし、モデルベース強化学習により環境ダイナミクスのモデルを獲得することで、実環境に対して行動をする回数を減らすことが出来ます。つまり、獲得された環境ダイナミクスのモデルの中でモデルフリー強化学習を用いた方策学習ができるので、環境側の時間的な制約を受けることなく高速で方策学習が可能になるという恩恵を受けられます。想像の世界で高速に学習すような感じです。その他、実環境に対して行動する回数が減ると、ロボットの行動学習の際の耐久性の問題についても緩和することができます。③については、環境ダイナミクスの確率分布の学習において良い特徴表現が獲得されていれば、未知の状況でも高い精度で予測することが可能になるため、実環境では控えたいような行動により得られるような未知の状況についても、想像の中で方策学習が可能になります。
【リプレイバッファを持つ方策オフ型のモデルフリー強化学習との違い】
モデルフリー強化学習には、方策オン型と方策オフ型が存在し、方策オフ型の強化学習アルゴリズムは内部に経験を保存しておくリプレイバッファを持つことが出来ます。つまり、過去の経験を保存しておいて、それをバッチ学習により反復的に学習することでサンプル効率を向上させることが出来ます。ここで、過去の経験をバッチ学習する点が、過去の経験を夢として再学習させているようにみえ、モデルベース強化学習の中で方策学習をするのとどう違うのかという疑問を持たれるかもしれません。私の意見ですが、これらの違いは、方策オフ型のモデルフリー強化学習は、過去の経験については忘れないように学習することに焦点をあてており、一方で、モデルフリー強化学習は、未来の未知の経験について学習することに焦点を当てていると考えています。実力テストを例に考えると分かりやすいでしょう。既知の問題は解ける一方で、未知の問題は解けないのがモデルフリー強化学習で、未知の問題であっても解ける可能性があるのがモデルベース強化学習です。一見、頭の悪そうなモデルフリー強化学習でも、大量の問題を解いておけばテスト問題の大半を既知の問題にできるので高得点が狙えます。ですので、シミュレータを活用した強化学習の場合は、あらゆる場合をしらみつぶしに行動して経験を収集できるので、モデルベース強化学習とモデルフリー強化学習の間で大きな性能差は見られない場合が多くあります。差が出るのは、実環境におけるロボットの行動学習のように、経験の数や時間が限られるような状況であり、その場合はモデルベース強化学習の方が高精度になることが多いと印象です。
強化学習の性質は、本当に人間の知能に近いように感じます。人間も膨大な量の経験が可能なら、必ずしも熟考的な知能は必要が無いでしょう(テストの例のように)。年齢を重ねると、質の高い意思決定を高速で行えるようになるのは、若いころよりも経験数が増えて直感の精度が上がるからだと考えられます。つまり直感的知能が磨かれるわけです。しかし、若いころは少ない経験の中で高い意思決定を行う必要があり、その時点では直感の精度が高くないので想像力を働かせて、熟考的に意思決定をする必要性が高くなる感じです。強化学習には凄く親近感を感じますね。
環境ダイナミクスも方策も学習するDyna
Dynaの登場背景
ここまで、強化学習の基礎的内容についてまで解説しました。特にモデルベース強化学習の特徴や優位性について説明しましたが、どのようにして実現するのかは述べていません。以降では、その話をしていきます。そこで登場するのがDyna[1]フレームワークです。Dynaとは、環境ダイナミクスと方策の両方を学習するモデルベース強化学習の手順を具体的に定めたフレームワークです。提案されたのは1990年と古いフレームワークですが、現在のモデルベース強化学習の基礎を築いており重要な仕組みであるといえます。Dynaはあくまでもフレームワークなので、利用するときはQ学習などの具体的なモデルフリー強化学習手法と組み合わせて使用します[2]。
そもそも、なぜDynaでは環境ダイナミクスと方策の両方を学習するフレームワークなのでしょうか。強化学習は、報酬に基づいて学習する点で、教師あり学習などの他の機械学習手法とは異なり、人間的な知能です。しかし、当時の一般的な強化学習手法においては、頭の中で思考するという人間にはできる機能が実現されていなかったのです。これは、まさに先に説明したような直感的な知能であるモデルフリー強化学習が主流だったのです。Dynaの論文では、モデルフリー強化学習で獲得されるような方策を、reactive policyと呼んでいます。日本語にすると反応的方策となり、入力に対して瞬発的に応答する直感的な知能です。しかし、人間は頭の中で思考して方策を修正できる、という点に注目して、環境ダイナミクスを近似的に学習によりモデル化する仕組みを強化学習に取り入れ、その中で方策学習をすれば、頭の中で思考して方策を修正するような知能を実現できるよいのではないか、という、まさにモデルベース強化学習の考え方を導入したのです。Dynaが提案された1990年以前からモデルフリー強化学習やモデルベース強化学習という概念があるのかどうかについてですが、私が論文を調査する限り、モデルベース強化学習やモデルフリー強化学習というワードが見当たらなかったので、その当時はひょっとしたら存在しなかった概念なのかもしれませんので、Dynaがモデルベース強化学習の始祖鳥と考えれば、Dynaの提案背景はよく理解できると思います。
Dynaと世界モデル
Dynaでは、環境ダイナミクスの近似モデルを世界モデルと呼びます。論文の中に世界モデルを意味する"world models"という語が登場するのは、Dynaが一番初めではないでしょうか。世界モデルは別名として内部モデルと呼ばれたりもしますので、異なる呼び方で記載されているものなら、もう少し古くから存在するかもしれませんが、私が調べる限りは世界モデルをはじめて論文に記載したのはDynaだろうと考えています。つまり、Dynaは世界モデルの原点といえるのです。
Dynaの処理手順
Dynaでは次のような3つの手順で、”人間のように頭の中で考えて方策を学習する”モデルベース強化学習を実現します。
- モデルフリー強化学習(方策の学習)
- モデルベース強化学習(世界モデルの学習)
- 世界モデルの中でモデルフリー強化学習
Dynaはまず最初にモデルフリー強化学習を使って、シミュレータや実世界(World)を相手に沢山の行動をし、方策を最適化します。その際には、同時に経験も収集します(経験バッファに経験を保存)。経験とは、現在の状態と行動、次状態、即時報酬の組です。式で表すと\(e=(s, a, s', r)\)になります。そして、この経験を使いモデルベース強化学習で世界モデルを構築します。世界モデルが獲得できたら、世界モデルを環境に見立ててモデルフリー強化学習を実施します。これを図にすると以下のようになります。
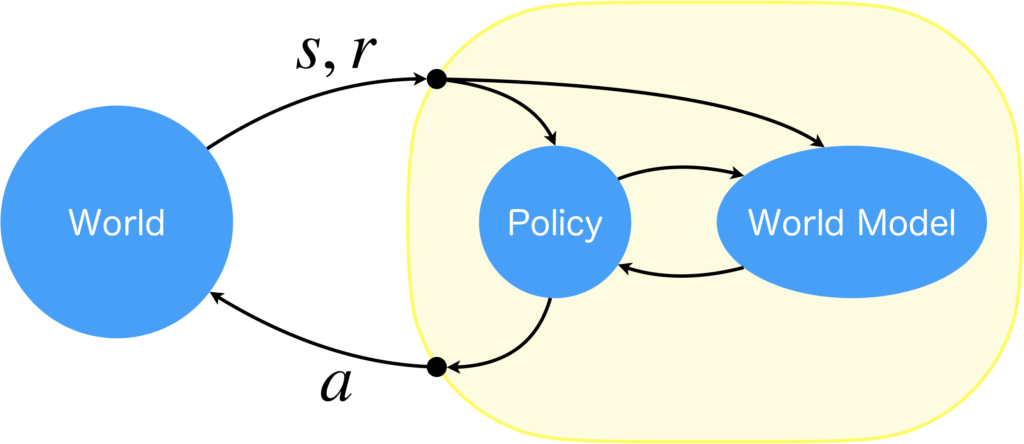
モデルベース強化学習とモデルフリー強化学習を融合する利点
モデルベース強化学習の行動を決める際には、プランニングも利用可能だと説明しましたが、Dynaではモデルフリー強化学習を用いて方策を学習する方法を採用しています。プランニングは計算コストがかかるという点はありますが、それを抜きにすると、プランニングで十分なはずです。なぜ、モデルフリー強化学習による方策学習を導入しているのでしょうか。
私なりの解釈は次の通りです。まず、実世界は本当に複雑ですので、世界モデルに深層ニューラルネットワークを使ったとしても、全ての環境ダイナミクスを近似することは無理です。よく考えれば、世界モデルは実世界全ての環境ダイナミクスを近似する必要は全くなく、頻繁に出くわすような重要な環境ダイナミクスだけ学習すればよいでしょう。では、重要な環境ダイナミクスとは何かを考える必要があります。それには、高い報酬が得られる環境ダイナミクスが該当します。そこにあたりを付ける際にモデルフリー強化学習が重宝するのではと考えています。モデルフリー強化学習は、学習が進むにつれて、最適と考えられる行動を多く選択するようになるため、重要度が高い環境ダイナミクスを集中的に集められ、精度を高くすることができます。他の理由としては、直感的な即時判断を可能にするためでしょう。いくらプランニングの方が熟考的とはいっても、世界モデルの中で膨大な数の学習ができるなら、モデルフリー強化学習により獲得される直感的な方策でも十分だからです。むしろ、その方が知能的です。
さいごに
Dynaは、1990年に提案されたモデルベースの強化学習フレームワークで、環境ダイナミクスと方策の両方を学習することを特徴としています。このフレームワークは、人間が頭の中で思考して方策を修正する能力を模倣することを目的として設計されました。強化学習は、報酬に基づいて学習する手法として、他の機械学習手法とは一線を画しています。Dynaのようなフレームワークの登場により、強化学習に人間のような知能を持たせるための研究がより発展し、新たな研究に応用されることが期待されています。今後は、世界モデルを含むモデルベース強化学習手法の研究が更に進むと考えられるので、この分野には注目したいですね。
参考文献
[1] Richard S. Sutton, "Integrated architectures for learning, planning, and reacting based on approximating dynamic programming," Machine learning proceedings 1990, 1990.
[2] Richard S. Sutton, "Dyna, an integrated architecture for learning, planning, and reacting," SIGART Bull. 2, 1991.