
以前の記事で、R-CNNについて紹介し、物体検出の導入をしました。

本記事では、さまざまなサイズやスケール(大きさや形)の入力画像を処理することができる興味深いニューラルネットワークであるSPP-netを紹介します。
要点
以下に、SPP-netが提案されるにあたって、背景課題、解決策、効果についてまとめました。
- 背景課題
- CNNは固定サイズの画像入力しか受け入れられず、CNNを使って画像認識するには、所定のサイズと形に変換する必要性があった。
- 解決策
- 新たなプーリング手法である、Spatial Pyramid Pooling(SPP)層を提案し、一般的に全結合層の直前に利用するプーリング層をSPP層と交換した。
- 効果
- 学習やテスト時に様々な大きさや形の画像を入力できる。
- Pyramid Poolingは物体の変形にロバストなので、一般的にCNNの分類タスクの性能が向上。
- 物体検出タスクにおいて、CNNへの入力画像の大きさと形の制約がなくなったため、適用階数が1回で済む。
SPP-netのアーキテクチャ
Spatial Pyramid Pooling(SPP)層
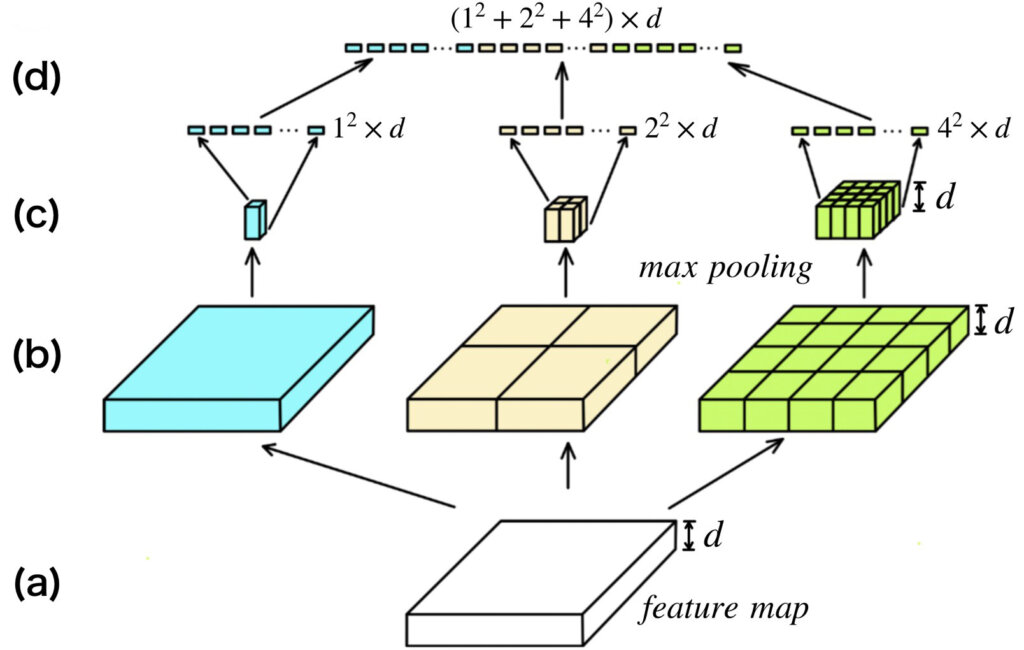
ここでは、SPP-netの重要なアーキテクチャとなるSPP層の仕組みついて解説します。以下の図を見てください。図では、(a)から(d)までの4段階で示しています。それぞれ、
- (a)は、最終の畳み込み層から出力された特徴マップ
- (b)は、指定されたbin、例えば、[1, 2, 4]なら、1x1、2x2、4x4となるように、特徴マップを分割
- (c)は、(b)で分割した領域に対して最大値プーリングを適用
- (d)は、(c)の特徴マップをそれぞれ展開&ベクトル化し、合体させて、固定長の特徴ベクトルを生成
となっています。チャンネル数\(d\)に注目すると、(a)~(c)までは、同じチャンネル数\(d\)が維持され、(d)でベクトルに展開されることがわかると思います。最終的に出力される特徴ベクトルの次元数は、適用したプーリングフィルタのそれぞれのサイズを2乗し加算した値(下図では、\(1^2+2^2+4^4\))に入力特徴マップのチャンネル数\(d\)が乗算されたものになります。すなわち、入力される特徴マップの空間方向サイズに全く依存しません。
一般的なプーリング層との比較をすると、一般的なプーリング層は、フィルタのサイズとストライドがハイパーパラメータとして固定されていますが、SPP層は入力画像サイズに応じてフィルタサイズとストライドを決められたビン数に分割されるように自動調節されます。つまり、
- 一般的なプーリング層
フィルタサイズ・ストライドを固定→出力特徴マップの空間方向サイズが動的に変化 - SPP層
出力特徴マップの空間方向サイズを固定→フィルタサイズ・ストライドが動的に変化
ということになります。
※今回の例のように、プーリングフィルタのサイズを1、2、4として空間方向に適用するため、Spatial Pyramid Poolingと名付けられました。余談ですが、図中において最も左のプーリングは適用領域がGlobal Max Poolingと同じなので、考え方として、GMPの拡張・一般化したものがSPP、もしくはSPPの特別な場合がGMPという解釈が可能と個人的に考えています。GMPというより、GAP(Global Average Pooling)のほうが馴染みがあるかもですが、、、。
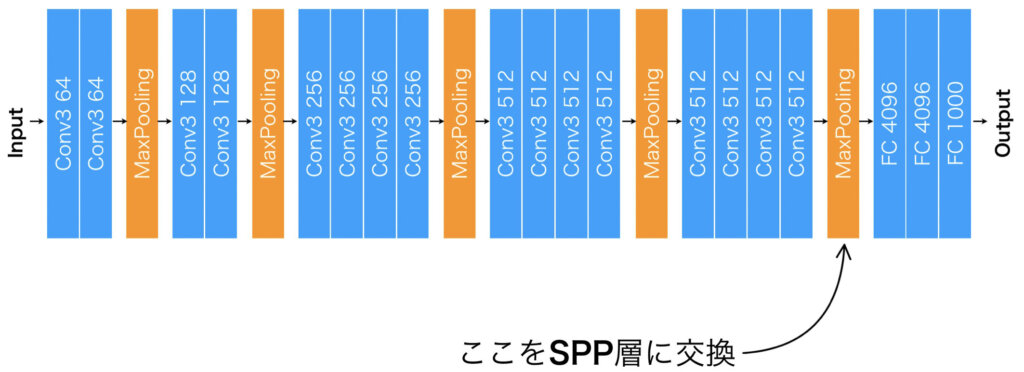
SPP層の使い方
使い方ですが、全結合層の直前に使用されているプーリング層をSPP層で置き換えるというのが基本です。VGG19で例を示すと、右に全結合層が3つありますが、直前に最大値プーリングがあります。この最大値プーリングをSPP層に交換すればいいわけです。
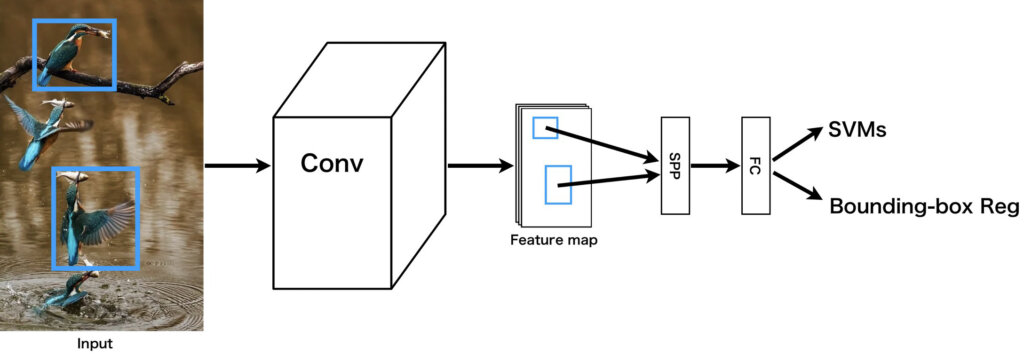
先に紹介した方法は、画像分類で使用されるやり方です。物体検出の場合は適用方法が若干異なります。直前の畳み込み層から出力された特徴マップのうち、注目しているバウンディングボックスに対応する部分だけをSPP層に適用し、固定長特徴ベクトルを得て全結合層に渡します。
SPP層の恩恵
何度も繰り返しになり、内容が重複する部分がありますが、SPP層の恩恵は主に以下の2つが挙げられます。
- 入力画像の大きさや形が制約されない
- 物体検出において、CNNの適用が1回で済む
これらの恩恵は、SPP層が入力特徴マップの空間方向の大きさや形に影響されず、固定長の特徴ベクトルを出力するという本質的特徴により実現されています。
SPP-netの実装
ここまでの、SPP層に関する解説を踏まえ、KerasとTensorFlow Addonsで実装してみたいと思います。
TensorFlow Addonsについて簡単に解説しておくと、コアのTensorFlowには用意されていないマイナーなモジュールが沢山用意されているリポジトリです。使用するには、以下の先に実行して有効にしておく必要があります。
これにより、Spatial Pyramid Poolingを利用できるようになります。
%%bash
pip3 install git+https://github.com/tensorflow/addonsSPP-netの構築で必要になる層とk分割交差検証をするためのクラスをインポートします。
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Conv2D, MaxPool2D, BatchNormalization, Flatten, Dense, Activation, Dropout, Input
from keras.models import Model
from tensorflow_addons.layers import SpatialPyramidPooling2D
from sklearn.model_selection import KFold
from sklearn.model_selection import train_test_split今回学習に使用するデータセットはcifar10です。読み込みが簡単にできるように、Kerasで読み込みモジュールが用意されているので、使用します。また、10クラス分類問題を扱うため、np_utilsを使用して、onehot埋め込みベクトルに変換しています。
from keras.datasets import cifar10
from keras.utils import np_utils
import matplotlib.pyplot as plt
(x_train,y_train),(x_test,y_test)=cifar10.load_data()
x_train = x_train / 255.
x_test = x_test / 255.
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)それでは、SPP層を利用したCNNを定義していきます。本来であれば、全結合層の直前に利用されるプーリング層を、SPP層に変更しています。SPP層の直後には、Flatten層がついていますが、使用しているSPP層モジュールからの出力が特徴マップの形式になっているので、全結合層へ情報を渡すには、Flatten層が必要になります。
# SPP-net
input_layer = Input((None, None, 3))
x = input_layer
x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv1')(x)
x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv2')(x)
x = BatchNormalization()(x)
x = MaxPool2D((2, 2), strides=(2, 2), padding='same', name='block1_maxpool')(x)
x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv1')(x)
x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv2')(x)
x = BatchNormalization()(x)
x = SpatialPyramidPooling2D([1, 3, 5])(x)
x = Flatten(name='flatten')(x)
x = Dense(units=1024, activation='relu', name='fc1')(x)
x = Dense(units=10, activation='softmax', name='predictions')(x)
SPP_net = Model(inputs=input_layer, outputs=x)
SPP_net.compile(loss='categorical_crossentropy', metrics=['acc'])
SPP_net.summary()次に、モデルを学習するための関数と、テストをするための関数を作成します。model_train関数では、K分割交差検証を使用して過学習の抑制を行っています。
def model_train(model, x_train, y_train, batch_size, k, shuffle, epochs):
# kerasで作成したモデルをk分割交差検証を使ってトレーニングする関数
kf = KFold(n_splits=k, shuffle=shuffle)
epoch = 0
loss_list = []
val_loss_list = []
acc_list = []
val_acc_list = []
for _ in range(int(epochs/k)):
ep_loss, ep_val_loss, ep_acc, ap_val_acc = 0, 0, 0, 0 # 1エポックごとの各値を保持する変数を初期化
for train_index, val_index in kf.split(x_train, y_train):
epoch += 1
print(f"Epoch: {epoch}")
history=model.fit(x_train[train_index], y_train[train_index],
batch_size=batch_size,
validation_data=(x_train[val_index], y_train[val_index]))
loss_list.append(history.history['loss'])
val_loss_list.append(history.history['val_loss'])
acc_list.append(history.history['acc'])
val_acc_list.append(history.history['val_acc'])
return [loss_list, val_loss_list, acc_list, val_acc_list]
def model_test(model, x_test, y_test):
test_acc = np.mean(np.argmax(y_test, axis=1) == np.argmax(model.predict(x_test), axis=1))
return test_acc実際に学習させてみます。また、学習させたデータは念のため保存しておきます。
# training
spp_history = model_train(model=SPP_net, x_train=x_train, y_train=y_train, batch_size=128, k=5, shuffle=True, epochs=40)
# save
SPP_net.save("spp_neth5")学習結果として、テストデータを使った時の正解率を確認してみます。
print(f"SPP_net: {model_test(SPP_net, x_test, y_test)}")結果は0.7337となりました。まあまあな出来ですね。
損失関数と正解率の変化は以下のようになりました。
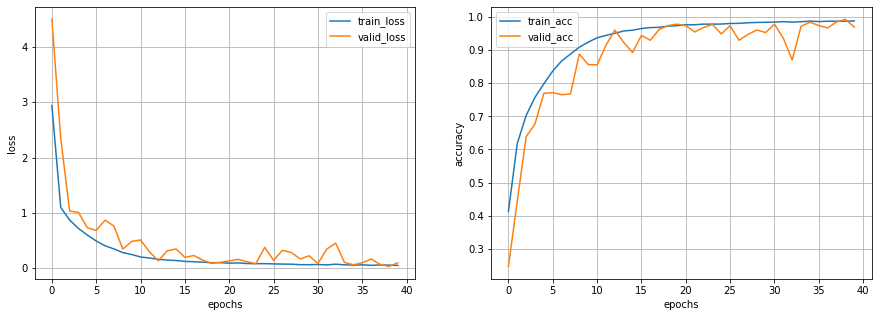
SPP層を追加しているせいか、検証データに関して、あまり値が安定しないようですね。
試しに、pixabayから画像をとってきて入力してみます。
自分が試したのは下の画像です。ちなみに、以下のリンクで公開しています。
https://developers.agirobots.com/jp/wp-content/uploads/2021/05/car-604019_1920.jpg

car_url = "https://developers.agirobots.com/jp/wp-content/uploads/2021/05/car-604019_1920.jpg"
img = np.array(Image.open(io.BytesIO(requests.get(car_url).content)))
img = img[np.newaxis]
cifar10_class_name = ["airplane (飛行機)",
"automobile (自動車)",
"bird (鳥)",
"cat (猫)",
"deer (鹿)",
"dog (犬)",
"frog (カエル)",
"horse (馬)",
"ship (船)",
"truck (トラック)"]
cifar10_class_name[np.argmax(SPP_net.predict(img))]認識結果は、、、、、、、、なんと「鹿」!?!?!でした、、
この画像に関しては、判定を誤ってしまいましたが、とりあえず、固定サイズ以外の入力を受け付けてくれることはご理解いただけたと思います。
考察
上の実装に関して、少しだけ、自分なりの考察をしてみます。SPP層の導入により、さまざまなサイズ・スケールの画像を学習&テスト時に適用可能であることはご理解いただけたと思いますが、なぜ、先ほどの車の画像に関して間違った出力をしてしまったのでしょうか。
それは、学習に画像サイズが32x32のCIFAR10しか利用していないからだと考えます。つまり、テスト時に別のサイズの画像を使うなら、学習時には、あらゆるサイズの・スケールごとにバッチデータを作成し、トレーニングを実施すべきなのです。それができれば、ただ単にさまざまなサイズ・スケールの画像が入力できるだけの、なんちゃってSPP-netではなく、本当にさまざまなサイズ・スケールの画像でも認識できるSPP-netが出来上がるのだと思います。
まとめ
本記事では、SPP層を使用することで入力画像のサイズやスケールの制約を取っ払う方法を紹介しました。具体的には、一般的なプーリング層は、受け取った特徴マップを固定されたピクセル単位でフィルタのスライディング処理をしている一方で、SPPは特徴マップを空間方向に分割するbin数をハイパーパラメータとして与え、その個数に空間を分割し、プーリングを適用するため、入力サイズやスケールに左右されない固定長特徴ベクトル出力を実現させています。
参考文献
K. He, X. Zhang, S. Ren, J. Sun. "Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition", arXiv:1406.4729v4.