
基盤モデルの概要
基盤モデル(Foundation Models: FM)とは、膨大なデータを用いて訓練され、多くの下流のタスクに適応することができる大規模モデルを指します[1]。
研究開発において、事前学習済みモデルをファインチューニングしたり転移学習したりすることで目的のタスクで利用可能なモデルを作成することがありますが、この事前学習済みモデルの中でも、モデル自体のサイズが巨大で、かつ膨大なデータを用いて学習されているようなモデルが基盤モデルなわけです。
基盤モデルの代表例として、BERT[2]やGPT-3[3]などがあります。BERTは、Transformer[4]のエンコーダ部分のみを用いて構築されたモデルで、その事前学習済みモデルがオープンにされたことで、そういったモデルを自力で構築できない方々でも、その高精度な事前学習済みモデルを利用可能になり、ひとたび大きなブームとなりました。GPT-3に至っては、1750億パラメータという巨大なモデルを、膨大なデータで学習した事前学習済みの言語モデルで、人間が作成した文章なのか区別できないほどの、優れた文章生成能力を持ちます。私たちは、OpenAIのAPIを通じてGPT-3の恩恵を受けることができ、それにより、多種多様なサービスが生まれました。
つまり、何が言いたいかというと、基盤モデルの定義自体は、真新しいものではないですが、近年の膨大なデータで学習された巨大な学習モデルが、私たちの想像を超えるような能力を発揮しつつあり、これらのモデルは大きな可能性を持っていますが、その能力やそれが実現される理由などについて、いまだ研究者の中でも明確には分からない状況であり、こういったモデルに対して、基盤モデルという領域を設けて、それらの可能性や、リスクに関しても議論していく必要がある、ということになります。
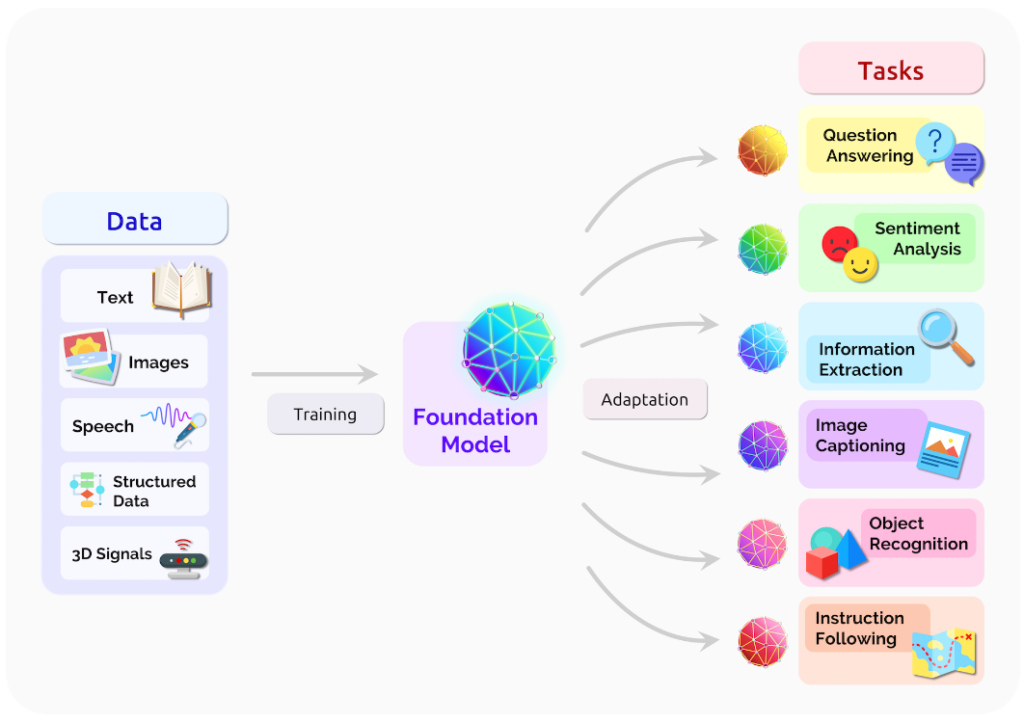
下図は基盤モデルの概要を表しています。基盤モデルは、多種多様なモダリティを含む膨大なデータを用いて学習されるため、多くの下流タスクに適応することができます。従来の特定のタスクに特化したモデルとは異なり、少ない労力で新たなタスクに適用できるようになったり、そもそも追加学習無しでタスクに適用できることもあります。複数のモダリティから学習されたマルチモーダルモデルの場合は、従来までは言語だけ、画像だけ、音声だけなど、特定のモダリティレベルでしか情報を解釈・処理することができなかったモデルが、複数のモダリティにまたがる抽象的な概念の理解なども可能になり、従来までは実現できなかった高度な人工知能の実現も可能になります(代表的なモデルはGPT-4[5])。
基盤モデルには、先に述べた、BERTやGPT-3などはもちろんのこと、DeepMindが開発したGato[6]なども該当する。Gatoについては以下の記事で解説していますが、600にも及ぶタスクを扱うことができ、それらの中には、言語による対話はもちろんのこと、ロボットの制御も可能です。

基盤モデルにより、AIモデルが、環境を認知し、環境に対して作用することができる身体を持つことが可能になります。これにより、複数のモダリティ間で情報がつながり合い、高度な知能を実現できる可能性を秘めているでしょう。
参考文献
[1] R. Bommansani et al.,“On the Opportunities and Risks of Foundation Models,” https://arxiv.org/abs/2108.07258.
[2] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova, "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding," arXiv, 2018.
[3] Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei, "Language Models are Few-Shot Learners," arXiv, 2020.
[4] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin, "Attention is all you need," in Proc. NeurIPS, 2017.
[5] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin, "Attention is all you need," in Proc. NeurIPS, 2017.
[6] Scott Reed, Konrad Zolna, Emilio Parisotto, Sergio Gomez Colmenarejo, Alexander Novikov, Gabriel Barth-Maron, Mai Gimenez, Yury Sulsky, Jackie Kay, Jost Tobias Springenberg, Tom Eccles, Jake Bruce, Ali Razavi, Ashley Edwards, Nicolas Heess, Yutian Chen, Raia Hadsell, Oriol Vinyals, Mahyar Bordbar, and Nando de Freitas, "A Generalist Agent," arXiv, 2022.