
近年、機械学習分野で大きな成果をあげているTransformer[1]において、その中核をなすScaled Dot-Product Attention[1]には、革新的な仕組みが備わっています。その仕組みとは、後で詳しく説明しますが、入力に応じて重みを動的に変えることが可能なニューラルネットワークで、これにより驚くほど広範囲で膨大な情報に対する適応性と表現力を実現することができます。本記事では、Scaled Dot-Product Attentionのこの仕組みとその利点について解説し、私なりの解釈を紹介できればと思います。
先に結論を簡単に
まず、結論から説明すると、Scaled Dot-Product Attentionは、入力に基づいて重みを変えることが可能なニューラルネットワークという解釈が可能です。ただし、Scaled Dot-Product Attentionは学習パラメータを持たないため、実際に利用するときは、Key、Query、Valueの各入力の直前に学習パラメータを持つ線形層を追加し、入力に基づいた重みの変換ルールを学習できるAttentionを用います。
とはいえ、Scaled Dot-Product Attentionを導入することで、入力に応じて重みが変化するニューラルネットワークを実現できるわけですので、Scaled Dot-Product Attentionを持たない、すなわち、学習後は重みが変化しない静的なニューラルネットワークよりも圧倒的な表現力の高さをを実現することができます。
ChatGPTなどで使用されているGPTをはじめ、Transformerベースのモデルの表現能力の高さは、このScaled Dot-Product Attentionの優れた特徴に起因していると考えられます。
Scaled Dot-Product Attention
Scaled Dot-Product Attentionについては以下の記事で詳しく説明しているので、そちらを参考にしてください。

簡単に概要を説明すると、QueryとKeyからAttention Matrixと呼ばれる行列を計算し、それとValueの内積を計算するのがScaled Dot-Product Attentionです。
Attention Matrixは、入力シーケンスを構成する全てのトークンの組み合わせについて、どのトークンに注目すべきか(=Attention)を計算したものです。Attention MatrixとValueの内積演算により、注目すべきトークンの影響力を強め、そうでないトークンの影響力を弱めて、新しいトークンを生成する処理が行われます。
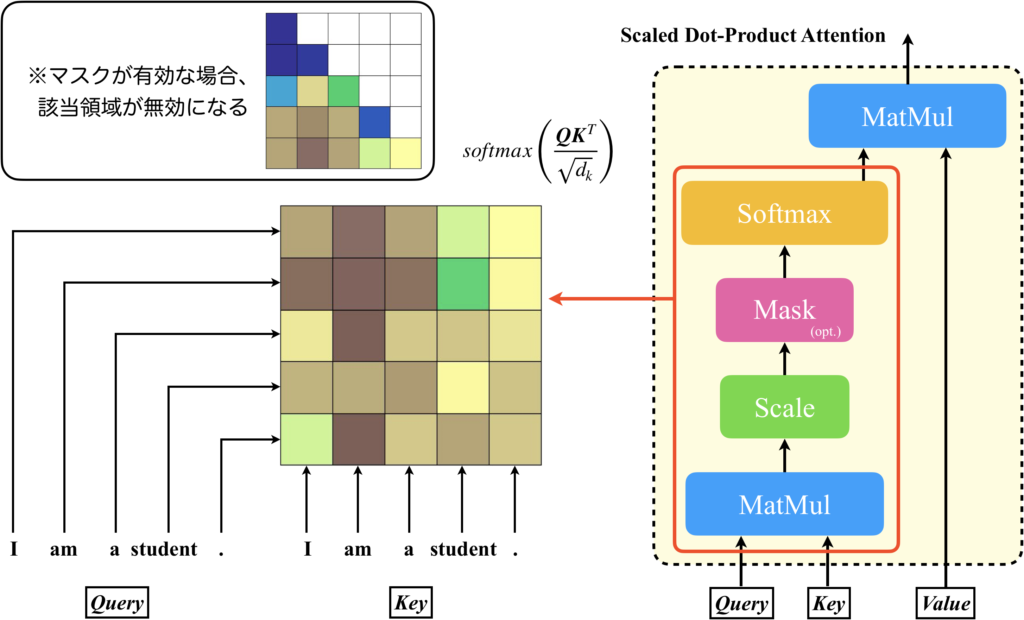
Scaled Dot-Product Attentionは入力に基づいて重みを変えられるニューラルネットワーク
Scaled Dot-Product AttentionのAttention MatrixとValueの内積処理について、図を使って説明します。以下の図を見てください。
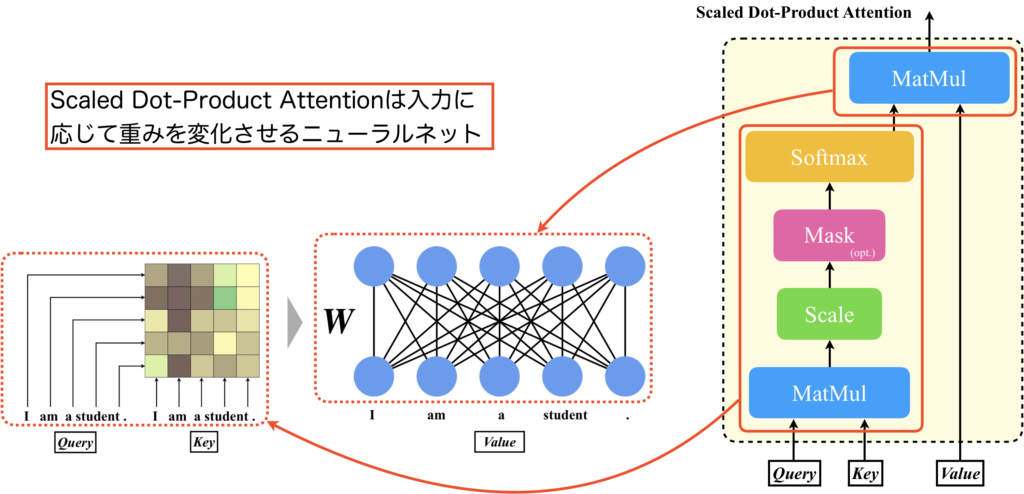
QueryとKeyを入力として受けてsoftmaxを適用するまでのパスでAttention Matrixが計算されます。そして、Attention MatrixとValueの内積処理を行うMutMulは、線形層(=活性化関数が恒等関数のニューラルネットワーク)の処理と同じです。つまり、Valueを入力とし、Attention Matrixを重み行列とするニューラルネットワークと見なすことができます。Attention Matrixは入力に応じて変化するので、これを重み行列とするニューラルネットワークは、入力に応じてネットワークの特性を変えることができるのです[2,3]。
一般的なニューラルネットワークとの違いをより分かりやすく説明します。下の図を見てください。この図では、自然言語("I am a student.")を入力として使用し、各ニューロンが1つの単語を表しています(厳密には単語はトークンベクトルとして扱われますが、ここでは簡単のため単純化しています)。重みが静的なニューラルネットワークでは、重み行列\(\boldsymbol{W}\)は入力文章に依存せず一意に定まるものです。ですので、入力文章が異なっていても同じ重み行列\(\boldsymbol{W}\)が使用されます。一方、Scaled Dot-Product Attention(図ではSelf-Attentionとして使用)では、入力文章に対して重み行列\(\boldsymbol{W}\)が動的に変化します。すなわちネットワークの特性は入力文章が決まらないと決定されません。
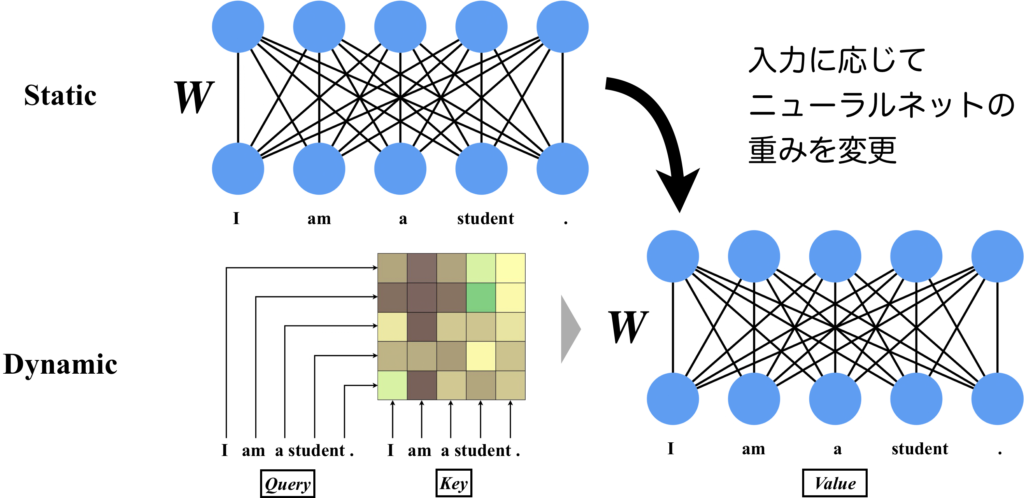
入力に対して動的な重みを持つことの利点
Scaled Dot-Product Attentionの重みを入力に基づいて変更できる利点は、どこにあるのでしょうか?
以降は私の持論ですが、私の持っている考えを共有します。
先ほどの図において、スタティックなニューラルネットワークでは、重み行列\(\boldsymbol{W}\)を直接学習します。一方で、Scaled Dot-Product Attentionを利用したSingle-Head AttentionやMulti-Head AttentionなどのAttentionでは、重み行列\(\boldsymbol{W}\)を入力文章に応じて適切に呼び出せるように、Query、Keyに付与された線形層のパラメータを学習します(もちろん、それだけでは十分ではないのでValueに付与された線形層のパラメータも学習しますが)。両者の違いは、重み行列\(\boldsymbol{W}\)を直接的に学習するか、間接的に学習するかの違いです。それだけですが、後者の方法では、重み行列\(\boldsymbol{W}\)を実質的に無限パターンも扱えるようになるため、重み行列\(\boldsymbol{W}\)を直接的に学習する場合のニューラルネットワークを、無限個重ね合わせるような学習能力や柔軟性を実現できるのではないかと思うのです。つまり、文章の分野、ジャンル、言語などから、適切なニューラルネットワークを構築するという、抽象的な領域で学習が行えると思っています。
ChatGPT-3.5では、96層のTransformer Blockから構成されたニューラルネットワークであるGPT-3.5が使用されています。各Transformer Blockにはいくつかのニューラルネットワークの層がありますので、ニューラルネットの層数は厳密には異なりますが、このような規模感でも、おそらくご存じのような、多言語で多種多様な分野を扱える高性能なモデルを実現できるのです。
さいごに
Scaled Dot-Product Attentionは、入力に基づいて重みを変えることが可能なニューラルネットワークという解釈が可能です。ただし、Scaled Dot-Product Attentionは学習パラメータを持たないため、実際に利用するときは、Key、Query、Valueの各入力の直前に学習パラメータを持つ線形層を追加し、入力に基づいた重みの変換ルールを学習できるAttentionを用います。
とはいえ、Scaled Dot-Product Attentionを導入することで、入力に応じて重みが変化するニューラルネットワークを実現できるわけですので、Scaled Dot-Product Attentionを持たない、すなわち、学習後は重みが変化しない静的なニューラルネットワークを多数重ね合わせたような圧倒的な表現力の高さをを実現することができます。
ChatGPTなどで使用されているGPTをはじめ、Transformerベースのモデルの表現能力の高さは、このScaled Dot-Product Attentionの優れた特徴に起因していると考えられます。
本記事を通じて、少しでもTransformerの高性能さの所以について理解を深めていただけましたら幸いです。
参考文献
[1] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin, "Attention Is All You Need," in Proc. NeurIPS, 2017.
[2] Nikolas Adaloglou, and Sergios Karagiannakos, "How attention works in deep learning: understanding the attention mechanism in sequence models," https://theaisummer.com/attention/, 2020.
[3] Yizeng Han, Gao Huang, Shiji Song, Le Yang, Honghui Wang, and Yulin Wang, "Dynamic Neural Networks: A Survey," IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021.