
ここまで、誤差逆伝播学習や活性化関数について説明してきました。そのまとめとして、本記事では、NumPyだけを使用して多層パーセプトロンクラスを実装してみた結果を紹介&解説していきたいと思います。あくまでも多層パーセプトロンクラスの実装の一例なので、ゆるーく見ていただけましたら幸いです。
※作成したクラスについて全ての組み合わせで動作確認をするのは大変なのでしていません。そのため、インスタンス化する際の指定方法によってはうまく動かないかもしれません。見つけ次第、更新します。(もし発見された場合はコメントで教えてくれると嬉しいです!)
※この記事に解説動画はありません。
作成するMLPクラスの仕様
以下に仕様を示します。
- 中間層の層数は可変
- 使用できる活性化関数は、sigmoid, softmax, identity, relu
- 誤差関数は、平均二乗誤差と交差エントロピー誤差
- 入力データや教師データは各々のデータが列ベクトルで表現されている行列
とします。例えば、
mlp = MLP(num_neurons=[784, 1000, 1000, 100, 10],
activation_function=['relu', 'relu', 'relu', 'softmax'],
bias=True,
loss='CrossEntropyLoss')のようにインスタンス化することを想定しています。この例では、入力層のニューロン数は784個、中間層の総数は3つで、順に1000個、1000個、100個のニューロンを持ち、出力層のニューロン数は10個で、それぞれ使用する活性化関数は順にrelu、relu、relu、softmax、バイアスニューロンありで、交差エントロピー誤差関数を使うことを表しています。
作成するMLPクラスの概略
細部を省略したMLPクラスを以下に示します。
class MLP():
def __init__(self, num_neurons, activation_function, bias):
"""
MLPの仕様:層ごとのニューロン数, 活性化関数, バイアスの有無, etc...
MLPの行列:各層の重み行列, 出力行列, イプシロン, etc...
"""
def init_w(self):
"""
MLPを定義したときに一度だけ実行する
各層間の重み行列をリストに保持させ標準正規分布で初期化
"""
def init_z_ex(self):
"""
各層の出力行列をリストとして保持
"""
# ==========活性化関数の定義==========
# ==========ここまで==========
# ==========活性化関数の導関数の定義==========
# ==========ここまで==========
def init_epsilon(self):
"""
各重みを更新するためのイプシロンを格納するリストを定義&ゼロで初期化
"""
def zero_epsilon(self):
"""
前の学習時に計算したイプシロンを初期化
"""
def acf(self, activation_function, x):
"""
辞書から指定の活性化関数の値を返す
"""
def acf_der(self, activation_function, x): # 辞書から指定の活性化関数の導関数の値を返す
"""
辞書から指定の活性化関数の導関数の値を返す
"""
# フォワード計算
def forward(self, x):
# 一括してすべての層のイプシロンを計算
def backward(self, t):
# イプシロンを使用して重みを一括更新
def optim(self, eta):
# モデルのサマリーを表示させる
def summary(self):
# 入力データからバッチデータのリストを作成
def make_batch_data(self, x, t):
# 二乗誤差関数
def MSELoss(self, x, t):
# 交差エントロピー誤差関数
def CrossEntropyLoss(self, x, t):
# トレーニングを実施する関数
def train(self, x, t, epochs, batch_size, eta=0.01, warm_start=True):
# 予想を実施する関数
def predict(self, x):上のクラスに出てきた関数の一覧は以下です。
- init_w(self):
# 各層間の重み行列を格納するリストと重み行列を定義し標準正規分布で初期化 - init_z_ex(self):
# 各層の出力を格納するリストとバイアスニューロンを考慮した各層の出力行列を定義 - init_epsilon(self):
# 各層の誤差を格納するリストと行列を定義 - zero_epsilon(self):
# 学習ステップごとに計算した誤差を0で初期化 - acf(self, activation_function, x):
# 指定された活性化関数の出力を返す - acf_der(self, activation_function, x):
# 指定された活性化関数の導関数の値を返す - forward(self, x):
# 前向き演算 - backward(self, t):
# 各層が受け取る誤差イプシロンを計算 - optim(self, eta):
# 計算された誤差イプシロンを使って全重みを一括更新 - summary(self):
# 定義したニューラルネットワークのsummaryを標準出力へ表示 - make_batch_data(self, x, t):
# バッチデータを作成 - MSELoss(self, x, t):
# 平均二乗誤差関数 - CrossEntropyLoss(self, x, t):
# 交差エントロピー誤差関数 - train(self, x, t, epochs, batch_size, eta=0.01, warm_start=True):
# モデルをトレーニング - predict(self, x):
# 予測を実施
あと、ここでは記載していませんが、活性化関数は、lambdaとして定義しました。詳細は次で説明します。
各メソッドの説明
ここでは各メソッドについて詳細を説明していきます。
コンストラクタ__init__
コンストラクタでは、クラス内のどのメソッドからも参照可能にしておきたいものを書きます。記載した内容は以下です。
def __init__(self, num_neurons, activation_function, bias, loss):
self.num_neurons = np.array(num_neurons) + bias # biasがTrueなら各層にbiasニューロンを追加
self.num_layers = len(num_neurons) # 層数のカウント
self.bias = bias
self.loss = loss
self.w = [] # 層間の重み行列をリストで格納
self.z_ex = [] # 各層の出力をリストで格納
self.epsilon = [] # 各層のイプシロンを計算
self.history = [] # 学習過程として誤差関数の値を保持
self.status = 0 # 学習開始したかどうかのステータス(1は開始済み)
self.batch_size = None # batch_sizeを保持
self.activation_function = activation_function # 活性化関数をリストで保持
self.acf_dict = {'sigmoid':self.sigmoid, 'softmax':self.softmax, 'identity':self.identity, 'relu':self.relu} # 活性化関数のリスト
self.acf_der_dict = {'sigmoid':self.sigmoid_der, 'identity':self.identity_der, 'relu':self.relu_der} # 活性化関数とその導関数のリスト
self.loss_dict = {'MSELoss':self.MSELoss, 'CrossEntropyLoss':self.CrossEntropyLoss} # ここに誤差関数を格納1行目は、インスタンス化する際にコンストラクタへ渡す変数を表していて、それには各層のニューロン数をリスト形式で保持したnum_neurons、各層の活性化関数の情報をリスト形式で保持したactivation_function、バイアスの有無を指定するブール変数のbias、使用する誤差関数を指定するストリング型のlossを用意しました。
2行目は、インスタンス化したときに渡される各層のニューロン数の情報に、ブール値のbiasを足す操作をしています。num_neuronsで渡される各層のニューロン数は、バイアスニューロンを含みません。しかし、biasがTrueであれば、以下の図のようにバイアスニューロンを追加した形で考えたいので、biasを足しています。
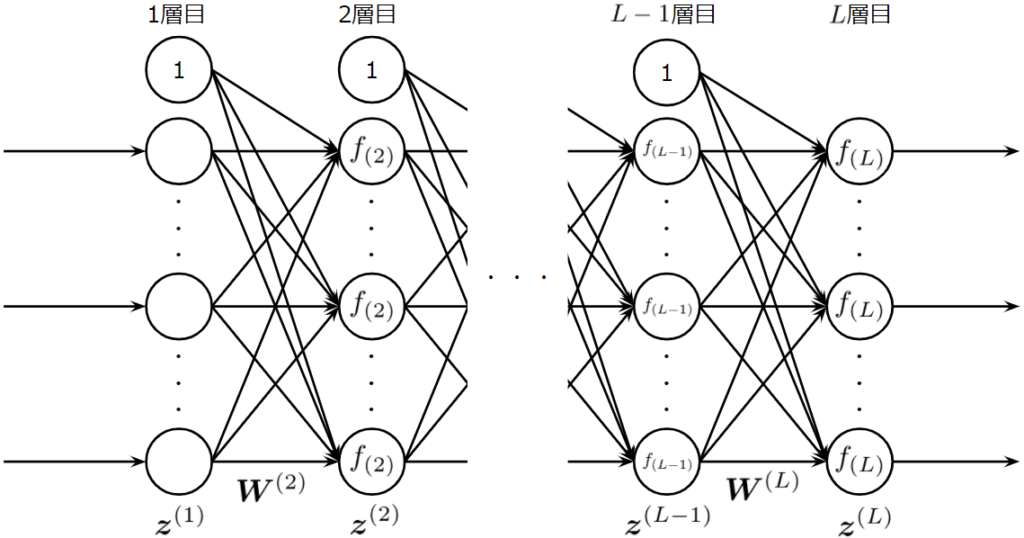
一方で、biasがFalseのときは以下のようなネットワークを考えることになります。
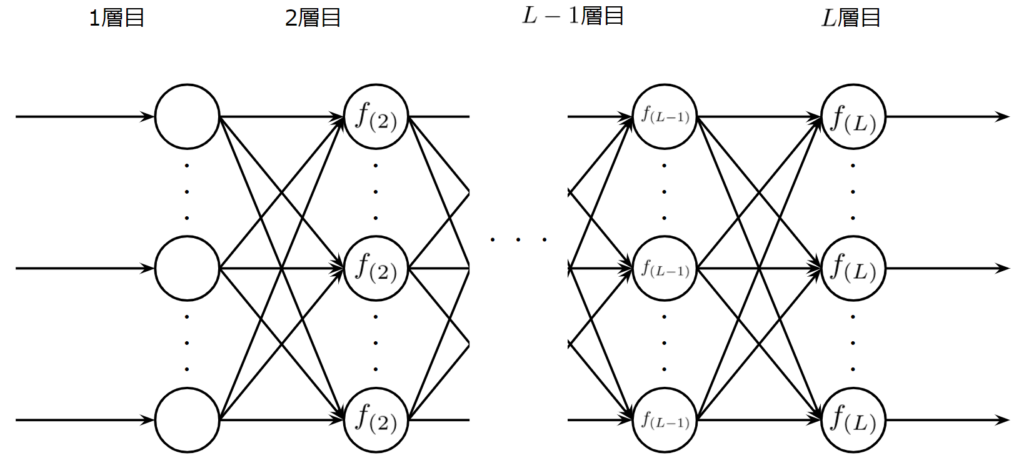
3行目は層数をカウントしています。層数はフォワード計算、バックワード計算、重み更新のforループを実行する際に使用するので、ここで定義しています。
6行目は各層間の重み行列を格納するリストで、7行目は各層の出力行列を格納するリスト、8行目は各層の誤差イプシロンの行列を格納するリストで、このように各層それぞれにかんする行列を保持することで、高速な計算、学習処理を実現させています。
9行目のself.historyは学習時に指定された誤差関数の値を保持するリストです。
10行目のself.statusは、学習をスタートしたかどうかのステータスを保持する変数で、これが0なら学習を始めていない、つまり、重み行列を初期化した直後であることを示し、一度でもtrainメソッドを実行したら1になります。このようなステータスを用意することで、ワームスタート、つまり、再度train関数を呼び出したときに続きから学習を再開することを可能にさせることができます。
11行目のself.batch_sizeはバッチサイズを保持します。batch_sizeはバッチデータを作成するとき以外にも、各層の出力行列の定義、各層のユニットが受け取る誤差イプシロンの行列の定義でも使用します。
13行目のself.acf_dictは活性化関数の名前とその関数の対応関係を保持する辞書です。
14行目のself.acf_der_dicもself.acf_dictと同様で、活性化関数の名前とその導関数を対応つけるリストです。
15行目のself.loss_dictは誤差関数の名前とその関数を対応させます。
init_w
# 各層間の重み行列を標準正規分布で初期化する
def init_w(self): # MLPを定義したときに一度だけ実行する
self.w = [] # リストとして再度初期化
self.state = 0 # ステータスを未学習に変更
self.history = [] # 重みを初期化した際には、同時にhistoryも初期化
for i in range(self.num_layers)[:-1]:
self.w.append(np.random.randn(self.num_neurons[i+1] - self.bias, self.num_neurons[i]))この関数は、各層の重み行列を、num_neuronsに格納されたニューロン数を使用して標準正規分布に従うランダム値で定義・初期化し、順番にリストに格納します。重みを初期化したら未学習状態となるため、self.statusを0にセットし、self.historyも初期化します。np.random.randnの行では、重み行列を定義していますが、写像の際に、写像先のバイアスニューロンは計算の対象とならないため、self.biasを引いたものを使用しています。
活性化関数の定義
# ==========活性化関数の定義==========
# シグモイド関数の定義
sigmoid = lambda self, x: 1/(1+np.exp(-x))
softmax = lambda self, x: np.exp(x)/np.exp(x).sum(axis=0) # ソフトマックス関数
identity = lambda self, x: x # 恒等関数
relu = lambda self, x: np.maximum(0, x) # ReLU
# ==========ここまで==========ここでは、活性化関数を定義していますが、活性化関数は様々なバリエーションがあり、その都度、defを使用すると読みにくくなると考えたため、lambdaで定義しました。
活性化関数の導関数の定義
# ==========活性化関数の導関数の定義==========
sigmoid_der = lambda self, x: x*(1-x) # xはシグモイド関数からの出力
identity_der = lambda self, x: np.ones(x.shape) # 恒等関数の導関数
relu_der = lambda self, x: np.where(x>0, 1, 0) # ReLUの導関数
# ==========ここまで==========活性化関数の導関数についても同様に、lambdaで定義しました。
init_z_ex
# 各層間の重み行列を標準正規分布で初期化する
def init_w(self): # MLPを定義したときに一度だけ実行する
self.w = [] # リストとして再度初期化
self.state = 0 # ステータスを未学習に変更
self.history = [] # 重みを初期化した際には、同時にhistoryも初期化
for i in range(self.num_layers)[:-1]:
self.w.append(np.random.randn(self.num_neurons[i+1] - self.bias, self.num_neurons[i]))init_z_exはバイアスニューロンを考慮した層の出力行列をリストで保持します。それぞれの行列の列数はバッチサイズに依存します。そして、バイアスニューロンが常に1を出力することから、初期化の際には全成分を1になるようにしています。
init_epsilon
# 各重みを更新するためのイプシロンを格納するリストを定義&ゼロで初期化
def init_epsilon(self):
self.epsilon = []
for num in self.num_neurons[:-1]:
self.epsilon.append(np.zeros((num-1, self.batch_size)))ここでは、各データにおける誤差を格納するために、誤差イプシロンの行列を全ての層に対して定義し、リストで管理します。
zero_epsilon
def zero_epsilon(self): # 前の学習時に計算したイプシロンを初期化
for eps in self.epsilon:
eps *= 0逆伝播される誤差イプシロンは学習ステップごとに再計算する必要があり、以前のデータが残っていると正しく最適化できないので、ステップごとに毎回この関数を呼び出して0にリセットします。PyTorchのzero_grad()みたいなものです。
acf
def acf(self, activation_function, x): # 辞書から指定の活性化関数の値を返す
return self.acf_dict[activation_function](x)acfはacivation functionを訳してネーミングしました。フォワード計算のさいには、この関数へ使用する活性化関数の名前と入力値を渡せば、関数内部で適切な活性化関数を呼び出し計算結果を返してくれます。この関数を定義する理由は、活性化関数ごとforwardメソッド内の記述を定義ししなくても済むからです。
acf_der
def acf_der(self, activation_function, x): # 辞書から指定の活性化関数の導関数の値を返す
return self.acf_der_dict[activation_function](x) これは、誤差逆伝播の計算で使用します。acfと同様の使い方で利用できます。注目している層の活性化関数の名前と、その層の出力を渡すことで、適切な導関数の値を返してくれます。
forward
# フォワード計算
def forward(self, x): # テストデータを入力できるようにする
self.z_ex[0][self.bias:,] = x # 入力データを拡張する
for i in range(self.num_layers)[:-1]:
# 配列の指定方法に起因して示した計算式と若干異なる
self.z_ex[i+1][self.bias:,] = self.acf(self.activation_function[i], self.w[i]@self.z_ex[i])この関数は、フォワード計算をします。行っているのは入力行列(もしくはベクトル)から出力行列(もしくはベクトル)を求める作業です。3行目で、入力ベクトルをバイアスニューロンを含んだ形式にしています。self.z_exは1で初期化されているので、層の番号を指定したうえでbiasニューロンを除いた部分行列に値を代入すればバイアスニューロンを含んだ形式の出力行列が得られる性質を利用しています。forループ中の操作も同様です。biasニューロンをスライスにより取り除いた部分行列に、その層の出力を代入することで、バイアスニューロンを持つ行列に拡張しています。
backward
# 一括してすべての層のイプシロンを計算
def backward(self, t):
self.zero_epsilon() # 以前に計算したイプシロンの値をゼロで初期化する
# 出力層のイプシロンを計算
if(self.loss=='MSELoss'):
self.epsilon[-1] = (self.z_ex[-1][self.bias:] - t)*self.acf_der(self.activation_function[-1], self.z_ex[-1][self.bias:])
else: # 交差エントロピー誤差が指定されたら、出力層はほぼ確実にソフトマックス関数なので、ソフトマックス関数で計算
self.epsilon[-1] = (self.z_ex[-1][self.bias:] - t)
for i in range(-2, -self.num_layers, -1):
# 中間層のイプシロンの計算:シグモイド関数の微分アリ
self.epsilon[i] = self.w[i+1][:,1:].T@self.epsilon[i+1]*self.acf_der(self.activation_function[i], self.z_ex[i][self.bias:])この関数は、基本的に以下に示す重み更新式の計算を行っています。
\begin{eqnarray} \Delta\boldsymbol{W}^{(l)}&=&-\eta \frac{1}{N}\boldsymbol{\mathcal E}^{(l)}(\boldsymbol{Z}_{ex}^{(l-1)})^T\\ \mbox{ただし }\boldsymbol{\mathcal E}^{(l)}&=&\left\{\begin{array}{ll} (\boldsymbol{Z}_{ex}^{(l)}[bias:] – \boldsymbol{T})\odot f’_l(\boldsymbol{U}^{(l)})&\mbox{\(l\)が出力層(\(l=L\))}\\ (\boldsymbol{W}^{(l+1)}[:, bias:])^T\boldsymbol{\mathcal E}^{(l+1)}\odot f’_l(\boldsymbol{U}^{(l)})&\mbox{\(l\)が中間層(\(l<L\))} \end{array}\right. \end{eqnarray}
仮に、出力層で使う活性化関数が恒等関数かソフトマックス関数だけであれば、より簡単に出力層のイプシロンを導出できるのですが、ここでは、出力層の活性化関数としてシグモイド関数も使用できるようにしました。ただし、クラスの簡単化のために、交差エントロピー誤差関数とソフトマックス関数はセットで利用すると仮定しました。このような前提のもと、条件分岐を使用して出力層のイプシロンを計算するように定義しました。
7行目は平均二乗誤差関数を使用したときの逆伝播させる誤差の計算式、9行目は交差エントロピー誤差関数とソフトマックス関数を使用したときの計算式です。
\begin{eqnarray} \Delta\boldsymbol{W}^{(l)}&=&-\eta \frac{1}{N}\boldsymbol{\mathcal E}^{(l)}(\boldsymbol{Z}_{ex}^{(l-1)})^T\\ \mbox{ただし }\boldsymbol{\mathcal E}^{(l)}&=&\left\{\begin{array}{ll} (\boldsymbol{Z}_{ex}^{(l)}[bias:] – \boldsymbol{T})&\mbox{\(l\)が出力層(\(l=L\))}\\ (\boldsymbol{W}^{(l+1)}[:, bias:])^T\boldsymbol{\mathcal E}^{(l+1)}\odot f’_l(\boldsymbol{U}^{(l)})&\mbox{\(l\)が中間層(\(l<L\))} \end{array}\right. \end{eqnarray}
※このMLPクラスをインスタンス化する際に、交差エントロピー誤差関数もしくは出力層にソフトマックス関数を使用したい場合は、セットで使ってください。
optim
# イプシロンを使用して重みを一括更新
def optim(self, eta):
for i in range(self.num_layers)[:-1]:
# 配列の指定方法に起因して示した計算式と若干異なる
self.w[i] -= eta * self.epsilon[i]@self.z_ex[i].T / self.batch_sizeoptimではbackwardにより計算された誤差イプシロンを使用して重みを更新します。
summary
def summary(self):
print('-'*60)
print('Layer-type\tOutput Shape\tParam\tactivation function')
print('='*60)
params = []
if self.bias==True:
print(f'Input\t\t[{self.num_neurons[0]-1}+bias, None]\t0')
for i in range(1, self.num_layers-1): # 入力層と出力層は含まない
params.append((self.num_neurons[i] - self.bias)*self.num_neurons[i-1])
print(f'Affine {i}\t[{self.num_neurons[i]-1}+bias, None]\t{params[-1]}\t{self.activation_function[i-1]}')
i += 1
params.append((self.num_neurons[i] - self.bias)*self.num_neurons[i-1])
print(f'Output\t\t[{self.num_neurons[i]-1}, None]\t{params[-1]}\t{self.activation_function[i-1]}') # 便宜上biasは非表示
else:
print(f'Input\t\t[{self.num_neurons[0]}, None]\t0')
for i in range(1, self.num_layers-1): # 入力層と出力層は含まない
params.append((self.num_neurons[i])*self.num_neurons[i-1])
print(f'Affine {i}\t[{self.num_neurons[i]}, None]\t{params[-1]}\t{self.activation_function[i-1]}')
i += 1
params.append((self.num_neurons[i])*self.num_neurons[i-1])
print(f'Output\t\t[{self.num_neurons[i]}, None]\t{params[-1]}\t{self.activation_function[i-1]}') # 便宜上biasは非表示
print('='*60)
print(f'Total Params:\t{sum(params)}')
print('-'*60)sammary関数は、Kerasでよく見るのを参考にしました。この関数を使用すれば、層数、各層のニューロン数、バイアスの有無、各層のパラメータ数、使用している活性化関数、総パラメータ数を確認することができます。
make_batch_data
def make_batch_data(self, x, t):
batch_x = []
batch_t = []
shuffle = np.arange(x.shape[1])
np.random.shuffle(shuffle)
x_ = x[:, shuffle]
t_ = t[:, shuffle]
if x.shape[1] == self.batch_size:
batch_x.append(x_)
batch_t.append(t_)
else:
for i in range(0, x.shape[1], self.batch_size):
if i+self.batch_size > x.shape[1]: # 最後に作成されるバッチのサイズが指定より小さい場合は切り捨てる
break
batch_x.append(x_[:, i:i+self.batch_size])
batch_t.append(t_[:, i:i+self.batch_size])
return batch_x, batch_tこの関数は、与えられたデータから、指定されたサイズのバッチデータを作成し、リストに格納します。6行目と7行目では、呼び出されるたびに異なるバッチデータが作成できるようにシャッフルしています。for文では、スライスを使って指定したバッチサイズのデータを抽出しています。それらは、リストに格納されます。
MSELoss
def MSELoss(self, x, t): # 平均二乗誤差
return np.mean((x-t)**2)CrossEntropyLoss
def CrossEntropyLoss(self, x, t): # 交差エントロピー誤差
return -(t*np.log(x+1e-8)).sum()xが限りなく0に近づいたときに発散しないよう、1e-8を足しています。
train
def train(self, x, t, epochs, batch_size, eta=0.01, warm_start=True):
if warm_start==False:
self.init_w() # 重みを完全に初期化
if self.status == 0: # はじめての学習かどうかで初期化の有無を判定
self.batch_size = batch_size
self.init_w()
self.init_z_ex()
self.init_epsilon()
else: # self.status = 1 既に学習開始済み
if self.batch_size != batch_size: # batch_sizeが異なればz_exとepsilonを初期化する必要あり
self.batch_size = batch_size
self.init_z_ex()
self.init_epsilon()
for epoch in range(epochs):
batch_x, batch_t = self.make_batch_data(x, t) # エポックごとにバッチデータを変更
for x_, t_ in zip(batch_x, batch_t):
self.zero_epsilon() # 前回計算したエプシロンを0に初期化
self.forward(x_)
self.backward(t_)
self.optim(eta)
loss = self.loss_dict[self.loss](self.z_ex[-1][self.bias:], t_)
self.history.append(loss)
return self.historytrain関数では、最初にwarm_startの値を確認し、warm_startがFalseなら重みを初期化、Trueなら先に進み、statusの値を確認します。もし、学習が行われていなければstatusは0なので、重み行列を初期化し指定のバッチサイズに合わせたz_exとepsilonの行列を定義&初期化します。もし、statusが1ならば重み行列は既に定義されているので再定義はしません。ただし、バッチサイズが変更されていたら、z_exとepsilonの行列サイズは変更しなければなりませんので、新たなバッチサイズを使って再定義します。ここまで準備が終わったら、指定されたエポック分だけ学習を実行します。学習の際は、各エポック毎にバッチデータを作成し、それをfor文で順番に抽出します。for文内部では、前の学習で計算した誤差イプシロンを0で初期化、forwardでz_exに各層の出力値を計算&格納、backwardでepsilonを計算、optimで全ての重み行列を更新、誤差関数の値を求めhistoryに追加、という処理を順に実行します。
predict
def predict(self, x):
self.batch_size = x.shape[1] # 入力データからバッチサイズを抽出
self.init_z_ex()
self.init_epsilon()
self.forward(x)
return self.z_ex[-1][self.bias:]predictでは、入力できるバッチサイズを柔軟に設定すべきなので、毎回z_exを初期化し、forward計算を実行します。ちなみに、epsilonの行列サイズを初期化する必要はないのですが、行列サイズの変更をz_exと連動させない場合、trainメソッド内のstatus=1のbatch_sizeによる条件分岐の処理が複雑になるため、冗長ではありますが初期化しています。あとは、forwardメソッドで値を計算し、バイアスニューロンを取り除いた部分を出力します。
完成したMLPクラス
作成したメソッドについての説明が済んだのでクラス全体を以下に載せます。
class MLP():
def __init__(self, num_neurons, activation_function, bias, loss):
self.num_neurons = np.array(num_neurons) + bias # biasがTrueなら各層にbiasニューロンを追加
self.num_layers = len(num_neurons) # 層数のカウント
self.bias = bias
self.loss = loss
self.w = [] # 層間の重み行列をリストで格納
self.z_ex = [] # 各層の出力をリストで格納
self.epsilon = [] # 各層のイプシロンを計算
self.history = [] # 学習過程として誤差関数の値を保持
self.status = 0 # 学習開始したかどうかのステータス(1は開始済み)
self.batch_size = None # batch_sizeを保持
self.activation_function = activation_function # 活性化関数をリストで保持
self.acf_dict = {'sigmoid':self.sigmoid, 'softmax':self.softmax, 'identity':self.identity, 'relu':self.relu} # 活性化関数のリスト
self.acf_der_dict = {'sigmoid':self.sigmoid_der, 'identity':self.identity_der, 'relu':self.relu_der} # 活性化関数とその導関数のリスト
self.loss_dict = {'MSELoss':self.MSELoss, 'CrossEntropyLoss':self.CrossEntropyLoss} # ここに誤差関数を格納
# 各層間の重み行列を標準正規分布で初期化する
def init_w(self): # MLPを定義したときに一度だけ実行する
self.w = [] # リストとして再度初期化
self.state = 0 # ステータスを未学習に変更
self.history = [] # 重みを初期化した際には、同時にhistoryも初期化
for i in range(self.num_layers)[:-1]:
self.w.append(np.random.randn(self.num_neurons[i+1] - self.bias, self.num_neurons[i]))
# バイアスニューロンを追加するか否かに応じて各層の出力サイズを考慮して格納用のリストを準備
def init_z_ex(self): # 主に、バッチサイズが変わったときに呼び出す。
self.z_ex = [] # リストとして再度初期化
for num in self.num_neurons:
self.z_ex.append(np.ones((num, self.batch_size))) # バイアスを考慮し全て1で初期化した行列を追加
# ==========活性化関数の定義==========
# シグモイド関数の定義
sigmoid = lambda self, x: 1/(1+np.exp(-x))
softmax = lambda self, x: np.exp(x)/np.exp(x).sum(axis=0) # ソフトマックス関数
identity = lambda self, x: x # 恒等関数
relu = lambda self, x: np.maximum(0, x) # ReLU
# ==========ここまで==========
# ==========活性化関数の導関数の定義==========
sigmoid_der = lambda self, x: x*(1-x) # xはシグモイド関数からの出力
identity_der = lambda self, x: np.ones(x.shape) # 恒等関数の導関数
relu_der = lambda self, x: np.where(x>0, 1, 0) # ReLUの導関数
# ==========ここまで==========
# 各重みを更新するためのイプシロンを格納するリストを定義&ゼロで初期化
def init_epsilon(self):
self.epsilon = []
for num in self.num_neurons[:-1]:
self.epsilon.append(np.zeros((num-1, self.batch_size)))
def zero_epsilon(self): # 前の学習時に計算したイプシロンを初期化
for eps in self.epsilon:
eps *= 0
def acf(self, activation_function, x): # 辞書から指定の活性化関数の値を返す
return self.acf_dict[activation_function](x)
def acf_der(self, activation_function, x): # 辞書から指定の活性化関数の導関数の値を返す
return self.acf_der_dict[activation_function](x)
# フォワード計算
def forward(self, x): # テストデータを入力できるようにする
self.z_ex[0][self.bias:,] = x # 入力データを拡張する
for i in range(self.num_layers)[:-1]:
# 配列の指定方法に起因して示した計算式と若干異なる
self.z_ex[i+1][self.bias:,] = self.acf(self.activation_function[i], self.w[i]@self.z_ex[i])
# 一括してすべての層のイプシロンを計算
def backward(self, t):
self.zero_epsilon() # 以前に計算したイプシロンの値をゼロで初期化する
# 出力層のイプシロンを計算
if(self.loss=='MSELoss'):
self.epsilon[-1] = (self.z_ex[-1][self.bias:] - t)*self.acf_der(self.activation_function[-1], self.z_ex[-1][self.bias:])
else: # 交差エントロピー誤差が指定されたら、出力層はほぼ確実にソフトマックス関数なので、ソフトマックス関数で計算
self.epsilon[-1] = (self.z_ex[-1][self.bias:] - t)
for i in range(-2, -self.num_layers, -1):
# 中間層のイプシロンの計算:シグモイド関数の微分アリ
self.epsilon[i] = self.w[i+1][:,1:].T@self.epsilon[i+1]*self.acf_der(self.activation_function[i], self.z_ex[i][self.bias:])
# イプシロンを使用して重みを一括更新
def optim(self, eta):
for i in range(self.num_layers)[:-1]:
# 配列の指定方法に起因して示した計算式と若干異なる
self.w[i] -= eta * self.epsilon[i]@self.z_ex[i].T / self.batch_size
def summary(self):
print('-'*60)
print('Layer-type\tOutput Shape\tParam\tactivation function')
print('='*60)
params = []
if self.bias==True:
print(f'Input\t\t[{self.num_neurons[0]-1}+bias, None]\t0')
for i in range(1, self.num_layers-1): # 入力層と出力層は含まない
params.append((self.num_neurons[i] - self.bias)*self.num_neurons[i-1])
print(f'Affine {i}\t[{self.num_neurons[i]-1}+bias, None]\t{params[-1]}\t{self.activation_function[i-1]}')
i += 1
params.append((self.num_neurons[i] - self.bias)*self.num_neurons[i-1])
print(f'Output\t\t[{self.num_neurons[i]-1}, None]\t{params[-1]}\t{self.activation_function[i-1]}') # 便宜上biasは非表示
else:
print(f'Input\t\t[{self.num_neurons[0]}, None]\t0')
for i in range(1, self.num_layers-1): # 入力層と出力層は含まない
params.append((self.num_neurons[i])*self.num_neurons[i-1])
print(f'Affine {i}\t[{self.num_neurons[i]}, None]\t{params[-1]}\t{self.activation_function[i-1]}')
i += 1
params.append((self.num_neurons[i])*self.num_neurons[i-1])
print(f'Output\t\t[{self.num_neurons[i]}, None]\t{params[-1]}\t{self.activation_function[i-1]}') # 便宜上biasは非表示
print('='*60)
print(f'Total Params:\t{sum(params)}')
print('-'*60)
def make_batch_data(self, x, t):
batch_x = []
batch_t = []
shuffle = np.arange(x.shape[1])
np.random.shuffle(shuffle)
x_ = x[:, shuffle]
t_ = t[:, shuffle]
if x.shape[1] == self.batch_size:
batch_x.append(x_)
batch_t.append(t_)
else:
for i in range(0, x.shape[1], self.batch_size):
if i+self.batch_size > x.shape[1]: # 最後に作成されるバッチのサイズが指定より小さい場合は切り捨てる
break
batch_x.append(x_[:, i:i+self.batch_size])
batch_t.append(t_[:, i:i+self.batch_size])
return batch_x, batch_t
def MSELoss(self, x, t): # 平均二乗誤差
return np.mean((x-t)**2)
def CrossEntropyLoss(self, x, t): # 交差エントロピー誤差
return -(t*np.log(x+1e-8)).sum()
def train(self, x, t, epochs, batch_size, eta=0.01, warm_start=True):
if warm_start==False:
self.init_w() # 重みを完全に初期化
if self.status == 0: # はじめての学習かどうかで初期化の有無を判定
self.batch_size = batch_size
self.init_w()
self.init_z_ex()
self.init_epsilon()
else: # self.status = 1 既に学習開始済み
if self.batch_size != batch_size: # batch_sizeが異なればz_exとepsilonを初期化する必要あり
self.batch_size = batch_size
self.init_z_ex()
self.init_epsilon()
for epoch in range(epochs):
batch_x, batch_t = self.make_batch_data(x, t) # エポックごとにバッチデータを変更
for x_, t_ in zip(batch_x, batch_t):
self.zero_epsilon() # 前回計算したエプシロンを0に初期化
self.forward(x_)
self.backward(t_)
self.optim(eta)
loss = self.loss_dict[self.loss](self.z_ex[-1][self.bias:], t_)
self.history.append(loss)
return self.history
def predict(self, x):
self.batch_size = x.shape[1] # 入力データからバッチサイズを抽出
self.init_z_ex()
self.init_epsilon()
self.forward(x)
return self.z_ex[-1][self.bias:]使い方
MNISTデータを使用したいので、Keira’s を使ってロードします。また、今回作成したMLPクラスで想定している入力行列および教師行列の形式に合うようにreshapeします。
from keras.datasets import mnist
from keras import utils #OneHot表現に変更する関数
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 適切な形状に形を変える
x_train = x_train.reshape((-1, 784)).T/255
x_test = x_test.reshape((-1, 784)).T/255
y_train = utils.to_categorical(y_train, 10).T
y_test = utils.to_categorical(y_test, 10).T次に、作成したMLPクラスをインスタンス化します。以下の例では、入力層と中間層、出力層からなる3層ニューラルネットワークで、それぞれのニューロン数は順に、784、1000、10個、使用する活性化関数は中間層がsigmoid、出力層はsoftmaxです。また、バイアスニューロンはありで、誤差関数には交差エントロピーを使います。
mlp = MLP(num_neurons=[784,1000,10],
activation_function=['sigmoid', 'softmax'],
bias=True,
loss='CrossEntropyLoss')サマリーを表示させてみます。
mlp.summary()を実行すれば、
------------------------------------------------------------
Layer-type Output Shape Param activation function
============================================================
Input [784+bias, None] 0
Affine 1 [1000+bias, None] 785000 sigmoid
Output [10, None] 10010 softmax
============================================================
Total Params: 795010
------------------------------------------------------------
が表示されます。
学習させてみましょう。その際に、historyをプロットしてみます。今回はepochs=10、batch_size=128、学習係数=0.01です。
hist = mlp.train(x_train, y_train, 10, 128, eta=0.01)
plt.plot(hist)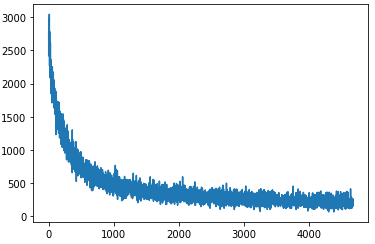
正解率を計算してみましょう。
results = np.argmax(mlp.predict(x_test[:,:100]), axis=0)
real = np.argmax(y_test[:,:100], axis=0)
print(f'正解率は{(results == real).sum()}%です.')正解率は82%です.正解率は、82%でした。あまり良い成績ではないですが、まあまあですね。
という感じになりました。ほかにも様々なサイズのニューラルネットワークが定義可能なので、いろいろ試してみようと思います。
あくまでも、多層パーセプトロンのクラス実装の一例という感じで見ていただけましたら幸いです。