
みなさんこんにちは!
当ブログ管理人です〜。TwitterやYouTubeもやってるので、ぜひフォローとチャンネル登録お願いします!
さて、本記事は、
自分のデータセットで転移学習したYOLOv5をiPhoneアプリに組み込みたいがCoreMLにする方法がわからない!
もしくは、
CoreMLにする方法は分かるけどNMS層がついていなくて結局使えない!
どうしたら良いんだ!
という方に向けた記事です。
私は、YOLOv5のカスタムモデルを作成し、CoreMLにエクスポートしてSwiftでiPhoneアプリを作成しましたが、その過程で大変苦労しました。数少ない情報を手がかりに色々試しても、エラーが発生するという状況で、何度も途中で投げ出したくなりました。
これに、3日ほど丸々溶かし、やっとの思いで実現したので、同じようなことに困っている方の助けになればと思います。
改めまして本記事では、カスタムのYOLOv5をNMS層とデコード層付きのCoreMLに変換する方法を再現性の高い方法で実現することができましたので、共有いたします。
手順は動画でも解説していますのでご活用ください。
YOLOv5をCoreMLにエクスポートするときの問題点とは?
ここでは、YOLOv5をCoreMLにエクスポートする際に生じる主な問題点について説明します。
まず、YOLOと言ったら、初代のYOLOとYOLOv3、YOLOv5が割と知られているかなと思います。近年では、YOLOv7なども出てきているようです。YOLOでもバージョンによっては性能があまり高くないこともあり、滅多に使用されなくなったモデルもあります。そのような中、未だYOLOv5は廃れることはなく広く用いられている印象を受けます。そして、当然ながら、YOLOv5をiPhoneで使用したいという需要もあります。YOLOv5はPyTorchで記述されていますが、iPhoneで使用するためには、そのままでは使用できないので、CoreMLと呼ばれる形式に変換する必要があります。GitHubなどで、YOLOv5のCoreML形式のファイルが見つかるので、既存のモデルで十分な場合は今回扱う内容は問題になりません。自分のデータセットで再学習したものを使用したい場合に問題になります。自分のデータセットで学習したモデルをCoreMLに変換するときは、変換プログラムを用いてエクスポートすることになりますが、公式が提供している変換プログラムでは、変換後のモデルにNMS層やデコード層が付与されないんです。YOLOの詳細な仕組みについては割愛しますが、NMS(Non Max Suppression :NMS)層とは、YOLOから出力された大量のバウンディングボックスから確信度の高い重要な出力のみを抽出する層です。これがないと、だた単に認識結果とバウンディングボックスについて整理されていない、無造作なデータが出力されるので使用できません。デコード層はNMS層からの出力を受け取り、クラスラベルとバウンディングボックスの対にした形式に変換する層です。これらが無いと、Swiftプログラムで使えません(SwiftでNMS層やデコード層を記述できれば良いですがモジュール性の低いプログラムになります)。ですがなんと嬉しいことに、ネットサーフィンをしていたら、NMS層とデコード層付きのエクスポートが可能な変換プログラムを見つけました。でも、エラーが発生してエクスポートできないな(泣)。YOLOv5のモデルでも、リポジトリのバージョン(YOLOのバージョンではない)によって、モデル構造が若干異なるらしく、変換に対応できるものと出来ないものがあるらしい。かつ、対応できるのはごく僅かだとか。大変困りましたね。
最終的に行き着いた方法は、変換プログラムが対応可能なYOLOv5のリポジトリのバージョンを特定し、そのDockerイメージを取得、そのコンテナの中でモデルを学習し、エクスポートするという流れです。
そこら辺の説明をしてきます。
環境構築
変換プログラム(Yolov5 CoreML Tool)が対応可能なYOLOv5のリポジトリのバージョンはv4.0です。従って、v4.0のYOLOv5のDockerイメージを取得します。以下のコードを実行して取得してください。
docker pull ultralytics/yolov5:v4.0コンテナの中で学習を行うため、コンテナからデータセットにアクセスできるように、datasetsフォルダをホストPC上に用意します。
後で、このフォルダにオリジナルのデータセットを配置します。datasetsフォルダを作成したら、コンテナを起動します。コードは以下の通りです。
mkdir datasets
docker run --ipc=host -p 5005:5005 -it -v "$(pwd)"/datasets:/usr/src/datasets --gpus all ultralytics/yolov5:v4.0gpuが使用できる方向けに、--gpus allを指定しています。また、5005ポートを用意しています。これは後の作業でJupyter notebookを使用するためです。Jupyter notebookは必ずしも必要というわけではありませんが、ファイルのアップロードやダウンロード、編集が簡単に行えるので使用します。
コンテナの中に入ったら、以下のコードを実行しておきましょう。以降で実行するコードは全てコンテナの中のターミナルもしくはJupyter notebookのセルで実行します。Jupyter notebookで実行する側には「# Jupyter」のコメントをセルの最初に記載しています。それ以外はコンテナのターミナルです。
apt update && upgrade -y次に、Jupyter notebookをインストールします。
apt install -y jupyter次に現在いるディレクトリの名前を変更します。具体的には、今/usr/src/appにいますが、appをyolov5に変更します。
cd ..
mv app yolov5また、CoreMLにエクスポートする際に必要となる変換プログラムをダウンロードします。エクスポートには、Yolov5 CoreML Toolsを使用するのでgithubからcloneしてきます。
cd /usr/src
git clone https://github.com/dbsystel/yolov5-coreml-tools.git
# yolov5-coreml-toolsフォルダの中にmodelsフォルダを作成
mkdir -p yolov5-coreml-tools/modelsここまでの作業が終わったら、Jupyter notebookを起動します。
今回は、先ほどコンテナを起動するときに指定したポート(5005)を指定しJupyter notebookを起動します。
cd /usr/src
jupyter notebook --port 5005ターミナルに表示されたURLをコピーしてブラウザに張り付けましょう。ちゃんとアクセスできると、以下のような画面が開くと思います。
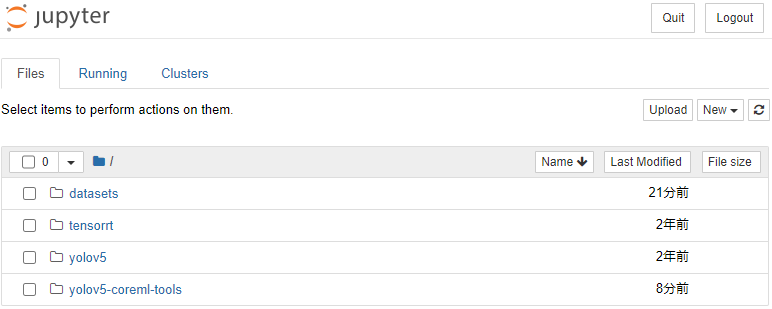
右上の「New▾」からPython3の新しいノートブックを開きます。名前がUntitledになっているので、Custom YOLOv5 Model for CoreMLとでもしておきましょう。
そうしたら、セルの部分に以下のコードを張り付けて実行します。以下は、yolov5にsetup.pyを追加するコードです。setup.pyはyolov5の公式リポジトリのIssuesで公開されています。
%%writefile /usr/src/yolov5/setup.py
from setuptools import setup
setup(
name="yolov5",
url="https://github.com/ultralytics/yolov5",
maintainer="ultralytics",
maintainer_email="glenn.jocher@ultralytics.com",
packages=["models", "utils"],
install_requires=["opencv-python", "matplotlib", "torchvision", "PyYAML", "requests", "pandas", "seaborn"],
)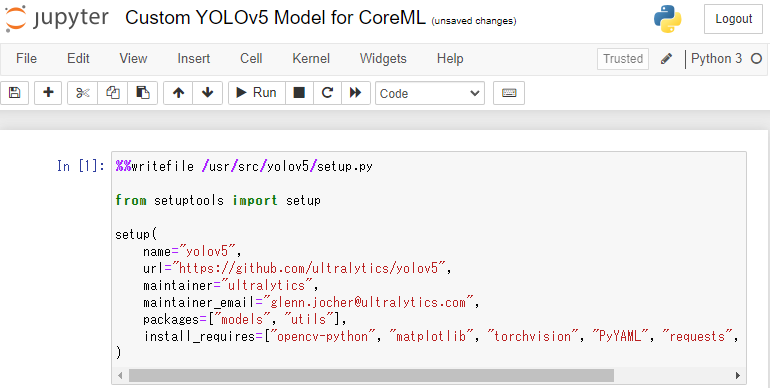
これを実行すると、yolov5フォルダの直下にsetup.pyが作成されます。
以上でYOLOv5の学習とCoreMLへのエクスポートのための準備は終わりです。
データセットの作成
ここでは、YOLOv5のオリジナルモデルを得るために必要なデータセットについて、そのディレクトリ構造とdata.yamlの作成について説明します。
データセットのディレクトリ構造
YOLOのv5の学習で扱えるデータセットのディレクトリ構造は下図の通りです。

データセット名のフォルダを作成し、その直下にtrainとtestフォルダを作成します。それぞれのフォルダ直下にimagesとlabelsフォルダを作成します。imagesフォルダの直下には画像データを、labelsフォルダの直下にはアノテーションデータを配置します。さらに、データセット名のフォルダ直下にあるdata.yamlには、データセットの構造と、扱うクラス名などを記載します(以降で説明)。
作成手順は以下の通りです。
- 上図のようにデータセット名のフォルダ、trainとtestフォルダ、imagesとlabelsフォルダを作成
- 用意した画像ファイルをtrain/imagesフォルダとtest/imagesフォルダの中に適切な割合で配置
- train/imagesフォルダとtest/imagesフォルダの中の画像についてアノテーションツールでラベリング
(追記)最もお勧めのラベリングツールはlabelImgです。labelImgでは画像が格納されているフォルダとアノテーション情報を格納するフォルダを指定できるので適切に指定してください。 - data.yamlを作成
※アノテーション情報を表すテキストファイルは、アノテーションツールにより自動で生成され、そのファイル名は対応する画像のファイル名と同じです。例えば、train_1.jpgのバウンディングボックス情報を表すのはtrain_1.txtです。
本記事では具体的なデータセットの作成は省略しますが、YouTubeの動画では解説しているので、気になる方はご覧ください。
data.yamlの中身
画像データとアノテーション情報を適切に配置したら、最後にdata.yamlを作成する必要があります。data.yamlは以下のような内容になっています。trainデータ、validデータ、testデータの画像のパス、クラス数とクラスラベルを記載します。
※以下の例ではtrainとvalidを同じにしています。
train: /usr/src/datasets/データセット名/train/images/
val: /usr/src/datasets/データセット名/train/images/
test: /usr/src/datasets/データセット名/test/images/
nc: 〇〇
names: ["クラス名1", "クラス名2", "クラス名3", ・・・]今回は、iPhoneで使用可能なCoreMLモデルを作成することが目標であり、学習の際には公式が提供するDockerを使用し、そこにdatasetsフォルダをマウントして使用するので、その構造に従って記載しました。datasetsフォルダの下には様々な種類のデータセットを配置することが考えられるので、このようにしています。画像データのパスさえ記載しておけば、imagesをlabelsに置き換えてアノテーション情報を自動で読み込んでくれます。
また、認識するクラスの数とクラス名も記載して下さい。クラス名のリストに記載する順番は、labelImgでアノテーションした際に作成されたclasses.txtに記載された通りの順番とします。
データセットの配置
データはホストPCのdatasetsフォルダの直下に配置しておきましょう。
学習
一部プログラムの編集
google_utils.pyの編集
Jupyterでutils/google_utils.pyを開き、attempt_download関数の
response = requests.get('https://api.github.com/repos/ultralytics/yolov5/releases/latest').json() # github api
を
response = requests.get(f'https://api.github.com/repos/ultralytics/yolov5/releases/35978533').json() # github api
に書き換えます。
common.pyの編集
Jupyterでmodels/commom.pyを開き、プログラムの最後に以下のSPP層の記述を追加します。
class SPPF(nn.Module):
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))学習の実行
学習を実行します。今回は、COCOデータセットで事前学習された重みをロードして再学習を行います。以下のコマンドをJupyter notebookのセルにコピペし、データセットのところは臨機応変に書き換えて実行して下さい。また、バッチサイズやエポック数も必要に応じて変更してください。batchはGPUの数だけしか指定できないようです。16個積んでいればデフォルトの16で動くと思います。
# jupyter notebook
!python yolov5/train.py --batch 3 --epochs 300 --cfg models/yolov5s.yaml --weights yolov5s.pt --data /usr/src/datasets/〇〇/data.yaml一回で学習がうまくいかずにコンテナを作り直したりしていると、_pickle.UnpicklingError: STACK_GLOBAL requires str
のようなエラーが発生することがあります。このような場合は、データセットの中に自動的に作成されたlabels.cacheを削除すると解決します。おそらく、以前に作成されたものが悪さしているものと思われます。
学習が終了すると、最終的な重みが保存され、そのパスが表示されます。

私の場合、runs/train/exp18/weights/best.ptが学習で得られた重みの中で最も精度が高かったものです。以降で使用するので覚えておきましょう。
学習結果の確認(テストデータで推論を確認してみる)
学習が終わったら、学習結果を確認してください。以下は、テストデータで推論するコード例です。best.ptのパスは上で確認したものに変更してください。〇〇の部分には、テストデータが格納されているフォルダもしくはファイルのパスを指定します。フォルダを指定した場合は、フォルダ内のすべてのファイルについて推論が実行されます。ファイルを指定した場合は、指定したもののみが実行されます。
!python yolov5/detect.py --weights runs/train/exp/weights/best.pt --conf 0.3 --source 〇〇CoreML形式へエクスポート
重みファイルを指定のフォルダへ
次に、上で作成したmodelsフォルダの中にbest.ptをコピーします。以下のコードのbest.ptのパスは私の場合ですので、ご自身の場合に変更して実行してください。
# jupyter notebook
# best.ptをmodelsフォルダの中にコピーし名前をyolov5s_v4.ptに変更
!cp runs/train/exp18/weights/best.pt /usr/src/yolov5-coreml-tools/models/yolov5s_v4.ptmain.pyの編集
yolov5-CoreML Toolsにあるmain.pyの315行目のmodel.eval()をmodel.train()に書き換えます。
また、main.pyをjupyter notebookから開いた時の以下のようなセルを、ご自身の環境に合わせて変更してください。すなわち、
- [f"label{i}" for i in range(80)] → ["クラス名1", "クラス名2", "クラス名3", ・・・]
に変更します。

エクスポート
ホストPCで新たにターミナルを開き、先ほど作業してきたコンテナの中に入ります。以下のコマンドで入れます。
# ホストPCで新たにターミナルを開き実行
docker exec -it -w /usr/src コンテナID bashコンテナのターミナルに入ったら、以下のコマンドを実行して下さい。
# poetryを使用して必要なものをインストール
cd yolov5-coreml-tools
pip3 install poetry==1.2.1 # yolov5-coreml-toolsで使用
poetry install
cd ..
cd /usr/src/yolov5-coreml-tools/
poetry run coreml-exportエラーなく実行が終了すれば、無事にCoreMLモデルの生成ができました。jupyter notebookのファイルマネージャーから該当するモデルをダウンロードしてください。
以上でYOLOv5のオリジナルモデルの作成とエクスポートは終了です。
Dockerfileを活用して上の作業を自動ビルド
上の作業を毎回行うのは、結構面倒です。そこで、Dockerfileから自動的にビルドできるように、Dockerfileを作成しました。ぜひご利用下さい。
以下のDockerfileをコピーしてDockerfileとして保存してください。
FROM ultralytics/yolov5:v4.0
RUN apt-get update && apt-get upgrade -y
RUN apt-get install -y python3-pip git
RUN pip install jupyter
RUN cd /usr/src && \
git clone https://github.com/dbsystel/yolov5-coreml-tools.git && \
mkdir -p yolov5-coreml-tools/models
# setup.pyの作成(/usr/src/app/setup.py)
RUN echo "from setuptools import setup" >> /usr/src/app/setup.py
RUN echo "setup(" >> /usr/src/app/setup.py
RUN echo " name='yolov5'," >> /usr/src/app/setup.py
RUN echo " url='https://github.com/ultralytics/yolov5'," >> /usr/src/app/setup.py
RUN echo " maintainer='ultralytics'," >> /usr/src/app/setup.py
RUN echo " maintainer_email='glenn.jocher@ultralytics.com'," >> /usr/src/app/setup.py
RUN echo " packages=['models', 'utils']," >> /usr/src/app/setup.py
RUN echo " install_requires=['opencv-python', 'matplotlib', 'torchvision', 'PyYAML', 'requests', 'pandas', 'seaborn']," >> /usr/src/app/setup.py
RUN echo ")" >> /usr/src/app/setup.py
# gle_utils.pyの一部書き換え
RUN sed -i 's/https:\/\/api.github.com\/repos\/ultralytics\/yolov5\/releases\/latest/https:\/\/api.github.com\/repos\/ultralytics\/yolov5\/releases\/35978533/g' /usr/src/app/utils/google_utils.py
# SPP層の追加(/usr/src/app/models/common.py)
RUN echo "class SPPF(nn.Module):" >> /usr/src/app/models/common.py
RUN echo " # Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher" >> /usr/src/app/models/common.py
RUN echo " def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))" >> /usr/src/app/models/common.py
RUN echo " super().__init__()" >> /usr/src/app/models/common.py
RUN echo " c_ = c1 // 2 # hidden channels" >> /usr/src/app/models/common.py
RUN echo " self.cv1 = Conv(c1, c_, 1, 1)" >> /usr/src/app/models/common.py
RUN echo " self.cv2 = Conv(c_ * 4, c2, 1, 1)" >> /usr/src/app/models/common.py
RUN echo " self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)" >> /usr/src/app/models/common.py
RUN echo " def forward(self, x):" >> /usr/src/app/models/common.py
RUN echo " x = self.cv1(x)" >> /usr/src/app/models/common.py
RUN echo " with warnings.catch_warnings():" >> /usr/src/app/models/common.py
RUN echo " warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning" >> /usr/src/app/models/common.py
RUN echo " y1 = self.m(x)" >> /usr/src/app/models/common.py
RUN echo " y2 = self.m(y1)" >> /usr/src/app/models/common.py
RUN echo " return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))" >> /usr/src/app/models/common.py上記のDockerfileからビルドするときは以下のコマンドを使用してください(Dockerfileのある階層で実行します)。
docker build . -t yolov5:coremlビルドが終了したら、以下のコマンドを実行して、コンテナを起動します。
mkdir datasets
docker run --ipc=host -p 5005:5005 -it -v "$(pwd)"/datasets:/usr/src/datasets --gpus all yolov5:coremlコンテナの中に入ったら、以下のコマンドを実行してください。
cd ..
mv app yolov5
cd /usr/src
jupyter notebook --port 5005ブラウザでJupyter Notebookを起動して、Custom YOLOv5 Model for CoreMLという名前に変更します。
学習を実行します。
# jupyter notebook
!python yolov5/train.py --batch 3 --epochs 300 --cfg models/yolov5s.yaml --weights yolov5s.pt --data /usr/src/datasets/〇〇/data.yaml学習が終わったら、本記事の「CoreML形式へエクスポート」以降を実行して、作成したCoreMLモデルを抽出しましょう。
以上です。お疲れさまでした。