
BipedalWalker環境を使ってみた!
本記事は、当サイトのYouTubeチャンネルで公開している動画「[Weekly RL with code]簡易的な二足歩行ロボットの学習環境を試してみた!」の内容を文字に書き起こしたものです。記載内容は動画と同じです。動画もしくは記事の、お好みの媒体で強化学習について学ぶことができます。
※ Weekly RL with codeは、当サイトがコード付きで強化学習の話題を毎週発信するシリーズです。動画はYouTubeで公開しています。ぜひご覧ください。
今回の内容
今回のWeekly RL with codeのテーマは、簡易的な二足歩行ロボットの学習環境であるBipedalWalker環境を試すというものです。今回は、強化学習の説明はせず、BipedalWalker環境の説明と、Stable Baselines3と呼ばれる強化学習ライブラリのPPOと呼ばれる学習アルゴリズムで学習してみるという内容がメインとなります。

まず最初に、BipedalWalker環境の概要を、その後に、状態・行動・報酬・初期分布と終了条件について説明し、Stable Baselines3のPPOを用いて学習をしてみます。
コードはgoogle colaboratoryで実行します。今回扱ったコードはノードブック形式で公開していますので、ぜひご利用ください。リンクは概要欄に記載の通りです。
公開しているノートブックには、複数のアニメーションと、TensorBoardがセルに表示された状態のもので容量が大きいため、ダウンロードの際は注意してください。重いため、GitHubでプレビューされませんので、一旦ダウンロードしてからGoogle Driveにアップロードしてお使いください。
BipedalWalker環境の概要
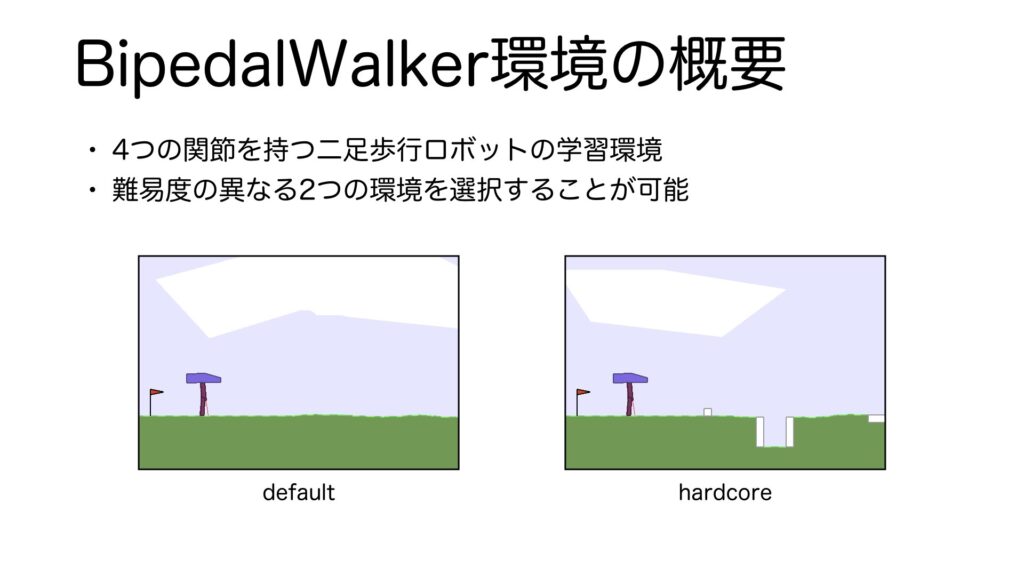
それではBipedalWalker環境について説明をします。BipedalWalker環境とは、4つの関節を持つ簡易的な2足歩行ロボットの学習環境です。2つの難易度の異なるシーンが用意されていて、デフォルトでは、左のような平坦なシーン、hardcoreを指定すると岩や穴、階段などがあるシーンで学習することができます。あとでコードを実行するときに両方の環境を学習させてみますので楽しみにしていてください。それでは、この環境の、状態、行動、報酬、初期分布、エピソード終了条件について説明していきます。これらはマルコフ決定過程に則ったときの構成要素で、マルコフ決定過程については前回のWeekly RL with codeで説明していますので概要を知りたい方は、そちらも合わせてご視聴ください。
状態
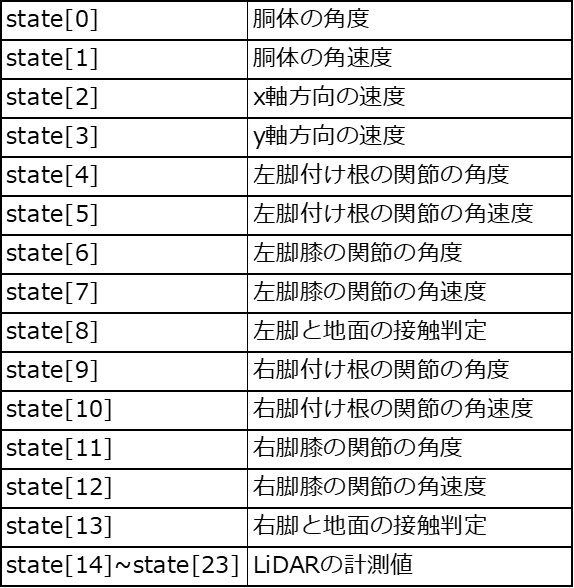
状態は、24個の要素を持つ配列になっています。詳細は以下の表のとおりです。大まかに説明すると、胴体の傾きと速度、各関節の角度と角速度、接触判定、LiDARの計測値となっていて、センサーから取得可能なデータが用いられています。
行動
行動は、4つの関節の回転速度を表す配列です。-1から1の範囲の値で速度を指定します。
報酬
報酬は以下に示すとおりです。表には、報酬の各項目と、その値、それに乗算される重み係数、そしてどのような働きをしていると考えられるかを記載しています。
正の報酬は直前のステップから前進した距離の差分に、重み係数を乗算したもののみとなっています。それ以外は、負の報酬として作用します。胴体が大きく回転すると転倒する可能性が高くなるだけでなく、無駄な動きが多くなり好ましくないため、その回転に対して負の報酬が与えられます。また、関節の回転速度にトルクを乗算し全ての関節について加算した値に係数を掛けたものが負の報酬として与えられます。これは、無駄な動作を抑えることで自然な歩行の獲得を促していると考えられます。とはいえ、係数の値はとても小さいため、あくまでも可能な範囲でエネルギー消費を抑えればよいことが分かります。その他、エピソード終了条件である、胴体位置が範囲外の場合やゲームオーバーになった場合について、-100の大きな負の報酬が与えられます。

初期分布と終了条件
前回のWeekly RL with codeで扱ったCartPole環境は、状態をリセットするたびに一様分布に従って確率的に状態がセットされていましたが、BipedalWalker毎回ほぼ同じ状態からスタートします。env.reset()を実行するたびに得られる状態配列は毎回若干異なりますが、ソースコードを読む限り確率分布は使われていないので、物理エンジンに起因するものかもしれません。基本、ほぼ同じ状態と思っていただいて大丈夫です。
終了条件は、
- 胴体が地面に接触した場合
- 右端まで歩きぬいた場合
- 範囲外へ移動した場合
- ゲームオーバーになった場合
です。
コードの実行
まずはBipedalWalker環境を使えるようにします。また、強化学習ライブラリとしてStable Baselines3を使用します。以下のコードを実行して下さい。
%%bash
pip install gym[Box2D] # BipedalWalker環境を含むBox2DのGym環境のインストール
pip install stable-baselines3 # 強化学習ライブラリのインストール
pip install pyglet==1.5.27
git clone https://github.com/aakmsk/gymvideo.gitインストールが済んだら、必要なものをインポートします。
import gym
from stable_baselines3 import PPO
from gymvideo.scripts.gymvideo import GymVideoランダムに行動したときの動作を確認してみます。
env = gym.make("BipedalWalker-v3")
env = GymVideo(env)
env.reset()
done = False
while done != True:
obs, reward, done, info = env.step(env.action_space.sample(), monitor_frames=True)
env.save_video(save_name="random_action.gif", display_inline=True)それでは、実際に学習を行ってみて、どのような動作が獲得されるか確かめてみたいと思います。1万ステップの学習をしてみましょう。
total_timesteps = 10000 # 1万ステップ
model = PPO("MlpPolicy", env, verbose=1)
model.learn(total_timesteps=total_timesteps)
env.execute_one_episode(model)
env.save_video(save_name="10000_bipedalwalker.gif", display_inline=True)学習が足りないようなので、同様のコードを用いて学習ステップ数を増やしてみましょう。
10万ステップの学習後は以下のようになりました。
100万ステップの学習後は以下のようになりました。
500万ステップの学習後は以下のようになりました。
10万ステップ程度でも歩行できており、100万ステップの学習結果と比べても違いがあまりありませんが、500万ステップの学習結果はそれらと比べてゴールまでの時間が短いようです。効率の良い歩行方法を見つけたのかもしれませんね。
この記事では、これ以上の学習ステップ数は試しませんが、気になる方は試してみると良いかもしれません。より効率的で早くゴールできる歩行を学習してくれるかもしれませんね。
最後に、hardcoreバージョンも試してみようと思います。以下のコードを実行してみてください。
env = gym.make("BipedalWalkerHardcore-v3")
env = GymVideo(env)
total_timesteps = 5000000 # 500万ステップ
# 学習結果をTensorBoardで表示する
logs_base_dir = "."
model = PPO("MlpPolicy", env, verbose=1, tensorboard_log=logs_base_dir)
model.learn(total_timesteps=total_timesteps)学習後のモデルで1エピソードを実行すると以下のようになりました。歩かなくなってしまっています。ここである仮説が立てられます。それは、石に躓いたり穴にはまってエピソード終了になることを避けて、歩かない選択を学習した可能性です。もし、この仮説が正しいとすれば、報酬設計を見直す必要があるかもしれません。
今回は、これは紹介程度にとどめますが、いつかリベンジしてhardcoreのBipedalWalker環境を歩きぬけるようにしたいと思います。
まとめ
今回は、BipedalWalker環境について概要を説明し、実際にコードをしようして遊んでみました。
BipedalWalker環境はデフォルトとhardcoreの2種類があることを知ることができれば今回の内容としてはOKではないでしょうか。
動画は以上になります。今後も、週1でWeekly RL with codeを公開していきますので、ぜひチャンネル登録をよろしくお願いいたします。
最後までお読みいただきありがとうございました。