
はじめに
皆さんは、日常生活の中で、視覚や聴覚、触覚など、さまざまな感覚を同時に使って情報を処理しています。これは、人間が複数の感覚情報を統合的に知的処理している、いわゆる「マルチモーダル[1]」な処理を行っているということです。

しかし、現在の機械学習モデルはどうでしょうか。それぞれの感覚情報、つまり「モダリティ」に対して特化したモデルが一般的です。例えば、画像というモダリティを扱うのは畳み込みニューラルネットワーク(Convolutional Neural Network: CNN)、音声というモダリティを扱うのは再帰型ニューラルネットワーク(Recurrent Neural Network: RNN)といった具体的なモデルがあります。これらはそれぞれのモダリティに特化した形で処理を行い、その結果を統合するというマルチモーダルな処理はあまり行われていません。
これはなぜでしょうか。それは、各モデルが特定のモダリティに対する「帰納バイアス[2]」が高いからです(帰納バイアスについては後述)。つまり、各モデルは特定のモダリティに対する法則を学習することに特化しており、その結果、異なるモダリティ間で情報を統合的に処理する能力が低いのです。
人間のような知能を機械学習モデルに実現させるためには、この問題を解決する必要があります。つまり、画像であろうと音声であろうと、どのモダリティでも同じアーキテクチャで高精度な処理が可能な、帰納バイアスの低いモデルが求められているのです。
そこで今回ご紹介するのが「Perceiver[3]」です。Perceiverは、モダリティに依存せずに高精度な処理が可能なモデルを実現しました。ただし、注意していただきたいのは、Perceiverがマルチモーダルなモデルであるわけではないという点です。マルチモーダルかどうかは、どのタスクを解かせるかに依存します。Perceiverの重要な点は、マルチモーダルなAIに先駆けて、モダリティへの依存の少ないアーキテクチャで高精度が出せるモデルが実現できることを示したところにあります。これにより、マルチモーダルなAIの研究が一気に広がったと言えるでしょう。
本記事では、このPerceiverについて、初心者の方でも理解しやすいように詳しく解説していきます。
帰納バイアスとモデルの柔軟性
帰納バイアス
帰納的バイアスとは、学習モデルの学習と推論のプロセスに反映された、データの分析に基づく推測や仮定のことを指します。これは「おそらくこうだろう」という帰納的な仮定が学習モデルのアーキテクチャに反映され、バイアスのかかった結果を生み出すことから来ています。データの特性や傾向に対する事前の仮定がモデル設計に反映される形で存在します。
畳み込みニューラルネットワーク(CNN)や再帰型ニューラルネットワーク(RNN)は帰納バイアスの高い典型的なニューラルネットワークの例として挙げられています。CNNは、画像データに対する空間的な位置関係の仮定を持つことで、局所的な特徴を捉えるフィルタ構造を持っています。一方、RNNは、系列データに対する時間的な位置関係の仮定を持つことで、系列の順序的な特徴を捉える再帰性を持っています。これらの特性は、モデルが学習によって獲得するものではなく、分析対象のデータに対する仮定から派生したアーキテクチャによるものです。
帰納バイアスについては以下の記事で詳しく説明しています。
モデルの柔軟性
帰納バイアスは、特定の分野で高いパフォーマンスを達成するための効果的な手法です。これは特に、利用可能な学習データが少ない場合に有用です。学習データが不足している状況では、帰納バイアスが少ないモデルの学習は難しい一方、既に特定のドメイン向けにモデル構造が定義されている、つまり帰納バイアスが高いモデルでは、少しのパラメータ調整だけで高い精度を達成できます。
しかし、帰納バイアスが高いモデルには欠点もあります。それらのモデルは特定の分野に特化して設計されているため、異なる種類のデータを同時に処理することが困難です。このような多様なデータを扱う能力は、帰納バイアスが低いモデルが得意とするところです。
現在は大量のデータを取得し学習に利用できる時代になりました。そのため、必ずしもモデルに高い帰納バイアスを設ける必要性は低くなったと言えます。たとえば、画像データを扱う場合でも、必ずしも畳み込みニューラルネットワーク(CNN)を使用する必要はありません。異なる種類のデータも同時に扱うことができる、柔軟性の高いTransformer[4]のようなモデルを用いることも可能なのです。
Perceiverのアーキテクチャ
概要
Perceiverは、帰納バイアスが低く、それでいて高性能なモデルを目指して設計されました。そのため、その構成要素となる各層も、帰納バイアスが低いものが選ばれています。帰納バイアスの低い層として代表的なものに、フィードフォワードネットワーク(Feed-Forward Network: FFN)層やAttention層、そして、これらFFN層とAttention層を組み合わせて作られるTransformer層などがあります。
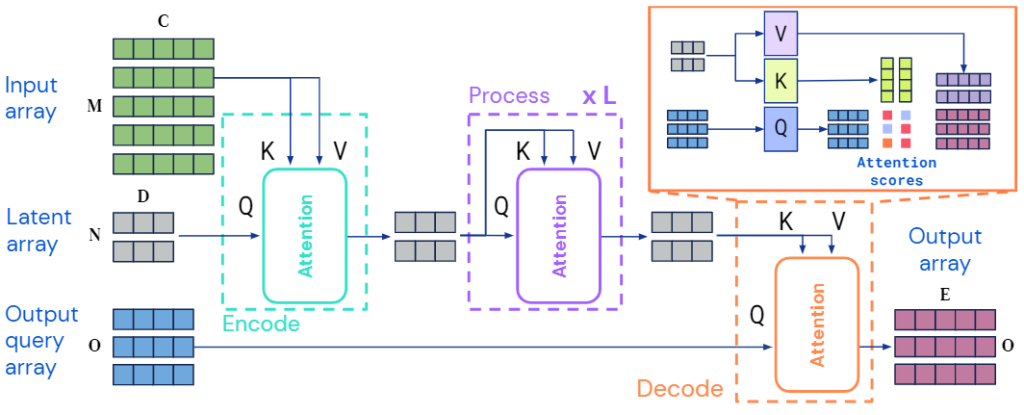
Perceiverは、具体的には「Cross Attention層」と「Latent Transformer層」で構成されています。ここで、Cross Attention層とは、元祖TransformerにおいてSourceTarget Attentionと呼ばれる部分を指します。また、Latent Transformer層は、Transformer層そのものを指します(厳密にはGPT-2[5]が用いられている)。Latentが付くのは潜在ベクトルの変換を担っているからだと考えられます。そして、これらの層を組み合わせて1つのブロック構造を作り、それを再帰的に処理する構造となっています。つまり、Perceiverは、これらのブロックを繰り返し適用することで、様々なモダリティのデータを高精度に処理することが可能となっているのです。
Perceiverの構造は以下の図の通りです。
※以下の図では、再帰する度に呼び出されるCross AttentionとLatent Transformerの重みを共有していますが、共有しない方法も考えられます。その場合のPerceiverの構造は、原論文に記載された通りの図になります。
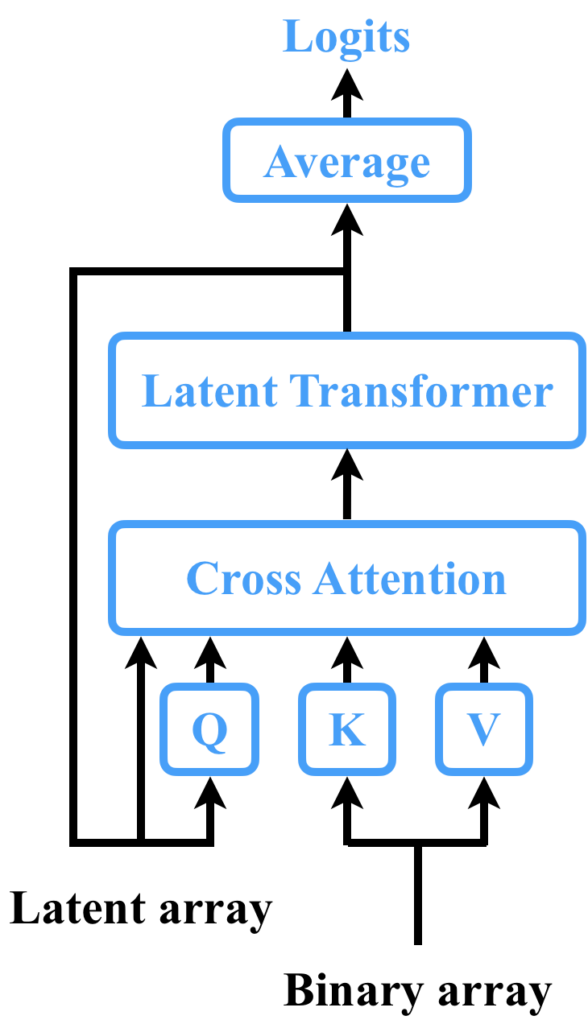
Perceiverの出力は「Logits」と呼ばれるもので、これは基本的にはクラス分類で使用されます。クラス分類とは、あるデータがどのカテゴリに属するかを判断するタスクのことで、例えば、画像が犬の画像なのか、猫の画像なのかを判断することなどがあげられます。裏を返せば、画像を生成したり文章を生成したりするようなことはできないということです。後で紹介しますが、これを解決するために、出力側でもそういった複雑なモダリティを扱えるようにするために提案されたのがPerceiver IO[6]です。
ここで、「Latent array」と「Byte array」について説明しましょう。まず、「Latent array」は「潜在配列」と訳すことができます。これは、Perceiverが内部で情報を格納するための配列で、中間表現として機能します。PerceiverはこのLatent arrayをRNN(再帰型ニューラルネットワーク)のように扱い、情報を格納していきます。次に、「Byte array」は「バイト配列」と訳すことができます。この用語からは具体的な入力を想像しにくいかもしれませんが、例えば画像のピクセル配列などを想定しています。つまり、Byte arrayは入力データで、これをPerceiverは処理していきます。
Cross Attention
Perceiverの中心的な機構である「Cross Attention」について詳しく説明していきましょう。
まず、Attentionとは何かを理解するために、その基本的な機能をおさらいします。Attentionは、入力された情報の中から重要な部分に焦点を当てるための機能です。これは、Query、Key、Valueという3つの要素を使って行われます。具体的な処理の手順は以下の通りです。
- 各Queryに対して、全てのKeyと内積を計算して、それぞれのKeyとの類似度が導出されます。
- これらの類似度は、対応するValueの線形結合をする際の重みとして使用されます。そして、各Queryに対する最終的な出力は、これらのWeighted Valueの合計になります。出力の系列長はQueryの系列長と同じになります。
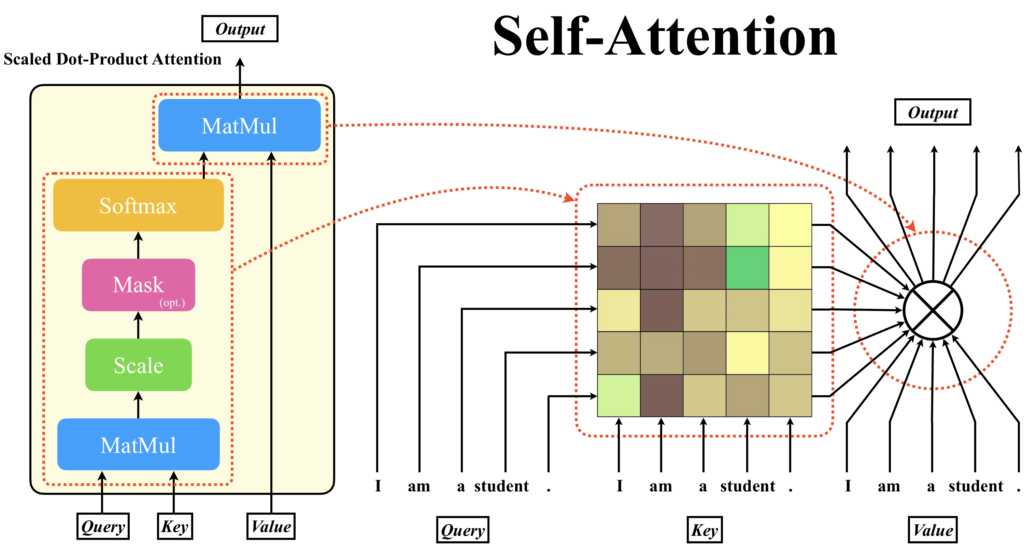
Attentionには、主にSelf-AttentionとCross Attention(SourceTarget Attention)の2種類があります。Self-AttentionではQuery、Key、Valueに入力されるデータは同じですが、Cross Attentionの場合は、KeyとValueに入力されるデータが同じとなっています。入力の性質からSelf-Attentionはシングルモーダルな処理しか行えませんが、Cross Attentionはマルチモーダルな処理を行うことが可能です。
以下は、Attentionの最小単位であるScaled Dot-Product Attentionを例に、Self-Attentionのデータの流れをテキスト系列を例にあげて表したものです。Self-Attentionは、Query, Key, Valueの全ての入力が同じものを指します。つまり、自分自身で自分自身を変換するという操作を行います。出力の系列長はQueryの系列長で決まり、ベクトルのサイズはValueのベクトルのサイズで決まります。つまり、全てが同じということは、自分自身に対して自分自身でクエリをかけて、自分自身を変換する操作になります。これは、PerceiverのLatent Transformer部分で使用されています。
一方、Cross AttentionではQueryの入力と、KeyおよびValueの入力が異なります。出力はValueに入力されたベクトルの重み付き和であり、出力の系列長はKeyとして入力されたデータの系列長と同じです。したがって、Queryが1単語分しかなければ、出力されるのは1単語分です。ここに、潜在配列をQueryに入力する理由が隠れています。RNNは同じ処理ブロックを何度も適用するため、入力される潜在配列のサイズと出力される潜在配列のサイズは同じでなければなりません。
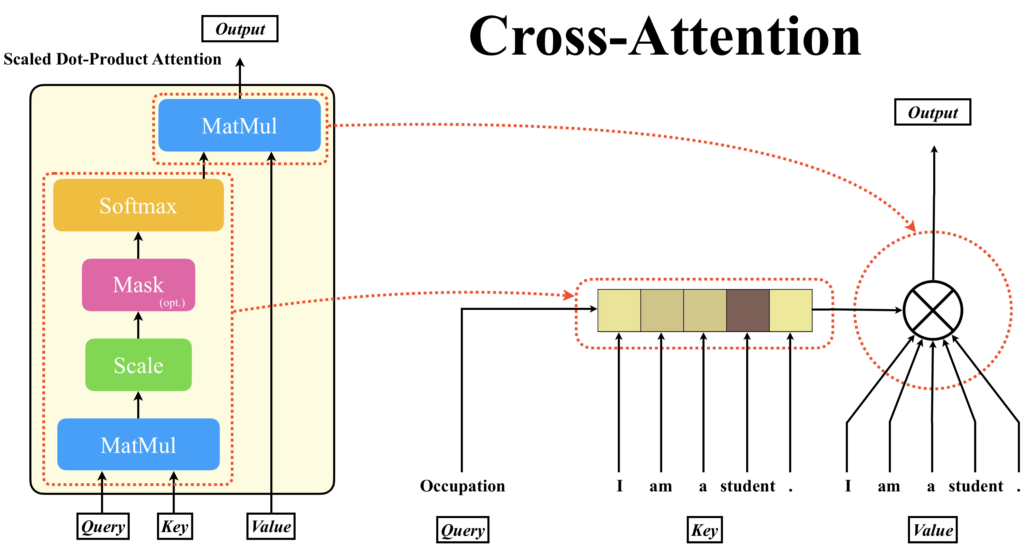
ここでは、説明を分かりやすくするためにQueryにもテキスト系列を用いていますが、PerceiverにおいてQueryは潜在表現されたベクトルの配列です。この潜在配列のサイズはハイパーパラメータであり、最初にランダム値で初期化されます。
Latent Transformer
Latent Transformerには、GPT-2アーキテクチャが使用されています。まず、GPTアーキテクチャとは、ある系列を入力として受け取り、その次に続く系列を予測するように学習が行われています。GPTシリーズには、2023年の時点で1~4まであり、これらはOpenAIによって開発されています。GPT-1[7]については以下の記事で解説しています。
そして、PerceiverのLatent Transformerで使用されたのは、GPTシリーズの2世代目であるGPT-2ということです。GPT-1とGPT-2、より新しいGPTシリーズの主な違いはモデルのサイズになります。
Perceiver IO
Perceiverの出力はLogitsであるため、画像や動画、音声などの多種多様なモダリティの出力には直接対応することができません。しかし、この問題を解決するために、Perceiver IOというモデルが提案されました。ここでは、Perceiver IOについて詳しくは説明しませんが、基本的な考え方はPerceiverと同じであり、一番注目すべきところは出力部分です。すなわち、出力の直前にCross Attention層を追加し、潜在表現をKeyとValueに、QueryにはOutput query arrayを入力するようにしています。潜在配列をそのままOutput arrayにする方法も考えられますが、Perceiver IOではあえてOutput query arrayを使用することで、出力を柔軟に変えることができるようにしています。これにより、画像や音声、動画などの様々なモダリティの出力に対応することが可能となりました。
このように、Perceiver IOはPerceiverの基本的なアーキテクチャを拡張し、多種多様なモダリティの出力に対応することを可能にしました。
まとめ
この記事では、人間が複数の感覚情報を統合的に処理する「マルチモーダル」な処理と、それを機械学習モデルで実現するための「Perceiver」および「Perceiver IO」について詳しく解説しました。
以下に簡単に内容をまとめます。
まず、人間は視覚や聴覚、触覚など、さまざまな感覚を同時に使って情報を処理します。これに対し、現在の機械学習モデルはそれぞれの感覚情報、つまり「モダリティ」に対して特化したモデルが一般的で、異なるモダリティ間で情報を統合的に処理する能力が低いです。これを可能にするには、帰納バイアスの低い高性能なモデルを作る必要がありました。
そこで登場するのが「Perceiver」です。Perceiverは、モダリティに依存せずに高精度な処理が可能なモデルです。ただし、Perceiverがマルチモーダルなモデルであるわけではなく、どのタスクを解かせるかに依存します。Perceiverの重要な点は、マルチモーダルなAIに先駆けて、モダリティへの依存の少ないアーキテクチャで高精度が出せるモデルが実現できることを示したところにあります。
さらに、Perceiverの出力は「Logits」であり、画像や動画、音声などの多種多様なモダリティの出力には直接対応することができません。そこで、この問題を解決するために、Perceiver IOというモデルが提案されました。Perceiver IOはPerceiverの基本的なアーキテクチャを拡張し、多種多様なモダリティの出力に対応することを可能にしました。
参考文献
[1] Tadas Baltrušaitis, Chaitanya Ahuja, Louis-Philippe Morency. "Multimodal Machine Learning: A Survey and Taxonomy," CoRR, 2017.
[2] Tom Michael Mitchell, "The Need for Biases in Learning Generalizations," 2007.
[3] Andrew Jaegle, Felix Gimeno, Andrew Brock, Andrew Zisserman, Oriol Vinyals and Joao Carreira. "Perceiver: General Perception with Iterative Attention," in Proc. ICML, 2021.
[4] Ashish Vaswani, Noam M. Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin, "Attention is All you Need," in Proc. NIPS, 2017.
[5] Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever, "Language Models are Unsupervised Multitask Learners," 2019.
[6] Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, and Joāo Carreira, "Perceiver IO: A General Architecture for Structured Inputs & Outputs," in Proc. ICLR, 2022.
[7] Alec Radford and Karthik Narasimhan, "Improving Language Understanding by Generative Pre-Training," 2018.