
この記事ではOpenAI Gymについて解説していきます。
こんな方におすすめ
- 強化学習のプログラミングに興味がある
- OpenAI Gymについて詳しく知りたい
などの方々にとって有益なものとなるはずです。
強化学習とは
本記事では、強化学習とは何かという内容から説明し、本題のOpenAI Gymの内容に繋げていきたいと思います。
強化学習とは、教師あり学習や教師なし学習などと共に機械学習分野を構成する大きな分野の1つで、報酬、いわゆるご褒美に基づいて行動の学習をすることを主問題として扱います。強化学習を行うには、制御器(Agent)と環境(Environment)とよばれる2つを定義し、制御器から環境へ行動(action)が、環境から制御器へは観測(observation)と報酬(reward)が与えられるという状況を用意する必要があります。
強化学習問題を図示すると以下のようになります。
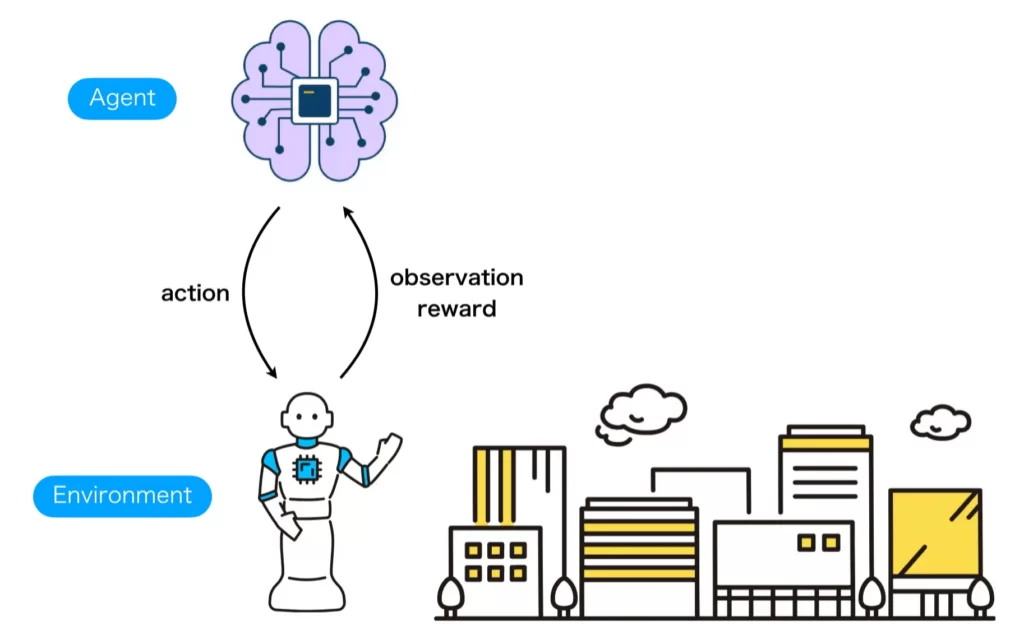
ここで、AgentとEnvironmentとは以下の表のように定義します。
| 語句 | 定義 | 例 |
|---|---|---|
| Agent | 環境を制御するプログラム | 深層強化学習プログラム |
| Environment | 制御対象 | 移動型ロボットと迷路 |
このように、強化学習を行うにはAgentとEnvironmentを扱う必要があるわけですが、もし、これらを各々の開発者が各々の規格で作成したら、研究開発や性能比較などにおいて、効率が著しく低下します。そこで便利になるのがOpenAI Gymです。
OpenAI Gymとは
既に、OpenAI Gymについて簡単に紹介したのでスムーズにご理解いただけると思いますが、強化学習アルゴリズムの開発や比較のためのオープンソースのライブラリです。人工知能の研究を行う非営利団体のOpenAIが提供しています。OpenAI Gymは強化学習アルゴリズムの開発や比較を容易にするために、学習アルゴリズム(Agent)と環境(Environment)間で行われる情報のやり取りの標準的なAPIを提供しています。
また、OpenAI Gymには標準として様々な強化学習環境が用意されており、インストールしたらすぐに強化学習環境を生成し試すことができます。
OpenAI Gymというと、強化学習環境を提供するライブラリというイメージを持つ方が多いですが、OpenAI Gymの目的は既述のの通り、学習アルゴリズム(Agent)と環境(Environment)間のインターフェースを提供することです。強化学習に触れ始めたばかりだと、OpenAI Gymインターフェースの有難みが分かりにくいかもしれませんが、自分で設計したロボットに動作を学習させたい時など、オリジナルな強化学習環境を作成して強化学習を実施する際の、研究開発の効率性・プログラムの再利用性、比較のしやすさにはOpenAI Gymならではだと思います。
インストール方法
OpenAI Gymのインストールは、以下のコードで行います。
pip install gymちなみに、アタリと呼ばれるゲーム環境を追加でインストールしたい場合はpip install gym[atari] を実行します。すべての追加機能をインストールしたい場合は pip install gym[all] を実行します。
使い方の基本
OpenAI GymのAPIは以下の機能を提供します。
- Gymに登録されている環境の生成
- AgentとEnvironment間のインターフェース
2つ目の「 AgentとEnvironment間のインターフェース」について補足ですが、OpenAI GymのAPIはオリジナルの強化学習環境を作成するところまでを見据えているため、このような説明がふさわしいと考える一方で、既存の強化学習環境を使用して強化学習を試すだけの方であれば、AgentからEnvironmentを操作するためのインターフェースという解説の方が納得しやすいかもしれません。
環境の生成方法
APIを通じで生成できる環境には、環境IDと呼ばれるものが用意されているので、gym.makeの引数に環境IDを渡すことで環境を生成・初期化できます。ここでは、カートポール環境(環境ID:CartPole-v0)を生成してみたいと思います。
# import gym
env = gym.make('CartPole-v0')AgentからEnvironmentを操作する方法
AgentからEnvironmetを操作するためのメソッドは、reset、step、renderの3つで、順番に、環境の初期化、1ステップだけ環境を実行、表示の機能です。
| メソッド | 機能 | 返り値 |
|---|---|---|
| reset | 環境の初期化 | 環境の初期状態(observation) |
| step | 1ステップだけ環境を実行 | 実行後の状態(observation)・終了判定(done)・報酬(reward)・その他情報(info) |
| render | 表示 | 画像配列など |
import gym
env = gym.make('CartPole-v0')
obs = env.reset() # 環境を初期化
for _ in range(1000):
env.render() # 環境の状態を可視化(GUIもしくは画像配列を選択可能)
action = env.action_space.sample() # ランダム方策
obs, done, reward, info = env.step(action) # 行動実施
env.close() # 終了知っておくと便利な機能
環境の入出力に関する情報
強化学習を実施するには、Gymで生成した環境の他に、学習プログラム(Agent)を作成する必要があります。その際、学習プログラムの入力や出力形式は学習で使用する環境の出力と入力形式に対応している必要があります。そのためには、環境の入出力のサイズなどの情報を知る必要があります。その際に便利な方法を紹介します。
AgentとEnvironment間でやりとりされる情報は、状態(の観測結果)・報酬・行動の3種類です。これらの情報は、以下の方法によりアクセス可能です。
- 状態(の観測結果)の型:env.observation_space
- 行動の型:env.action_space
- 報酬の範囲:env.reward_range
状態及び行動のサイズは、強化学習モデルの入力・出力サイズを決定する際に重要な要素になります。その際は、shape属性を調べることでサイズを知ることができます。以下に、CartPole-v0環境の場合の例を示します。
import gym
env = gym.make("CartPole-v0")
print("観測空間の型 :", env.observation_space)
print("観測空間のサイズ :", env.observation_space.shape)
print("行動空間の型 :", env.action_space)
print("報酬範囲 :", env.reward_range)このプログラムの出力は以下のようになります。
観測空間の型 : Box(-3.4028234663852886e+38, 3.4028234663852886e+38, (4,), float32)
観測空間のサイズ : (4,)
行動空間の型 : Discrete(2)
報酬範囲 : (-inf, inf)シード値の設定
強化学習環境の内部では様々な場面でランダム値を使用します。このランダム値を固定することで環境ないで使用されるランダム値の生成器を指定することができます。
SEED = 1024
env.seed(SEED)環境によっては、ランダム値を指定しても不確実性を持つものがあります。
シードを固定しても環境に不確実性があるかは、環境の仕様を決めるパラメータenv.spec.nondeterministicにアクセスすることで確認することができます。
環境の仕様を決めるパラメータについては以下の記事の「Gymに登録する方法」で触れているので、気になる方はぜひご覧下さい。
環境のベクトル化
一度に複数の同一環境を生成して、環境をベクトル化することができます。ただし、異なる環境同士を同時にベクトル化することはできません。同一環境を複数生成してベクトル化することで、学習プログラムは同時に複数環境を制御するとともに、複数の状態を受け取ることになり、ノイズに対してロバストになるなどの特徴があります。
ENV_ID = 'CartPole-v1'
NUM_ENVS = 3
env = gym.vector.make(ENV_ID, NUM_ENVS, asynchronous=True)環境から全てのラッパーを外す
OpenAI Gymから生成した環境をカスタマイズする方法として環境のラッパーを作成して適用していく方法が取られます。
env = Wrapper(env)ラッパーから得られる環境は、引数として渡した環境の入力や出力に何らかの変換を加えているため、元の環境は見えなくなります。そのような時に、元の環境を取得したい場合、以下のプログラムを実行することで、全てのラッパーを取り除いた元の環境を得ることができます。
env = env.unwrapped最後に
近年は、深層強化学習の発展により、さまざまな知的エージェントが実現できてきています。その技術を自らの手で実現するには、まずは、OpenAI Gymについて詳しくなる必要があります。今後も、この記事に情報を追加していきますので、OpenAI Gymに入門する際の学習に使用していただければと思います。