
物体検出のモデルであるR-CNNやSPP-netは学習プロセスが何段階に分かれており複雑という問題がありました。本記事で紹介する、Fast R-CNNは単一ステップの学習で同様の機能を実現できるように改善されたモデルです。それでは、Fast R-CNNについて解説していきたいと思います。
今回の解説論文はこれです。
https://arxiv.org/abs/1504.08083
要点
- 背景課題
- Fast R-CNN以前の物体認識モデル(R-CNNやSPP-net)は複数ステップの学習を必要とするため、学習が難しく時間もかかった。
- Fast R-CNNの特徴
- R-CNNやSPP-netより高いmAPを達成した。
- 単一の学習ステップでモデルをトレーニングできるように、CNN以降の構造は全てニューラルネットワークにし、Multi-task lossを使用する。
- SPPを単純化したRoI Poolingを使用して固定サイズの特徴マップ生成する。
R-CNNやSPP-netとの比較
最近は物体検出に絞って記事を執筆しており、本記事の以前までにR-CNNとSPP-netを紹介しました。
CNNを使用した初期の物体検出モデルと言えば、R-CNNが有名ですが、その後に登場したSPP-netでは特徴的なプーリングアーキテクチャを提案することで、学習&推論における精度や速度の面で大きく進化しました。しかし、これら2つのモデルは、以下の図のように、CNNの学習、分類器の学習、バウンディングボックス回帰器の学習という3ステップに分かれた学習ステップにより実現されています。学習を複数ステップに分けると、学習にとても時間がかかるうえ、後の学習ステップで前の学習ステップでトレーニングしたモデルを微調整できないなど、さまざまな問題がありました。目指すべき姿は、下図におけるStep1からStep3までを1つの誤差関数で一気通貫して学習できるモデルを作ることです。これが実現できれば、学習段階を複雑に分ける必要はありませんし、全体を同時に調整することができ、合理的です。
Fast R-CNNでは、そのような一気通貫した学習を実現しました。
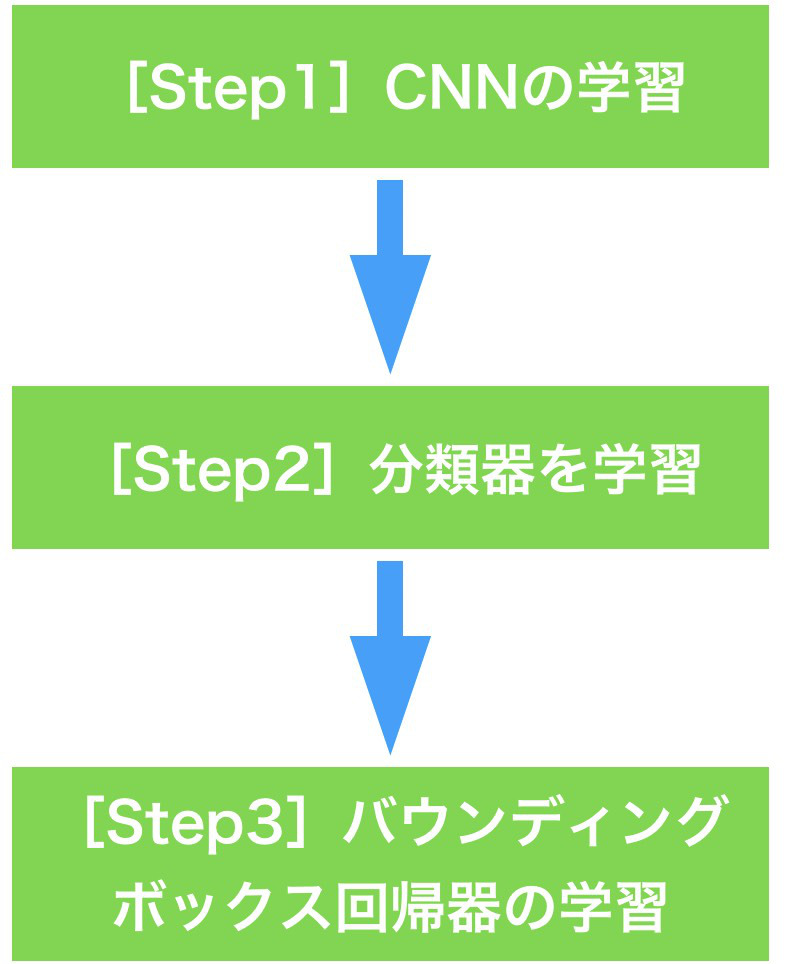
※ここでは、解説を端折ってますが、物体検出を行うにはCNNの直前にSelective Search(SS)による候補領域の提案のプロセスが必要です。ただし、Fast R-CNNより後のモデルでは、候補領域の提案プロセスもCNNに取り込む、End-to-Endな物体検出が現れますが、Fast R-CNNまでは、基本的に、候補領域の提案はモデルに含まないという考え方で問題ありません。なので、Fast R-CNNは、それ以前までの物体検出モデルの学習プロセスを統一化したという位置付けになります。
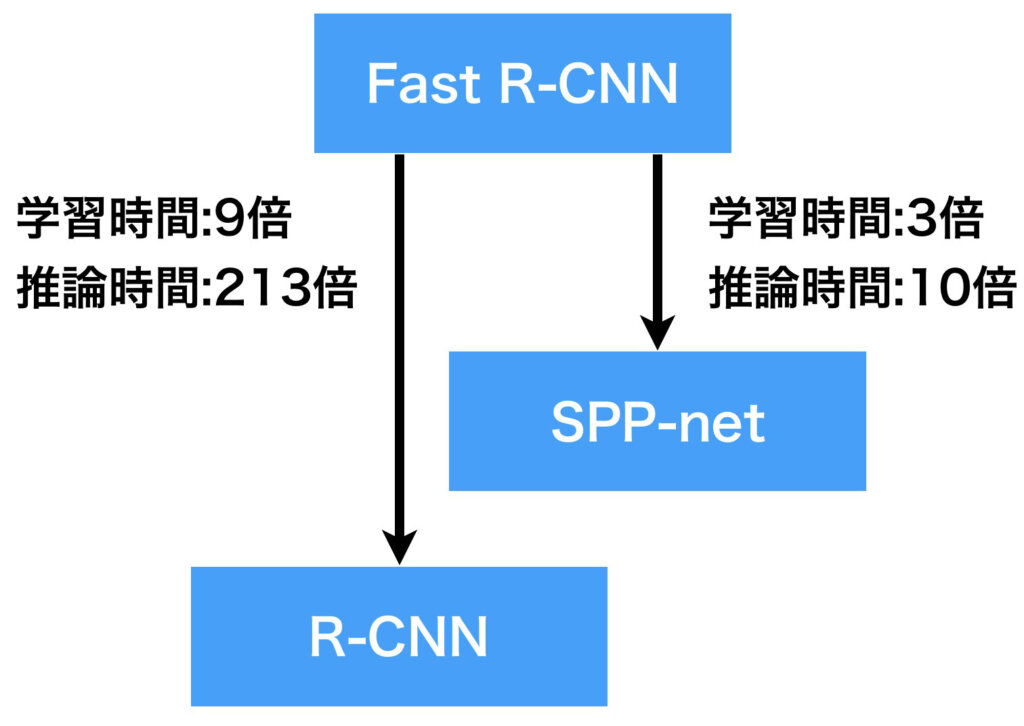
以下の図は、Fast R-CNNがR-CNNやSPP-netにくらべ、学習時間や推論時間がどのくらい高速化したのかを示しています。Fast R-CNNの学習及び推論の時間を基準してみます。このとき、R-CNNは9倍と213倍の時間が、SPP-netは3倍と10倍の時間がそれぞれかかるとされています。
見ての通り、R-CNNは遅すぎですよね。というのも、提案された候補領域の全てについて毎度、CNNを適用していたからです。SPP-netではCNNが出力する特徴マップの空間方向サイズが、入力画像サイズとの比率を保っている点に注目し、候補領域に対応する特徴マップ上の領域を抜き出して、SPP層を適用し固定長の特徴ベクトルを得るようにしたことで、CNNの適用回数を1回にしました。
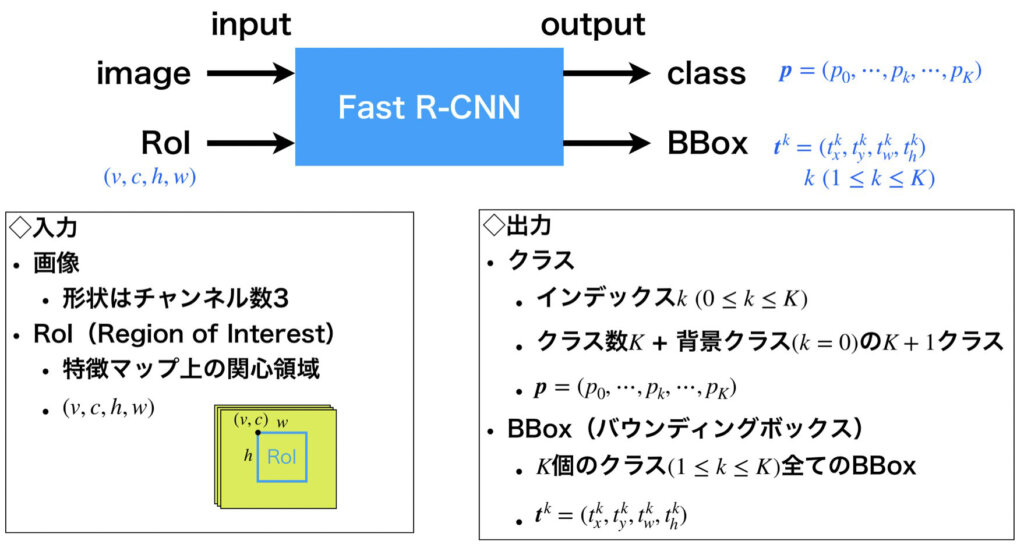
Fast R-CNNの基本概要
まず最初に、Fast R-CNNのアーキテクチャを理解していなくても解説可能な、入出力および学習について説明したいと思います。
入出力について
入力
Fast R-CNNの入力は、画像情報とRoI(Region of Interest)です。
画像情報
画像情報についての詳しい説明は必要ないと思いますが、入力形式としてRGB画像を想定しているので、(高さ, 幅, チャンネル数)のサイズのテンソルです。
RoI
RoIについて簡単に解説をすると、物体検出では最初にSelective Search(SS)などを使用して画像内に物体が映っているだろうとされる候補領域を多数得るわけですが、その候補領域をCNNが出力した特徴マップ上何処の領域に対応するかをマッピングしたものをRoIといいます。なぜ特徴マップ上にマッピングするかというと、入力画像上の候補領域レベルで考えると全ての候補領域にたいしてCNNを適用する必要があるためです。また、RoIは関心領域と訳され、R-CNNやSPP-netにおけるRegion Proposalとほぼ同じ意味です。
RoIはバウンディングボックス(以降、BBox)の形式で表現します。BBoxは入力が画像上において(左隅のx, 左隅のy, 幅, 高さ)の4つの成分で表すので、RoIも同様の記法を使用し\((v, c, w, h)\)を使います。\(v\)は特徴マップ上におけるRoIの左隅\(x\)軸方向の値、\(c\)はRoIの左隅\(y\)軸方向の値、\(w\)はRoIの幅、\(h\)はRoIの高さを表しています。
少し説明がややこしいので例を示します。まず、入力画像が(100, 100, 3)のRGB画像、候補領域が(10, 10, 20, 20)、内部のCNNが出力する特徴マップサイズが(10, 10, c)(cはチャンネル数)と仮定します。このとき、入力画像と特徴マップのサイズ比は10:1なので、特徴マップ上のRoIは提案された候補領域を10分の1にした(1, 1, 2, 2)になります。
出力
次に出力について解説します。Fast R-CNNの出力は、RoIで示された領域が所属するクラスの推定確率とBBoxです。ここにはいくつか注意事項があります。実際に認識したい物体クラスの数を\(K\)個としたとき、RoIが所属するクラスの推定確率は、\(K\)個の物体クラス(クラス番号は\(1~K\))に背景クラス\(クラス番号0\)を加えた\(K+1\)次元のベクトルになります。出力形式は、\(\boldsymbol{p} = (p_0,\cdots, p_k, \cdots, p_K)\)(ただし、\(0\leq k \leq K\))です。一方でBBoxですが、背景クラスはBBoxの対象外なので、物体クラスのみを対象とした、クラス1~\(K\)までの\(K\)個のBBoxを出力します。出力形式は、\(\boldsymbol{t}^k = (t_x^k, t_y^k, t_w^k, t_h^k)\)(ただし、\(1\leq k \leq K\))です。
ここまでの内容を以下の図にまとめました。
誤差関数について
ここまでで、Fast R-CNNの入力形式と出力形式について紹介してきました。次に、教師信号の形式を紹介しつつ、誤差関数について解説していきたいと思います。
教師
教師あり学習を行うには、出力データと比較するための教師データが必要になります。Fast R-CNNの出力はRoIの推定所属クラスを示すベクトルと、推定BBoxです。それぞれ、正解ラベルと正解BBoxが教師信号として用意されます。正解ラベルのデータ形式はクラス番号\(u (1\leq u \leq K)\)で、正解BBoxのデータ形式は\(\boldsymbol{v} = (v_x, v_y, v_w, v_h)\)です。
誤差関数
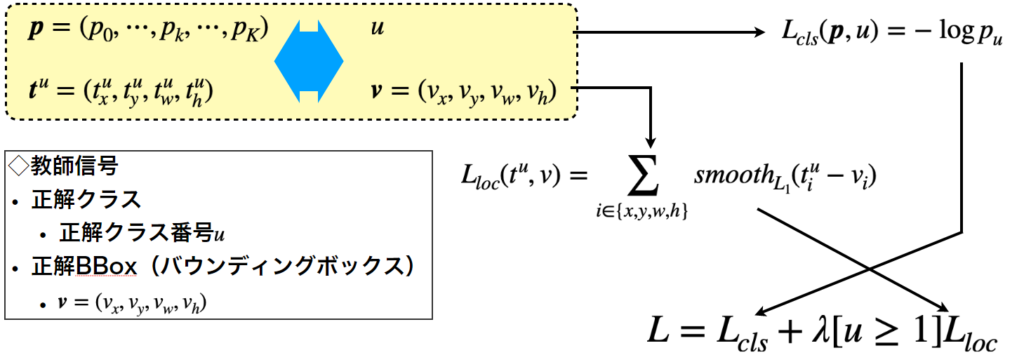
出力データと教師データのペアを紹介したので、クラス分類とBBox回帰のそれぞれについての誤差関数\(L_{cls}\)と\(L_{loc}\)を定義していきます。
最初にクラス分類に関する誤差関数ですが、以下の式のように定義します。
$$
L_{cls}(\boldsymbol{p}, u) = -\log \boldsymbol{p}_u
$$
これは、正解ラベル\(u\)に属する推定確率に関する自己情報量の形になっているので、分類の精度が向上するにつれて\(p_u\)の値は1に近づき、同時に\(L_{cls}\)は0に近づきます。
次にBBox回帰に関する誤差関数は以下のように定めます。
$$
L_{loc}(t^u, v) = \sum_{i\in \{x, y, w, h\}}smooth_{L_1}(t_i^u-v_i)
$$
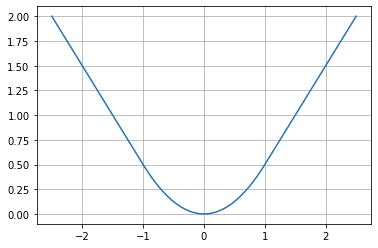
ここで、\(smooth_{L_1}(x)\)は以下の式で定義します。
$$
smooth_{L_1}(x) = \left\{
\begin{array}{ll}
0.5x^2&if |x|<1\\
|x|-0.5&otherwise
\end{array}\right.
$$
\(smooth_{L_1}\)の概形はL1誤差をスムーズにした以下のグラフのようになっています。L2ではなくL1を使用した理由は、L1の方がL2に比べ外れ値の影響を受けにくい(= 外れ値にロバストである)ためというように論文では解説されています。
ここは私の憶測が混ざってしまいますが、BBox回帰は時により正解とは全く異なる位置を示すなど、誤差が大きいと予想されるので、そこでL2を使用すると誤差値が爆発的に大きくなり、勾配爆発が発生する可能性も考えられるため、L1を選んだものとおもわれます。
誤差関数のマルチタスク化
マルチタスクというと複数の動作を同時に行うといった意味がありますが、先ほど個別に定義した誤差関数を合体させて、マルチタスクで学習ができる誤差関数を定義したいと思います。先に合体後の誤差関数を以下に示します。
$$
L = L_{cls} + \lambda [u\geq 1]L_{loc}
$$
第1項目はクラス分類に関する誤差、第2項目はBBox回帰の誤差ですが、2項目に関しては特殊な係数が乗算されています。なぜでしょうか?
それは、\(L_{loc}\)が背景クラス\(u=0\)に対応していないためです。つまり、\(u=0\)の時は係数を0にし、\(u\geq 1\)のとき係数\(\lambda)\)をかけます。ちなみに、\(\lambda\)は大抵1が使用されます。
ここまでの話をまとめて分かりやすく図示すると以下の図のようになります。
Fast R-CNNのアーキテクチャ
ここまで、Fast R-CNNをブラックボックスとして解説してきましたが、以降では内部のアーキテクチャに踏み込んで解説していきたいと思います。
全体像
それでは、Fast R-CNNのアーキテクチャについて全体像から解説していきます。ポイントは2つあり、1つ目は最終の畳み込み層の直後にRoIプーリング層があること、2つ目は全結層が2つに分岐して一方がクラス分類用になりもう一方がBBox回帰用になっている点です。前者については、RoIプーリング層という新しいプーリング手法が出てきたぞ~と思った方もいるかもしれませんが、SPP層の特別な場合なので、見たことがない新しいプーリングアーキテクチャではありません(もしSPP-netの記事を読んでいない方がいましたらこちらもどうぞ)。
下図において、背景が白い部分は1度のみの計算で、背景に色がついている部分は全てのRoIについて実行されます。つまり、Fast R-CNNは受け取った画像を最初の1度だけCNNで計算して特徴マップを得たら、同時に受け取った全てのRoIに関して反復的にRoIプーリング層以降の処理を実施します。
RoIプーリング層からは固定長の特徴ベクトルが得られ、直後の2つの全結合層により、RoI特徴ベクトルに変換されます。その後、2つに分岐してクラス分類用の全結合層とBBox回帰用の全結合層に接続されます。ちなみに、なぜここをRoI特徴ベクトルとするのかという疑問はあると思いますが、ほぼ説明の便宜上の問題です。もちろん、RoIプーリング層から得られた固定長の特徴ベクトルをRoI特徴ベクトルと名付けてもいいのですが。クラス分類とBBox回帰を行う全結合層の直前をRoI特徴ベクトルと呼ぶことで、RoI特徴ベクトルを使ってクラス分類やBBox回帰を行いますとった方が聞こえがいいですし、わかりやすいと思います。
見ての通り、学習プロセスが必要となる部位全てがニューラルネットワークで実現されたので、モデルの構造がとてもきれいになったといえます。
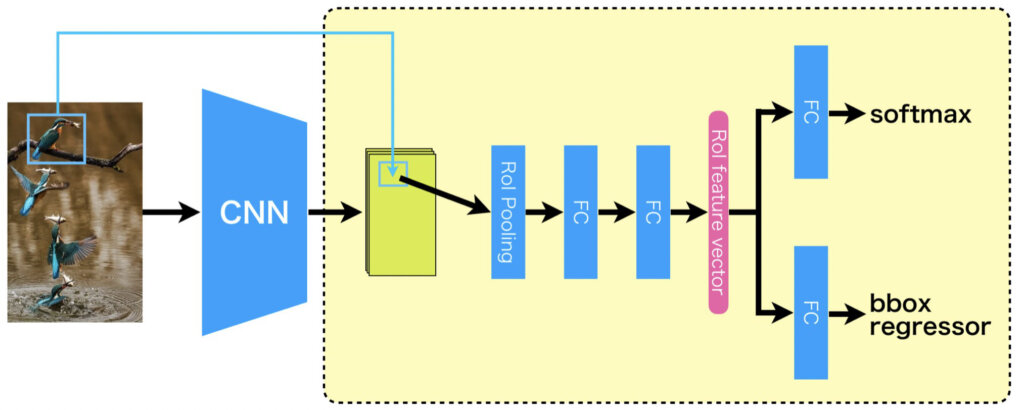
よく見ると、ILSVRCの画像認識コンペで使用されてきたCNNモデルに大変似ていることがわかると思います。一般的に分類で使用されるCNNにおいて、FC直前のプーリング層をRoIプーリングに交換し、最後のFC層を二股に分けて、一方を分類用、もう一方を回帰用にしただけと解釈することができます。
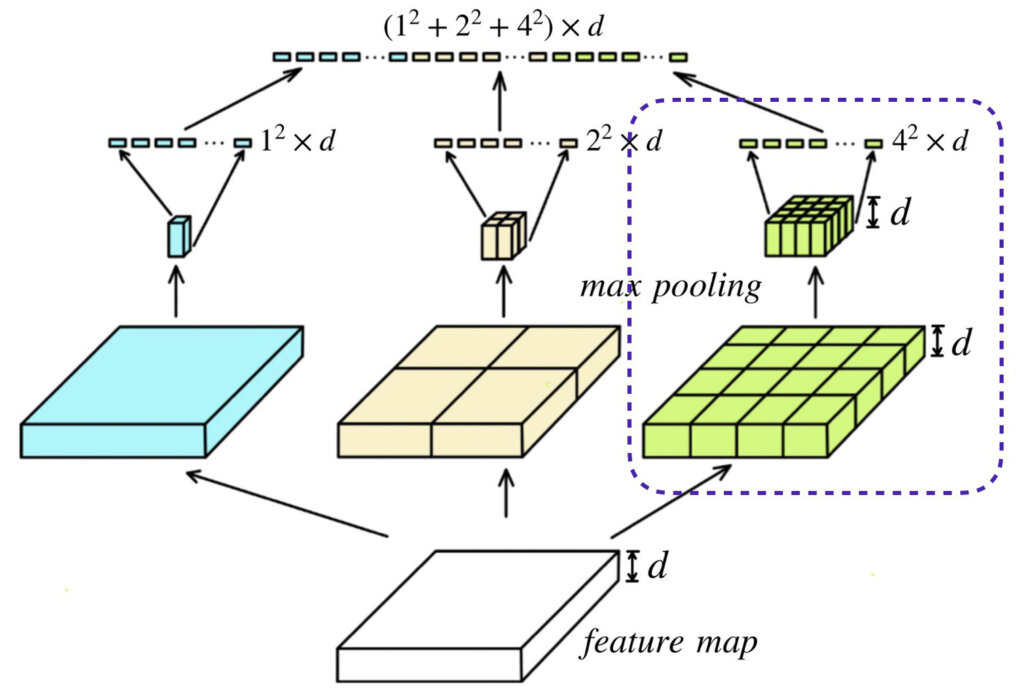
RoIプーリング層
先ほど、RoIプーリング層はSPP層の特別な場合、と解説しました。具体的にはどういうことか解説します。以下の図を見てください。以下の図は、前回の記事で紹介したSPP層を示しています。SPP層について軽く解説すると、図において一番下の白い直方体が最終の畳み込み層から出力される特徴マップで、それを、ハイパーパラメータで指定した複数の分割数(bin)にそれぞれ分割し、プーリング処理を適用します。例えば、ハイパーパラメータとして、[1, 2, 4]と分割数を指定したら、特徴マップが1x1、2x2、4x4の領域に分割されてプーリング処理が行われます。そして、最後に、チャンネル方向成分を展開し合体させてSPP層の最終的な出力を得ます。このように分割数に応じて複数のパスを持つようなプーリングをするSPP層ですが、RoIプーリング層は、そのうちのパス1つだけをしようします。例えば、4x4の領域に分割してプーリングを実行するパス(以下の図において青色で囲った所)のみを利用するということです。ここでは、説明の便宜上、4x4と言いましたが、一般化すると、RoI領域\((w, h)\)がRoIプーリング後に\((W, H)\)へ変換されるように、各領域を\((\frac{w}{W}, \frac{h}{H})\)ずつ分割する操作を行います。その後、flattenにより固定長ベクトルに変換します。
低ランク近似によるFC層の高速化
物体検出では全てのRoIについて反復的に計算を実施するため、RoIプーリング以降の全結合(FC)層が全体に占める計算コストの割合が増加しました。そこで、SVDと低ランク近似を使用して計算コストの減少をはかりました。
具体的には、全結合その重みを\(W\)(\(u×v\)行列)としたとき、\(t\)を\(u\)や\(v\)より小さい値として、\(u×t\)行列の\(U\)、\(t×t\)行列の\(\Sigma_t\)、\(v×t\)行列の\(V\)を使用して、行列のランクを下げて、つまり重み行列\(W\)の表現能力を小さくなるように近似します。
$$
W \approx U \Sigma_t V^t
$$
式の詳しい解説はここではしないので、この式の形はどこから出てきたのか!!と思われた方は、特異値分解(SVD)と調べていただければと思います。とにかく、このようにすることで、計算コストが小さくなり全結合層の計算高速化が図れます。
ちなみに、高速化したいなら、最初から全結合層のニューロン数を減らせばいいのではと思われるかもしれません。これが、学習する前なら確かにありですが、ここでは、\(u×v\)行列の\(W\)で学習し終えた全結合層を高速化するために、再度学習することなく計算量の圧縮をする方法という位置づけになります。
まとめ
最後に、まとめという形で、押さえておきたい部分について復習しておきたいと思います。
Fast R-CNNの以前の物体検出モデルであるR-CNNやSPP-netでは、CNNの学習、クラス分類器の学習、BBox回帰器の学習という3ステップの学習が必要とされ、モデルのトレーニングの難易度が高く、また、時間もかかりました。そこで、Fast R-CNNでは、学習部分を一括で実行できるように、ニューラルネットではなかった部分をニューラルネットワーク化し、クラス分類とBBox回帰のそれぞれに関する損失関数を同時に最適化するように、合体させてMulti-task lossにしました。
これが、最も注目すべき部分だと思っています。
参考文献
Ross Girshick. "Fast R-CNN". arXiv:1504.08083v2