
皆さんこんにちは!
去年(2022年11月)に発表されたChatGPTの話題が尽きない今日この頃、ChatGPTで使われている重要な技術の1つであるTransformerについて、興味を持った方は沢山いると思います。Transformerについては、以前、長文の解説記事を投稿したのですが、内容を詰め込みすぎて本質が分かりにくい感じがしたので、本記事では要点をまとめて短くしました。
この記事を読めば、Transformerについて詳細というよりは、マクロ的な部分の本質をご理解いただけるのではないかと思います。
Transformerとは
Transformerとは、2017年に発表された論文「Attention Is All You Need」において提案された系列変換モデルです。
系列変換モデル
系列変換モデルとは系列から系列へ変換するモデルです。系列とは複数の値(やベクトル)があるときにその順序に意味があるデータのことで、身近な例をあげると気温や株価の変動などがあります。機械学習分野においては、自然言語処理において、活発に研究がされています。自然言語処理とは、私たちが話す言語、これを自然言語と言いますが、これを系列データとして扱って、例えば機械翻訳などを実現する研究分野です。最近では、文章の要約、生成、感情認識など、様々な領域で使われています。
機械学習分野において、系列データの処理では、長らく再帰型ニューラルネットワーク(Recurrent Neural Network: RNN)が使用されてきました。RNNについては以下の記事で詳しく説明しています。簡単に説明すると、ニューラルネットワークに再帰構造をもたせた手法です。最も基本的なニューラルネットワークは、入力から出力まで一直線で処理を行っていく、フィートフォワード型ですが、それでは時刻を跨いで内部状態を伝播することができないのでループを持たせ、過去の状態を未来へ伝播できる構造にしたのです。
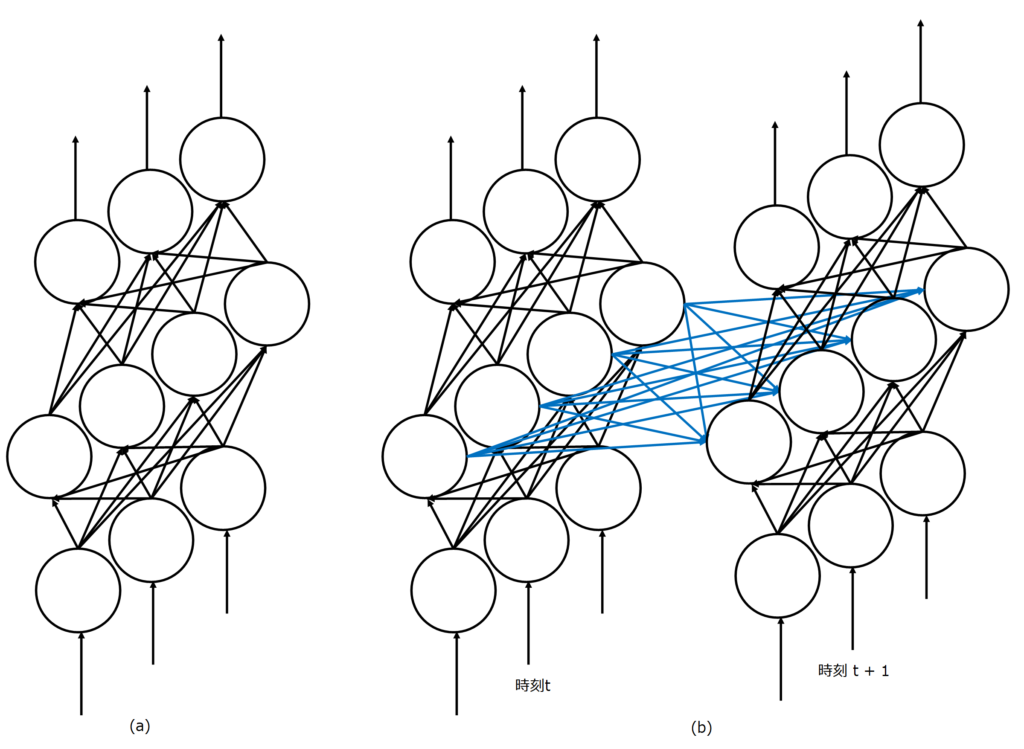
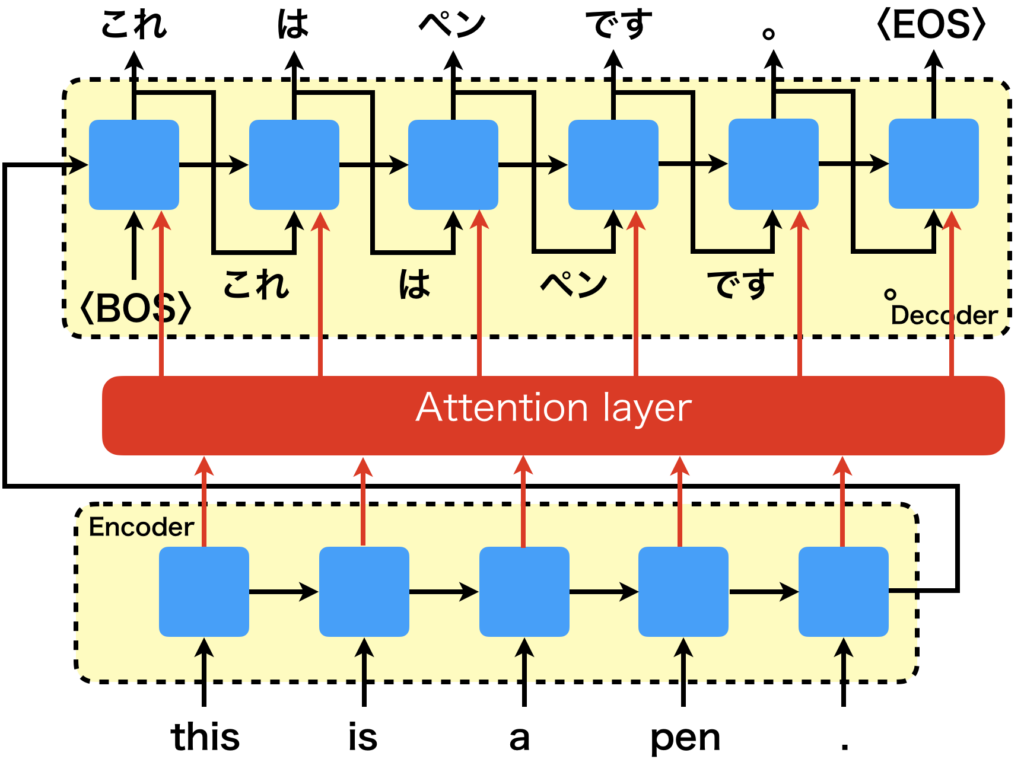
Transformerが発表される以前の一般的な系列変換モデルでは、Seq2Seqと呼ばれるエンコーダデコーダモデルが使用されていました。Seq2Seqにおいて、エンコーダは入力された文章をRNNを使って逐次的に処理して適切な内部状態に変換し、デコーダではその内部状態に基づいてRNNを使って逐次的に文章を生成します。これが、ザックリではありますが、Transformerの登場以前の系列変換モデルです。

Seq2Seqの課題
Transformerが登場する以前の系列変換モデルであるSeq2Seqには、2つの大きな課題がありました。位置依存性に弱く、また、学習の高速化が難しいという点です。それぞれ説明をしていきます。
位置依存性に弱い
位置依存性に弱いということを簡単に説明すると、変換前と変換後において関連性の高い情報が遠くにあると、Seq2Seqでは上手く対処できないという問題です。Seq2Seqのエンコーダは、文章を逐次的に読み込んで内部状態を少しずつ変換していきます。すると、初めのほうに読み込んだ情報の内部状態は薄れてしまいます。となると、デコーダで生成してくれなくなる可能性があります。それに、内部状態は1つしか持てないため、ニュアンスは異なるが同じことを表している文章でも内部状態が同じになることが考えられ、翻訳後の文章に細かいニュアンスを含めることが難しいです。
そこで、Seq2SeqにAttentionを仕組みを取り入れた手法が提案されました。
これにより、位置の依存性についてはある程度改善したのですが、RNNを使用しているので学習を高速化することができないという課題がありました。
学習の高速化が難しい
すでに簡単に触れていますが、RNNは逐次的に処理を行うモデルであるため、系列が長くなればなるほど処理に時間がかかってしまいます。例えば、系列データの長さが、100の場合は100回も繰り返し計算する必要があります。それゆえ、学習を並列化したとしても、大した高速化ができません。
そこで、畳み込みニューラルネットワークを使った手法も提案されました。例えば、1次元畳み込みはその代表格です。1次元畳み込みは、名前には畳み込みと付いていますが、系列データの処理で使用されるものです。しかし、1次元畳み込みは窓サイズが固定になるため、考慮できる系列長に限界があります。また、過去の情報を一括で入力してあげる必要があります。以下の記事で詳しく説明しています。
本題のTransformer
系列変換モデルの課題として、位置依存性に弱いということと学習の高速化が難しいという点について説明してきました。前者の課題については、Seq2SeqにAttention機構を採り入れて解決しようとしましたが、後者の問題が解決できませんでした。そこで、CNNを使った手法も考えられましたが、窓サイズの問題や、系列を一括で入力する必要がありました。極論を言うと、後者の問題を解決するには、逐次的な処理を諦めるしかないので、それを受け入れて、Attention機構付きのSeq2SeqからRNNを取り除いき、Attentionだけにしてしまえば良いのではないか?というのがTransformerです。ですので、Transformerとは完全にAttentionにのみに基づいた手法となっています。とてもザックリとした説明ですが。。。
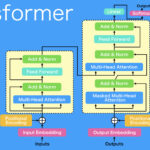
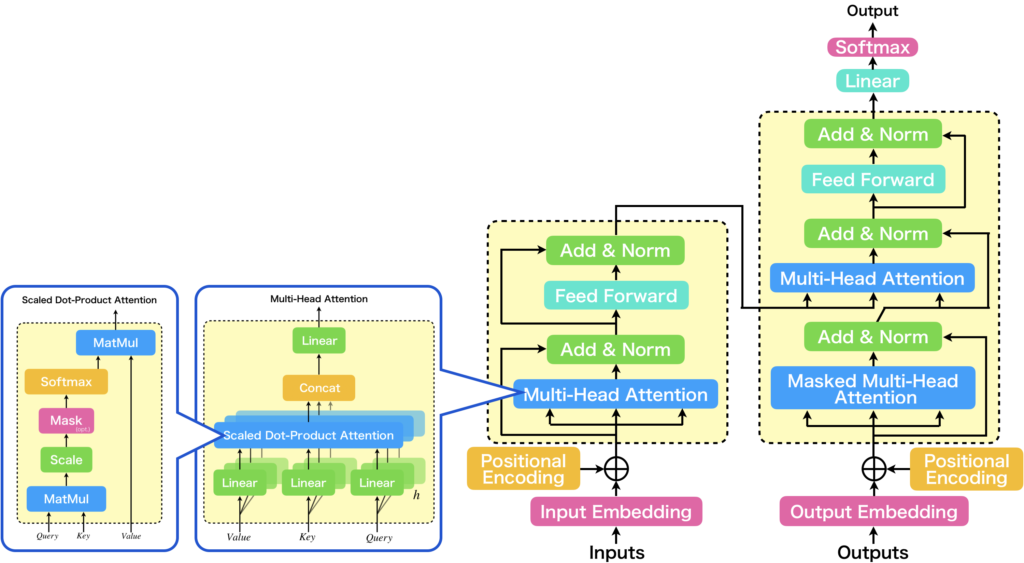
TransformerはSeq2Seqの流れをくみ取って、エンコーダデコーダモデルを採用しています。また、内部で使用するAttention機構について、明確にモデル化しています。Transformerで使用するAttention機構は、3つの入力をもつMulti-Head Attentionです。Multi-Head Attentionの3つの入力をどう使うかによって、Self-AttentionとSourceTarget-Attentionに分けられます。また、細かい話ですが、Multi-Head Attentionは、Scaled Dot-Product Attentionを複数並列にしたものです。なので、Multi-Headなのですね。以下にTransformerアーキテクチャを示します。
Multi-Head Attentionについては、以下の記事で詳しく解説していますので、詳細を知りたい方はそちらをご参照ください。

BERTやGPTとの関係
最近は、生成AIのブームなので、AIに詳しくない方でもGPTについて知っている人が多いと思います。BERTはどうなんですかね、さすがにGPTほどは浸透していないと思います。GPTについてはChatGPTの影響が大きいでしょう。ここでは、BERTやGPTとTransformerがどのような関係にあるのか簡単に説明します。
BERTとは、Bidirectional Encoder Representations from Transformersの頭文字をとったもので、Transformerのエンコーダ部分を使ったモデルです。エンコーダモデルなので、文章から感情などを予測するときに使用するのが一般的です。BERTは事前学習を行って、目的のタスクでファインチューニングをする使い方をします。
GPTとは、Generative Pre-trained Transformerの頭文字をとったもので、Transformerのデコーダ部分を使ったモデルです。デコーダなので、初めの文章のみを与えて、続きの文章を生成させるなどのような使い方をします。ChatGPTも、この延長線上にあります。GPTについては以下の記事で解説していますので、ぜひご参照ください。
さいごに
今回は、Transformerについてザックリと、概要を分かりやすく説明しました。しかし、ザックリとしすぎで厳密性には欠けるので、詳細については、以下の記事などを参考にしていただければと思います。本記事を通じて、Transformerの本質的なところをご理解いただければ本望です。最後までお読みいただきありがとうございました。
参考文献
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin, "Attention is all you need," in Proc. NeurIPS, 2017.