
皆さんこんにちは!
多くの方が1度は使ったことがあるであろうチャットAI、ChatGPT。従来のチャットAIからは想像もできない性能の高さを持ち、人間と会話する感覚で会話できることから大きな注目を浴びています。一方で、課題も明らかになっています。それは、人間なら気付くような単純なことでも、平気で間違った情報を答えるなど、内容の正確性や適切性に難がある点です。その為、ChatGPTの利用は、あくまでも補助的な位置づけに留めることが重要です。
とはいえ便利なものですので原理や今後の精度はどうなるのか気になりませんか?
今のままでは、その機能を活かしきれませんよね。ちょっともったいない気がしてしまいます。
今後、この課題は解決されるのでしょうか?
本記事では、ChatGPTの仕組みに踏み込んで原理を明らかにすることで、これらの課題が生じてしまう理由について知り、今後について考えていきたいと思います。
本記事の流れについて簡単に解説します。本記事では、ChatGPTが基にしているInstructGPTと呼ばれる仕組みについてメインで解説します。InstructGPTとは、GPT-3などの従来のGPTモデルが抱えていた課題を解決したモデルで、なぜ、InstructGPTが登場するに至ったのか、従来のGPTモデルの課題について明らかにし、その解決方法、InstructGPTの仕組み、またその課題について説明します。最後に、InstructGPTを踏まえてChatGPTについて考察します。
ChatGPTの概要
ChatGPTの概要は以下の記事で触れているので、ここでは簡単な説明に留めますが、ChatGPTとは、OpenAIが開発している大規模言語モデル(Large Language Model: LLM)であるGPT(Generative Pretrained Transformer)を用いたチャットAIサービスです。大規模言語モデルとは、人間の話す言葉をその出現確率でモデル化した言語モデルとばれるものを、膨大なデータから事前学習する深層学習モデルです。従来のチャットサービスのSiriやGoogleアシスタント、Alexaなどとは仕組みが全く異なり、より人間的かつ知的な文章を生成し、たとえ嘘であったとしても事実であるかのように自然な文章を生成してくれることから大きな注目をあびました。

ChatGPTの凄さと課題を1文で言うなら、「会話は自然だが事実かは分からない」ということになりますが、OpenAIはこれに対して何も対策をしていないわけではありません。後で説明する通り、極力間違いの無い人間好みの返答をするように調節したうえで公開されていて、その結果が今のChatGPTなのです。つまり、その調節が無ければ、ここまでの精度は実現できなかったのです。ただ、完璧は難しいので、どうしても、間違えてしまうことはあるでしょう。その間違いを見てChatGPTの限界を語るのは、やや早計だと私は思います。以降で説明するChatGPTの仕組みについて知れば、むしろ、ここまでマシな回答ができるように調節することができたのであれば、その延長線上に、もっと人間らしく無害な回答を生成できるようになる可能性を秘めていると思うようになるはずです。
よく、ChatGPTは大規模言語モデルの一種に過ぎないので、大量のデータをもとに入力文章から次の単語の生成確率を統計的に学習しているだけだと言われますが、その説明ではChatGPTがここまで大ブレイクする理由にはなりません。ChatGPTを語るには、従来のGPT-3のモデルにどのような工夫を追加したことで、公にサービスとして公開できるほどの性能を達成したのかに注目する必要があると思います。
しかし、それを理解するには、GPT-3などの従来の言語モデルの課題について知る必要があります。
では、具体的にどのような課題があったのでしょうか?
その課題について、次で説明します。
従来のGPTが抱えていた課題
GPTは、Generative Pretrained Transformerの頭文字をとったもので、2017年にGoogleが開発したTransformerと呼ばれる機械翻訳モデルのデコーダ部分を使って、言語モデルを学習したものです。最初にGPTが登場したのは2018年で、GPT-1[1]と呼ばれています。その後、GPT-2、GPT-3と新しい言語モデルが登場しました。言語モデルは、以下の対数尤度を最大化するようにモデルのパラメータを学習することで獲得されます。
$$L_1(\mathcal{U}) = \sum_i \log P(u_i|u_{i-k},\cdots, u_{i-1};\mathcal{\Theta})$$
ここで、$$\mathcal{U} = \{u_1, u_2, \cdots, u_n\}$$であり、\(n\)個の単語が並んだコーパスです。このコーパスに含まれる文章を生成できるようにモデルのパラメータ\(\Theta\)を最適化するのです。このように学習データを生成できるように学習を行うため、自然な文章を生成することができるのです。
その為、学習データの質が大変重要になります。ネット上には攻撃的な内容や間違った情報を含む文章が多く存在しているので、そのようなデータを用いて学習を行うと、攻撃的で間違った情報をたくさん生成する言語モデルが出来上がってしまいます。
実際、ChatGPTに使用されているGPT-3は、そのままでは、人間の欲しい情報を返してくれるとは限らず、間違った情報や、攻撃的な文章が生成されることが多々あったようです。
この解決策として、人間のフィードバックに基づいて出力を矯正する方法が模索され、InstructGPT[2]が登場しました。
具体的には、RLHF[3]と呼ばれる手法が用いられています。
RLHF
RLHF(Reinforcement Learning from Human Feedback)とは、人間のフィードバックに基づいた報酬予測モデルを用いた強化学習手法です。
そもそも強化学習とは、環境の中でエージェントが行動する状況を考えて、エージェントが環境から貰う期待報酬和を最大化するように行動を学習する方法です。

強化学習は、教師あり学習とは異なり明確に正解を持っていなくても、生成された行動の良し悪しが判断できれば適用可能な便利な手法です。ロボット分野でよく使われます。近年は、自然言語処理の分野でも活発に使用されています。
強化学習では、報酬関数をどう設定するかが重要です。良い報酬関数を設定してあげないと望み通りの行動を学習してくれません。報酬関数の設計は長年の課題であり、今でも活発に研究が行われている分野です。例えば、デモと呼ばれるお手本の行動データを準備できる場合は、強化学習の逆である逆強化学習(Inverse Reinforcement Learning: IRL)と呼ばれる手法を用いて、報酬関数の代わりとなる報酬予測モデルを獲得する方法があります。例えば、4脚ロボットの歩行を強化学習で獲得したいときに、センサを犬に装着して歩行時のデモデータを収集し逆強化学習で報酬予測モデルを獲得し、それから強化学習で歩行を学習させる方法があります[4]。しかし、逆強化学習による報酬予測モデルの獲得は、デモデータが収集できることが前提となっています。
もし、デモデータがそもそも収集できない場合や、収集できたとしても量が十分ではない場合はどうしたらよいでしょうか?
つまり、逆強化学習が使えない場合に、報酬予測モデルを獲得する方法は無いのでしょうか?
強化学習の考え方に則って、人間が報酬予測モデルの代わりになり、何千回、何万回と逐一報酬を手作業で計算すれば望みの動作を獲得してくれるかもしれませんが現実的ではありません。そこで、幾つかの人間のフィードバックを記録し、そこから報酬予測モデル(RM)を獲得するRLHFと呼ばれる方法が考えられました。
下図に、RLHFの考え方を示します。RLHFでは報酬の計算は人間のフィードバックに基づいて獲得された報酬予測モデルを使います。
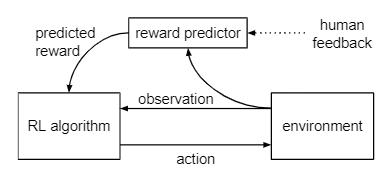
内容をまとめると、強化学習において報酬関数を設計は大変重要な一方で、複雑なタスクの場合はその設計は大変なので、デモデータが十分に収集できる場合は逆強化学習を使って、人間によるフィードバックが集められる場合はRLHFを用いて報酬予測モデルを獲得する手法が利用できるということになります。より簡単に言うと、良い行動を実演できるなら逆強化学習が、実演はできないけど評価はできる場合はRLHFが使えるのです。
文章生成の場合は、デモデータを収集することは可能ですが、カバーしなければならない領域が広すぎるため、RLHFが有効です。
InstructGPT
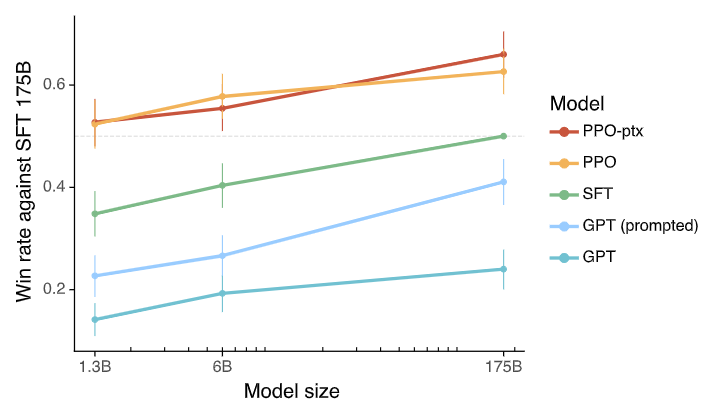
上で説明したRLHFをGPTに適用するとで、より人間に好まれる応答を可能にしたのがInstructGPTです。下のグラフは各モデルを人間が評価したものです。注目して欲しいのは、GPT、SFT、PPO-ptxです。GPTと記載されているのは、ファインチューニングやRLHFを適用していない純粋なGPTです。SFTは後で説明しますが人間に好まれる応答のデモデータでファインチューニングしたGPTモデルです。PPO-ptxは、RLHFを適用したGPT(InstructGPT)です。横軸が175Bのところは1750億パラメータのGPTモデル、即ち、GPT-3です。グラフの縦軸は、SFTモデルを基準としたときに、SFTモデルより優れた回答をした比率を表しています。GPT-3で比較すると、SFTやRLHFを適用していないGPTは、SFTよりも人間に好まれる回答をした割合は2割程度であることが分かります。一方で、InstructGPTは6割を超えています。これは1.3Bのようにサイズの小さいモデルであっても、同様のことが言えることが分かります。
InstructGPTの構築方法は以下に示す通りです。
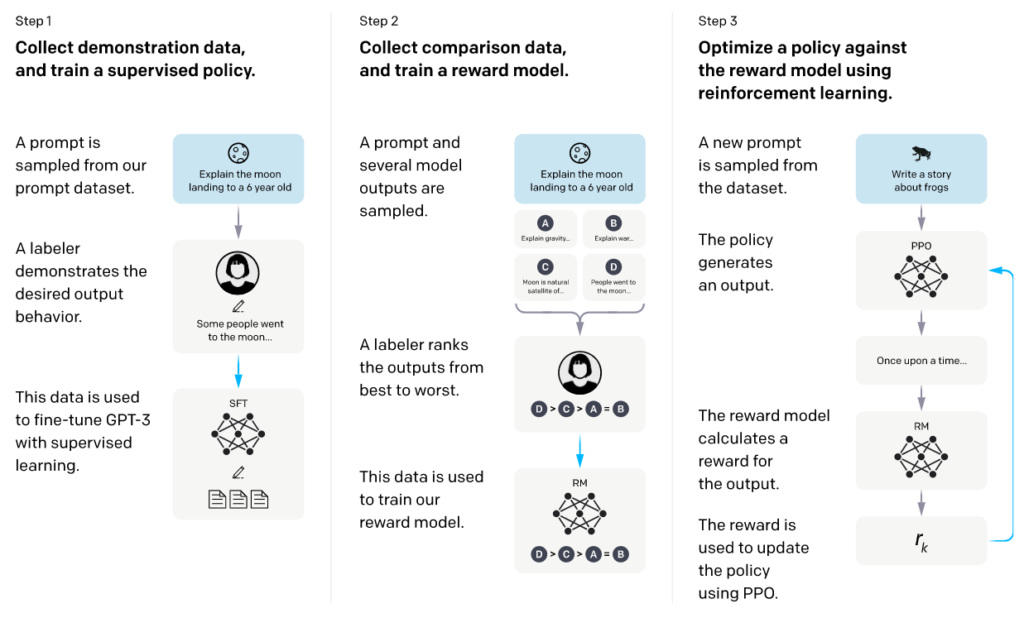
Step1:デモデータの収集とファインチューニング
Step2:比較データの収集と報酬予測モデルの獲得
Step3:報酬が最大化するように強化学習
Step1では、少数のデモデータ(入力文に対する出力を人間が用意)を用いてファインチューニングすることで人間の好む出力を出しやすくします。Step2の前準備という位置づけです。
Step2では、Step1で人好みの出力を生成しやすくなったモデルから、複数の出力を取得して、その出力を人手で評価します。このデータを用いて、報酬予測モデルの獲得をします。報酬予測モデルで使用されるニューラルネットワークのパラメータを\(\theta\)、関数を\(r_\theta (*)\)とすると、最適化する損失関数は以下の通りです。
$$
\text{loss}(\theta) = -\frac{1}{{}_KC_2} \mathbb{E}_{(x, y_w, y_l)\sim D}[\log (\sigma(r_\theta (x, y_w) - r_\theta (x, y_l)))]
$$
入力\(x\)に対する最も望ましい出力\(y_w\)とそれ以外の出力\(y_l\)の報酬の差が大きくなるように最適化をします。
Step3では、Step2で獲得した報酬予測モデルに基づいて強化学習を行います。強化学習には、PPO(Proximal Policy Optimization)[5]と呼ばれるオンポリシー強化学習手法を用いて方策を最適化します。方策ネットワークにはStep1とStep2を終えたGPT-3のモデルを使います。また、強化学習を適用することで、獲得された言語モデルが崩れてしまうことを防ぐための工夫を追加しており、それをPPO-ptxと呼んでいます。
以上の3ステップを経て得られたGPTモデルをInstructGPTと呼びます。
InstructGPTの課題
このように人間が好むような出力を出すように強化学習を行ったことで、先ほど示したグラフのように、かなり人間に好まれる無害な回答を出せるようになったのですが、完全には無くなりません。例えば、間違った回答をする、明確な答えがあるものに対しても、だらだらと複数の答えの候補を答えたり、質問自体が間違っているのに、そのまま答えて嘘に嘘を重ねたりします。
これらは、ChatGPTでも問題視されていますが、何が原因なのでしょうか?
論文には、報酬予測モデルの獲得に使用した評価付きデータの収集における、評価基準やデータのバリエーションなどに限界がある可能性が述べられています。InstructGPTでは、謙虚な受け答えを高く評価するという基準を用いて人手で評価したため、質問の答えが明確に決まっていたとしても、断言せずにダラダラと文章を生成すように学習された可能性があるようです。また、バリエーションについては、全ての言語、全てのシチュエーションに対して、評価を下すことができないということです。特に、間違った質問を受けたときや、間違った回答をする状況は、学習データに多くは含まれていないこと、また、それらを再現することは難しいことが考えられます。
※ここでは触れませんが、原論文では敵対的なデータ収集についても述べられています。
InstructGPTからChatGPTへ
ChatGPTの仕組みは、ここまで説明してきたInstructGPTと同じです。ただし、より対話寄りのデモデータと評価に基づいてRLHFを行っています。そのため、対話の観点で、ChatGPTは大きく改善しているのでしょう。InstructGPTで説明した通り、RLFHを通じて、可能な限り人間の好まれるような出力を出すようにトレーニングされているのですが、間違った内容を出力したりする現象は、完全には無くなっていません。
では、ChatGPTはダメなのかというと、それは早計ではないかと個人的には思っています(はじめでも述べましたが)。先ほど示したように、強化学習により大幅に改善できたからこそChatGPTの凄さを実現できたこと、限界は手法よりもフィードバックの量にあると考えられる点を鑑みると、現時点でChatGPTに見切りをつけるのではなく、ChatGPTを育てるつもりで向き合っていくべきなのかもしれません。
私の持論ですが、上記の理由によりOpenAIはChatGPTをオープンにして不特定多数の大勢からフィードバックを貰うことでAIの精度を向上させようとしているのではないかと考えています。
現に、ChatGPTのサービスを利用すると、ChatGPTの応答の良し悪しをGoodとBadで評価することができるようになっています。

GoodもしくはBadを押すと、フィードバックを提供するよう求められます。
ここから得たフィードバックを直接学習に使用するのかどうかは知るよしはないですが、ChatGPTの精度改善に寄与するに違いないでしょう。
さいごに
以上で、説明は終わりになりますが、ChatGPTの仕組みや課題、今後についてご理解いただけましたでしょうか?
私の説明も必ずしも正しいとは限りませんが、ChatGPTについて考えるきっかけとなりましたら幸いです。
参考文献
[1] Alec Radford and Karthik Narasimhan, "Improving Language Understanding by Generative Pre-Training," 2018.
[2] Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe,"Training language models to follow instructions with human feedback," arXiv, 2022.
[3] Paul Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei, "Deep reinforcement learning from human preferences," arXiv, 2017.
[4] Xue Bin Peng, Erwin Coumans, Tingnan Zhang, Tsang-Wei Lee, Jie Tan, and Sergey Levine, "Learning Agile Robotic Locomotion Skills by Imitating Animals," in Proc. RSS, 2020.
[5] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov, “Proximal Policy Optimization Algorithms,” arXiv, 2017.