
歩行者用信号機の色認識を行うプログラムを作成する必要があったので、自分が適当に試しに作ってみたプログラムを紹介していきます。
また、今回紹介するプログラムをROSのノードとして使用できるようにするプログラムも紹介します。
適当に作ったものなので、制度の検証はしていませんが、ちゃんと認識されるので、ちょっと感動しました。
それでは、紹介していきます。
はじめに
今回、僕が作成した歩行者用信号機の色認識プログラムは、YOLOを用いた歩行者用信号機の物体検出パートと、信号機の色認識パートの2パートからなります。
使用するYOLOのプログラムについては、以下の記事で紹介しているので、一緒にご覧いただければと思います。

前準備
使用するYOLOプログラムのリポジトリをダウンロードします。
git clone https://github.com/ultralytics/yolov5
cd yolov5
pip install -r requirements.txtダウンロードが終了したら、Python側で使用するライブラリ群をインポートします。
import matplotlib.pyplot as plt
import numpy as np
import torch
import cv2YOLOによる歩行者信号の検出
今回は、YOLO v5sを使用しました。YOLO v5sは以下のコードによりロードできます。
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')YOLO v5には、n,s,m,l,xの5種類があります。これは、モデルのサイズをなので、最も精度が良いものを使用したければ、YOLO v5xを使用しましょう。YOLOの種類は、以下の記事で説明していますので、よかったらご覧ください。
今回は、歩行者用信号機の色認識だけがしたいので、信号認識のみを認識するように、設定します。YOLOでは、認識してほしいラベルの場号をリストで渡すことで、設定することができます。
(何も設定しなければ、YOLOが認識可能な全ての物体検出が行われます。今回のような用途の場合、高速性が重要なので、必要のない処理は省くのが無難でしょう。)
model.classes = [9]では、歩行者用信号機の検出を試してみます。
使用する画像は以下です。

ここで使用するYOLOのプログラムは、配列形式の画像を渡すこともできますし、画像のURLを渡すこともできます。今回は、URLを渡すことにします。
img_path = 'https://developers.agirobots.com/jp/wp-content/uploads/2022/04/868DE706-54D3-412E-8CA9-9C93051C9A91-847x1024.jpeg'
results = model(img_path)ちゃんと歩行者用信号機の検出ができているか確認してみます。得られた結果をresultsに代入していますが、その中にはいくつかのメソッドが用意されていて、crop()を用いると、検出領域だけを抽出することができます。resultsには、一般的に検出された全ての物体の情報がリスト形式で格納されていますが、今回は1台の信号機しか写っていない画像を、信号機しか認識しないモデルに通しているので、[0]により0番目の要素を取り出しています。取り出したものは辞書型で、画像配列は'im'というキーでアクセスできます。
また、得られた画像配列は、OpenCVで使用されるBGR形式なので、matplotlibで正しい色が表示できるように、RGBに変更しています。
plt.imshow(cv2.cvtColor(results.crop()[0]['im'], cv2.COLOR_BGR2RGB))
すごいですね。歩行者用信号機が正しく抽出できています。
今回の画像は、歩行者用信号機しか映っていませんでしたので、問題ありませんが、ときによって車用信号機が映り込んでいる可能性があります。その場合、それも一緒に認識されてしまうので、認識した信号機が歩行者用かどうか判定し、歩行者用信号機のみを抽出する関数を作成します。
以下の関数は、yoloのモデルから出力された結果を直接入力して使用します。
# 歩行者用信号機かチェックし、歩行者用信号機であればその画像を返す
def ReturnPedestrianTrafficLight(results):
# 結果が0でないことを確認する(ただし、resultsに格納されているのはtraffic lightのみ)
if len(results.crop()) == 0:
return None
# 何かしらの信号機が認識されている場合に以下のコードが実行される
for traffic_light in results.crop(): # 全ての画像に適用
img = traffic_light['im']
img_shape = img.shape
# 縦長画像であれば良い
if img_shape[0] > img_shape[1]:
return img # 歩行者用信号機だったら、その部分を切り抜いた画像を返す
else:
return None # 歩行者用信号機ではなかったらNoneを返すよって、以下のようなコードを実行するだけで、結果から歩行者用信号機の画像を抽出でます。
※歩行者用信号機が検出されていなかった場合はNoneが返されます。
img = ReturnPedestrianTrafficLight(results)色の判別
信号機の色の判別については、ルールベースで行いますが、少し考える必要がありそうです。ここで紹介するのは、私が数時間で適当に試したらうまくいったものですので、あくまでも参考程度でお願いしますね。
赤と青の点灯領域から判定領域を抽出
入力画像から、歩行者用信号機が抽出された画像を、そのままナイーブに上下に分割して、色の比較や認識を行う手法が最初に思い浮かぶと思いますが、その場合、信号の周りの空の色が結果に影響を与えてしまう可能性があります。そこで、少しセットバックさせて、信号機が点灯したときに明るくなりえる部分のみを抽出して処理することにします。抽出方法は、プログラムを読んでいただくのが早いと思うので、省略します。
# 上下から色判定領域を抽出する関数
def extractRedBlueArea(img):
img_shape = img.shape
w_c = int(img_shape[1] / 2)
s = int(img_shape[1] / 6)
# 上(赤色領域)のエリアにおける抽出画像の中心点を設定
upper_h_c = int(img_shape[0] / 4)
# 下(青色領域)のエリアにおける抽出画像の中心点を設定
lower_h_c = int(img_shape[0] * 3 / 4)
return [img[upper_h_c - s:upper_h_c + s, w_c - s:w_c+s, :], img[lower_h_c - s:lower_h_c + s, w_c - s:w_c+s, :]]if type(img) == np.ndarray: # 歩行者用信号機の画像があるか確かめる
RedBlueImgs = extractRedBlueArea(img)
この画像(特に左)は、歩行者用信号機の画像のどこを抽出したものか分かりにくいので、元の画像にバウンディングボックスを付与し可視化するプログラムを作成しました。プログラムは以下の通りです。
def DisplayAreaOfInterest(img):
img_shape = img.shape
w_c = int(img_shape[1] / 2)
s = int(img_shape[1] / 6)
upper_h_c = int(img_shape[0] / 4)
lower_h_c = int(img_shape[0] * 3 / 4)
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.plot([w_c - s, w_c - s], [upper_h_c - s, upper_h_c + s], color='Yellow')
plt.plot([w_c + s, w_c + s], [upper_h_c - s, upper_h_c + s], color='Yellow')
plt.plot([w_c - s, w_c + s], [upper_h_c - s, upper_h_c - s], color='Yellow')
plt.plot([w_c - s, w_c + s], [upper_h_c + s, upper_h_c + s], color='Yellow')
plt.plot([w_c - s, w_c - s], [lower_h_c - s, lower_h_c + s], color='Yellow')
plt.plot([w_c + s, w_c + s], [lower_h_c - s, lower_h_c + s], color='Yellow')
plt.plot([w_c - s, w_c + s], [lower_h_c - s, lower_h_c - s], color='Yellow')
plt.plot([w_c - s, w_c + s], [lower_h_c + s, lower_h_c + s], color='Yellow')
DisplayAreaOfInterest(results.crop()[0]['im'])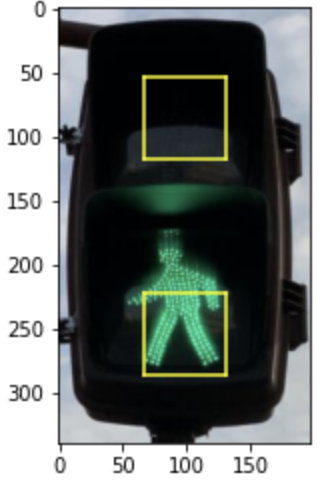
画像を見てもらうと分かる通り、上下領域それぞれの中心付近から、横幅の1/3程度の大きさの正方形が色判定に使用する領域になっています。
色を判定
判定手順
- 上の判定領域および下の判定領域それぞれにおいて、赤色成分の平均値と青色成分の平均値を求める
- 赤色成分と青色成分の平均値の差分の絶対値を求める
- 上の色判定領域における差分の絶対値と下の色判定領域における差分の絶対値を比較
- 上の方が差分の絶対値が大きい:赤色として認識
- 下の方が差分の絶対値が大きい:青色として認識
上の表で示したルールに則って、信号の色を導出する関数は以下です。
# 上側の画像と下側の画像をリストにしたものを引数として渡す
def ReturnPedestrianTrafficLight(results):
# 結果が0でないことを確認する(ただし、resultsに格納されているのはtraffic lightのみ)
if len(results.crop()) == 0:
return None
# 何かしらの信号機が認識されている場合に以下のコードが実行される
for traffic_light in results.crop(): # 全ての画像に適用
img = traffic_light['im']
img_shape = img.shape
# 縦長画像であれば良い
if img_shape[0] > img_shape[1]:
return img # 歩行者用信号機だったら、その部分を切り抜いた画像を返す
else:
return None # 歩行者用信号機ではなかったらNoneを返す以上より、以下のコードを実行することで、信号の色を導出することができる。
ReturnTrafficLightSignal(RedBlueImgs)ここまでのプログラムをまとめると
ここまで示してきたプログラムを、1つにまとめました。
import matplotlib.pyplot as plt
import torch
import numpy as np
import cv2
# 歩行者用信号機かチェックし、歩行者用信号機であればその画像を返す
def ReturnPedestrianTrafficLight(results):
# 結果が0でないことを確認する(ただし、resultsに格納されているのはtraffic lightのみ)
if len(results.crop()) == 0:
return None
# 何かしらの信号機が認識されている場合に以下のコードが実行される
for traffic_light in results.crop(): # 全ての画像に適用
img = traffic_light['im']
img_shape = img.shape
# 縦長画像であれば良い
if img_shape[0] > img_shape[1]:
return img # 歩行者用信号機だったら、その部分を切り抜いた画像を返す
else:
return None # 歩行者用信号機ではなかったらNoneを返す
# 上下から色判定領域を抽出する関数
def extractRedBlueArea(img):
img_shape = img.shape
w_c = int(img_shape[1] / 2)
s = int(img_shape[1] / 6)
# 上(赤色領域)のエリアにおける抽出画像の中心点を設定
upper_h_c = int(img_shape[0] / 4)
# 下(青色領域)のエリアにおける抽出画像の中心点を設定
lower_h_c = int(img_shape[0] * 3 / 4)
return [img[upper_h_c - s:upper_h_c + s, w_c - s:w_c+s, :], img[lower_h_c - s:lower_h_c + s, w_c - s:w_c+s, :]]
# 上側の画像と下側の画像をリストにしたものを引数として渡す
def ReturnTrafficLightSignal(img_list):
# 画像データはBGRとする
upper_img = img_list[0]
lower_img = img_list[1]
# 上側(赤)のランプの状態を検出
upper_red_nums = cv2.cvtColor(upper_img, cv2.COLOR_BGR2RGB)[:,:,0].mean() # 赤色成分の平均値
upper_blue_nums = cv2.cvtColor(upper_img, cv2.COLOR_BGR2RGB)[:,:,2].mean() # 青色成分の平均値
# 差分を求める
upper_delta = abs(upper_red_nums - upper_blue_nums)
# 下側(青)のランプの状態を検出
lower_red_nums = cv2.cvtColor(lower_img, cv2.COLOR_BGR2RGB)[:,:,0].mean() # 赤色成分の平均値
lower_blue_nums = cv2.cvtColor(lower_img, cv2.COLOR_BGR2RGB)[:,:,2].mean() # 青色成分の平均値
# 差分を求める
lower_delta = abs(lower_red_nums - lower_blue_nums)
if upper_delta >= lower_delta:
return 'red'
else:
return 'blue'
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
model.classes = [9]
def TrafficLightSignal(imgArray_or_imgPath):
results = model(imgArray_or_imgPath)
img = ReturnPedestrianTrafficLight(results)
if type(img) == np.ndarray: # 歩行者用信号機の画像があるか確かめる
RedBlueImgs = extractRedBlueArea(img)
else:
return None
return ReturnTrafficLightSignal(RedBlueImgs)上のプログラムを読み込んだら、あとは、下のようにして画像配列もしくはURLを渡すだけで、赤か青かがリターンされます。
img_path = 'https://developers.agirobots.com/jp/wp-content/uploads/2022/04/868DE706-54D3-412E-8CA9-9C93051C9A91-847x1024.jpeg'
TrafficLightSignal(img_path)これより、歩行者用信号機の認識プログラムが完成しました。
試してみる
いくつかの画像を用いて、正しく判別できるか確かめてみます。
適当に大学で写真を撮ってきました(どこの大学かバレてしまいそうですw)。
1枚目のテスト画像と結果

img_path = 'https://developers.agirobots.com/jp/wp-content/uploads/2022/04/3A8155C3-AEC9-4BA7-8F4C-5A28424AA504-768x1024.jpeg'
TrafficLightSignal(img_path)上のコードを実行することで、上に示した画像の認識をテストすることができます。
正しく赤と認識されました。
2枚目のテスト画像と結果

img_path = 'https://developers.agirobots.com/jp/wp-content/uploads/2022/04/3E42F254-938D-43A9-AB29-D5F9563BF9E7-958x1024.jpeg'
TrafficLightSignal(img_path)次は、少々眩しい西陽付きの信号の写真です。これは、信号自体が検出されませんでした。西陽が原因なのか、信号が小さいためか、確かめていないので分からないですが、恐らく、信号が小さかったからだと思います。
3枚目のテスト画像と結果

img_path = 'https://developers.agirobots.com/jp/wp-content/uploads/2022/04/D76280A5-17D1-4F6D-8520-F1EA2029539C-768x937.jpeg'
TrafficLightSignal(img_path)こちらの画像は、青色と正しく認識されました。
4枚目のテスト画像と結果

img_path = 'https://developers.agirobots.com/jp/wp-content/uploads/2022/04/BF988292-4BCF-466F-A1ED-BB09A93479AE-768x973.jpeg'
TrafficLightSignal(img_path)こちらの画像は、赤色として正しく認識されました。
さいごに
この記事では、歩行者用信号機の色認識を実現するプログラムの実現例を紹介してきました。
結構簡単に実現できることに驚きましたが、まだ課題も多いです。例えば、YOLOで検出できなかった場合は、色認識以前の問題になってしまうこと、動画には対応できない、点滅の認識は不可能、といったところです。
改善方法がないわけではありません。いろいろアイディアを考えて、精度の高いプログラムを作ってみてください!