
画像関連の情報を調べてたらYOLOっていうものを見つけたよ。
YOLOについて、色々教えてほしいな!


YOLOについて概要について説明しよう。あと、実際にYOLOを体験してほしいから、YOLOを簡単に試せるおすすめのアプリやプログラムを紹介しよう!
YOLOとは
YOLOとは、高速かつEnd-to-Endで物体検出を実現するモデルです。物体検出とは、入力画像の中に写っているものに関して、位置を特定しバウンディングボックスで囲み、それが何かを表すラベルを付与するタスクです。
YOLOの名前は、「たった一度きりの人生、後悔のないように生きよう」というスラングの「You Only Live Once」を文字った「You Only Look Once」から来ています。
一度見るだけで、物体検出ができるという高速性を表しているのでしょう。
ディープラーニングは、計算コストの大きさゆえ、高速に物体検出を行うことが難しかったのですが、YOLOにより、速度面のボトルネックが解消され、さまざまなところで使用されるようになりました。
余談ですが、YOLOの開発者であるJoseph Redmonは、YOLOについてTEDで講演しています。
YOLOの種類と特徴
YOLOは、初代(YOLO v1)から現在(YOLO v5)に至るまで、5回アップデートされています。
初代から順番に、YOLO v1、YOLO v2、YOLO v3、YOLO v4、YOLO v5と呼ばれています。
YOLO v1からYOLO v3までは、YOLO自体の開発者であるJoseph Redmonにより発表されましたが、それ以降は、YOLOの開発に関わっておらず、YOLO v4はAlexey Bochkovskiyにより、YOLO v5はUltralysticsにより開発されています。
開発に携わらなくなってしまった正確な理由は、本人しかわからないですが、YOLOの高精度さゆえ、自分の技術が悪用される可能性に対して、疑問を持ち悩んだ末、開発から退くことを決定したのではないかと考えています。
YOLO v1
YOLO v1は論文"You Only Look Once: Unified, Real-Time Object Detection."で発表されたものです[1]。
YOLO v2
YOLO v2は論文"YOLO9000: Better, Faster, Stronger."で発表されたものです[2]。
YOLO v3
YOLO v3は論文"YOLOv3: An Incremental Improvement."で発表されたものです[3]。
YOLO v4
YOLO v4は論文"YOLOv4: Optimal Speed and Accuracy of Object Detection."で発表されたものです[4]。
YOLO v5
YOLO v5はultralyticsが開発した物体検出モデルです。YOLO v5に関しては論文発表がされていません。
Google Colabのノートブックや、kaggleのノートブックが公開されています。
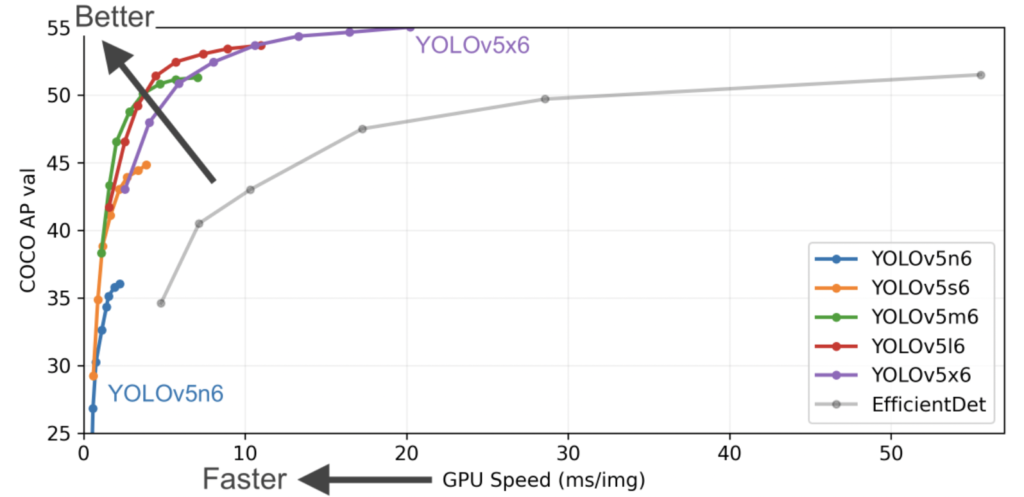
YOLO v5には、YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5xの5つがあり、それぞれ計算コストや精度が異なります。5つの中でも、YOLO v5xが最も精度が良いですが、必要な計算コストが高いです。一般的に、精度と計算コストはトレードオフの関係にあるため、使用するマシンの性能や、求められる精度を考慮し、適切な設定を見つける必要があります。
YOLOX
YOLOXは2021年8月に公開された物体検出モデルです[7]。YOLOv5を超える性能をもっています。Apache-2.0 licenseのもとで公開されています。

YOLO v6
YOLO v6は論文"YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications."で発表されたものです[8]。
https://arxiv.org/abs/2209.02976
YOLO v7
YOLO v7は論文"YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors."で発表されたものです[9]。
https://arxiv.org/abs/2207.02696
手軽にYOLOを試す
YOLO v5を開発したultralyticsがYOLO v5が手軽に試せるiOS向けのアプリを公開しています。
iPhoneやiPadなど、iOS端末をお持ちであれば、手軽に試すことができます。

YOLOの使い方
インストール
リポジトリをクローンし、必要なライブラリをインストールします。
git clone https://github.com/ultralytics/yolov5
cd yolov5
pip install -r requirements.txtロード
import torch
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')認識させてみる
ロードしたYOLOのモデルには、画像ファイルのパスもしくは、直接numpy配列の画像配列などを入力することができる。
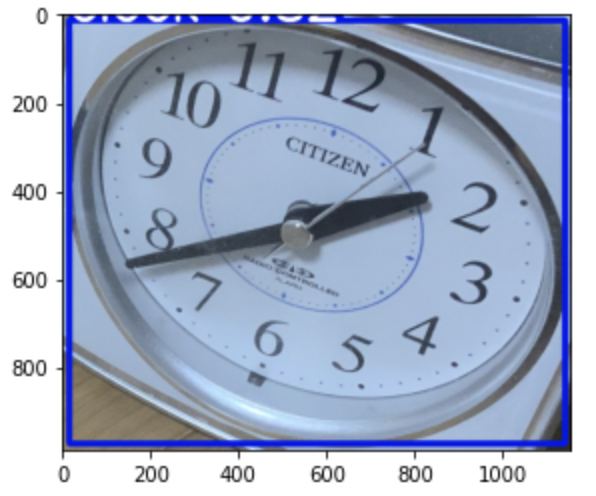
今回は、試しにiPadで撮影した以下の画像を入力してみた。

image_path = '/content/test_image.jpeg'
results = model(image_path)結果がresultsに格納されているので、結果を確認します。
printを実行
results.print()image 1/1: 3024x4032 1 cell phone, 1 clock
Speed: 290.1ms pre-process, 2789.1ms inference, 1.1ms NMS per image at shape (1, 3, 480, 640)print()を実行すると、入力された画像について、サイズ、写っている物体のクラスとその個数が示されていることがわかります。その他、各種処理に要した時間なども記載されています。
saveを実行
results.save()
# デフォルト:save(labels=True, save_dir='runs/detect/exp')saveを実行すると、入力画像にバウンディングボックスおよび、認識クラスとその確度が追記された画像が保存されます。

pandasを実行
df = results.pandas().xyxy[0]上のコードを実行すると、認識されたオブジェクトごとに、バウンディングボックスの位置や、クラス、確度が得られます。
今回の画像の場合は、以下のような結果が得られます。

crop
results.crop()
# デフォルト:crop(save=True, save_dir='runs/detect/exp')cropを実行すると、認識したオブジェクト情報と、その部分を切り抜いた画像の配列が辞書形式で、認識されたオブジェクト全てについてリストでまとめられたものが得られます。


モデルの設定を変更する方法
model.conf = 0.25
# 信頼度の閾値を0から1の範囲で設定。1に近いと、信頼度が大きくないと検出されない。
model.iou = 0.45
# NMS IoUの閾値を0から1の間で指定。
# 検出範囲が曖昧なバウンディングボックスをどこまで許すかを決定。
# 上記のように0.45とした場合、IoUが0.45未満のものは除去される。
model.classes = None
# 認識してほしいクラスのみを指定できる。
# 例えば、人間と猫と犬のみ認識してほしい場合は、[0, 15, 16]のように指定する。
results = model(imgs, size=320) # カスタム推論サイズを指定可能IoUとは、Intersection of Unionのことで、複数のバウンディングボックスが生成されたときの、バウンディングボックス同士の重なり度合いを表します。そこでIoUに閾値を設定し、ある閾値以上のバウンディングボックスを残します。さらに、残ったバウンディングボックスから、IoUが最大のもののみを残すのが、NMS(Non-Maximum Suppression)です。
ROSでYOLOv3を試す
ここでは、ROSがインストールされていることを前提に、YOLOv3を試す方法を説明します。
カメラはRealSenseを使用しました。RealSenseをROSで使うためのコードは以下の記事で解説していますので気になる方は試してみてください。Dockerを使ってROS環境も同時に構築する方法も解説しています。

インストール方法
以下のコードを実行することで、YOLOv3をインストールすることができます。
cd ~/catkin_ws/src
git clone --recursive https://github.com/leggedrobotics/darknet_ros.git
cd ..
catkin_make -DCMAKE_BUILD_TYPE=Release認識に使う画像データ(トピック)の指定
catkin_ws/src/darknet_ros/darknet_rosフォルダの中にros.yamlという設定ファイルがあるので、YOLOが受け取るトピックを指定することができます。私はRealSenseを使用したので、RealSenseの生画像データが流れているトピックの/camera/color/image_rawを、ros.yamlのsubscribersのtopicに指定しました。
subscribers:
camera_reading:
topic: /camera/color/image_raw
queue_size: 1起動方法
RealSenseを使用する場合は、まず最初に以下のコードを実行します。
roslaunch realsense2_camera rs_camera.launch※参考記事↓
新たに別のターミナルを起動して、YOLOv3をroslaunchします。
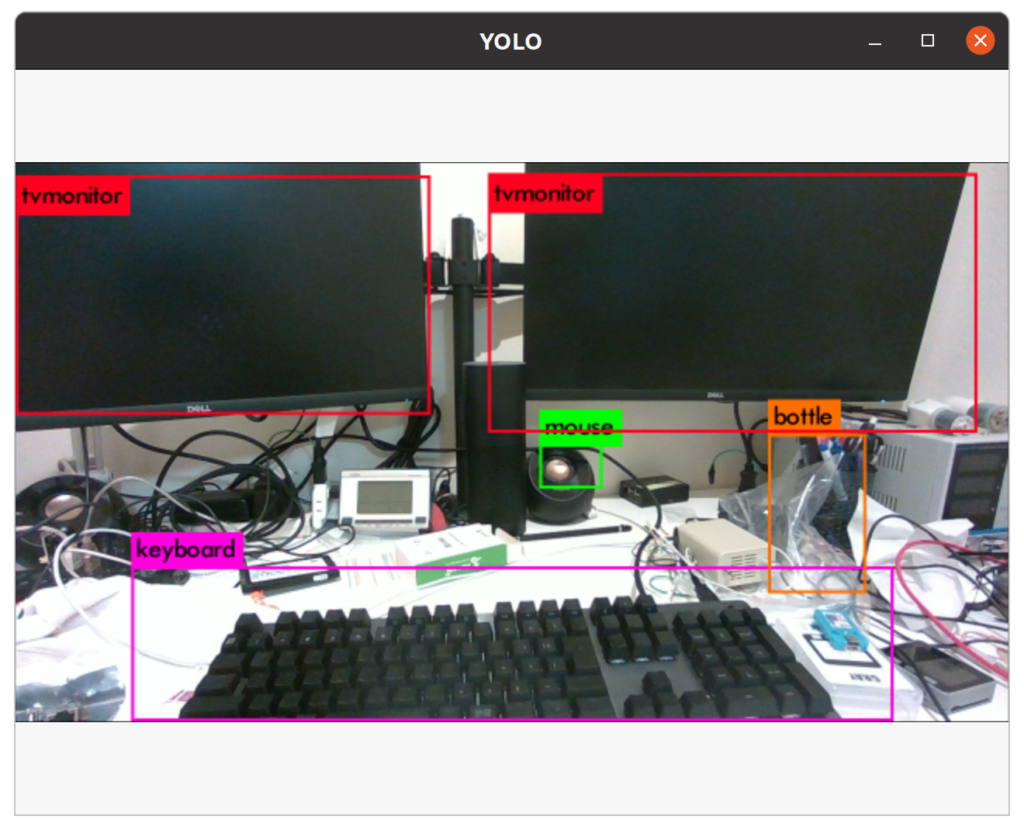
roslaunch darknet_ros darknet_ros.launchすると、以下の写真のようなGUIが起動し、RealSenseから取得された画像にバウンディングボックスを追加したものが表示されます(以下の写真は私の作業机の上です)。
※Dockerを使っている場合はコンテナ生成時にGUIの表示に関する設定を行わないと表示されません。
YOLOXを試す
YOLOXは以下のリポジトリで公開されています。ここでは、このリポジトリの内容を参考に、使用方法を紹介します。
インストール方法
以下のコードを実行します。
git clone https://github.com/Megvii-BaseDetection/YOLOX.git
cd YOLOX
pip3 install -v -e .次に、ベンチマーク表から使用したいモデルを選び、表にweightsという項目があると思いますので、そこから該当の重みをインストールします。
例として、YOLO-xの重みをインストールしたい場合は以下のコードを実行します。
wget https://github.com/Megvii-BaseDetection/YOLOX/releases/download/0.1.1rc0/yolox_x.pth実行
画像の場合
以下のコードを実行することで、YOLOXを試すことができます。私の場合はYOLOX-xを選んだので、その場合のコードを示します。もし、YOLO-mなど異なるモデルを選んだ場合は、以下のコードを参考に、適切に変更してください。
※先ほどダウンロードした重みのpathも忘れずに指定してください。
# YOLOXディレクトリの直下で実行する
python tools/demo.py image -n yolox-x -c /path/to/your/yolox_x.pth --path assets/dog.jpg --conf 0.25 --nms 0.45 --tsize 640 --save_result --device [cpu/gpu]動画の場合
入力が動画の場合は、以下のコードを実行します。
※先ほどダウンロードした重みのpathと、入力する動画ファウルを指定してください。
python tools/demo.py video -n yolox-x -c /path/to/your/yolox_x.pth --path /path/to/your/video --conf 0.25 --nms 0.45 --tsize 640 --save_result --device [cpu/gpu]参考文献
[1] Joseph Redmon, Santosh Divvala, Ross Girshick and Ali Farhadi. "You Only Look Once: Unified, Real-Time Object Detection." In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
[2] Joseph Redmon and Ali Farhadi. "YOLO9000: Better, Faster, Stronger." In CVPR, pp. 6517–6525. IEEE Computer Society, 2017.
[3] Joseph Redmon and Ali Farhadi. "YOLOv3: An Incremental Improvement." arXiv, 2018.
[4] Alexey Bochkovskiy, Chien-Yao Wang, and Hong-Yuan Mark Liao. "YOLOv4: Optimal Speed and Accuracy of Object Detection." arXiv, Vol. abs/2004.10934, 2020
[5] ultralytics. "yolov5" https://github.com/ultralytics/yolov5/blob/master/README.md, (2022-04-03).
[6] ultralytics. "YOLOv5 Documentation" https://docs.ultralytics.com/, (2022-04-03).
[7] Zheng Ge, Songtao Liu, Feng Wang, Zeming Li and Jian Sun. "YOLOX: Exceeding YOLO Series in 2021." CoRR, vol. abs/2107.08430, 2021.
[8] Chuyi Li, Lulu Li, Hongliang Jiang, Kaiheng Weng, Yifei Geng, Liang Li, Zaidan Ke, Qingyuan Li, Meng Cheng, Weiqiang Nie, Yiduo Li, Bo Zhang, Yufei Liang, Linyuan Zhou, Xiaoming Xu, Xiangxiang Chu, Xiaoming Wei, and Xiaolin Wei. 2022. "YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications." arXiv. DOI:https://doi.org/10.48550/ARXIV.2209.02976
[9] Chien-Yao Wang, Alexey Bochkovskiy, and Hong-Yuan Mark Liao. 2022. "YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors." arXiv. DOI:https://doi.org/10.48550/ARXIV.2207.02696