
本記事は、当サイトのYouTubeチャンネルで公開している動画「[Weekly RL with code]BipedalWalker 様々な強化学習アルゴリズムを比較!」の内容を文字に書き起こしたものです。
記載内容は動画と同じです。動画もしくは記事の、お好みの媒体で強化学習について学ぶことができます。
※ Weekly RL with codeは、当サイトがコード付きで強化学習の話題を毎週発信するシリーズです。動画はYouTubeで公開しています。ぜひご覧ください。
今回の内容
今回のWeekly RL with codeのテーマは、簡易的な二足歩行ロボットの学習環境であるBipedalWalker環境を、色々な強化学習アルゴリズムで学習させてみて結果を比較するというものです。今回扱う強化学習環境は前回も扱ったものと全く同じですので、BipedalWalker環境の詳細な説明は、省略します。気になる方は前回の動画を見てみてください。

コードはgoogle colaboratoryで実行します。今回扱ったコードはノードブック形式で公開していますので、ぜひご利用ください。リンクは概要欄に記載の通りです。
BipedalWalker環境について
BipedalWalker環境の概要、状態や行動、報酬、初期分布について、詳細は以下の記事で説明していますので、この記事では省略させていただきます。

比較するアルゴリズム
今回、BipedalWalker環境を用いて性能を比較するアルゴリズムは以下の8つです。arXivに投稿された順番に並べて表にしました。アルゴリズム名には、該当する論文のリンクが貼ってあるので興味がありましたら読んでみてください。
| アルゴリズム | 投稿日(arXiv) |
| Trust Region Policy Optimization (TRPO) | 2015/1/19 |
| Deep Deterministic Policy Gradient (DDPG) | 2015/9/9 |
| Advantage Actor-Critic (A2C) | 2016/2/4 |
| Proximal Policy Optimization (PPO) | 2017/7/20 |
| Soft Actor-Critic(SAC) | 2018/1/8 |
| Twin-Delayed Deep Deterministic policy gradient (TD3) | 2018/2/26 |
| Augmented Random Search (ARS) | 2018/3/19 |
| Truncated Quantile Critics (TQC) | 2020/5/8 |
コードについて
コードはここで公開しています。学習結果は、BipedalWalkerを動かして動画として可視化するとともに、TensorBoardで報酬や損失の値などをグラフ表示します。リンクのColabノートブックをColabで開くと、私が実行したときのTensorBoardがキャッシュされているので、ほぼ全てのグラフを見ることができます。
視覚的な結果の比較
結論から言うと、8個のアルゴリズムのうち、歩行を獲得できたのは、4つのアルゴリズムだけです。どのアルゴリズムが歩いたかは以下の動画を見て確認してみてください!
TRPO
DDPG
A2C
PPO
SAC
TD3
ARS
TQC
グラフで比較
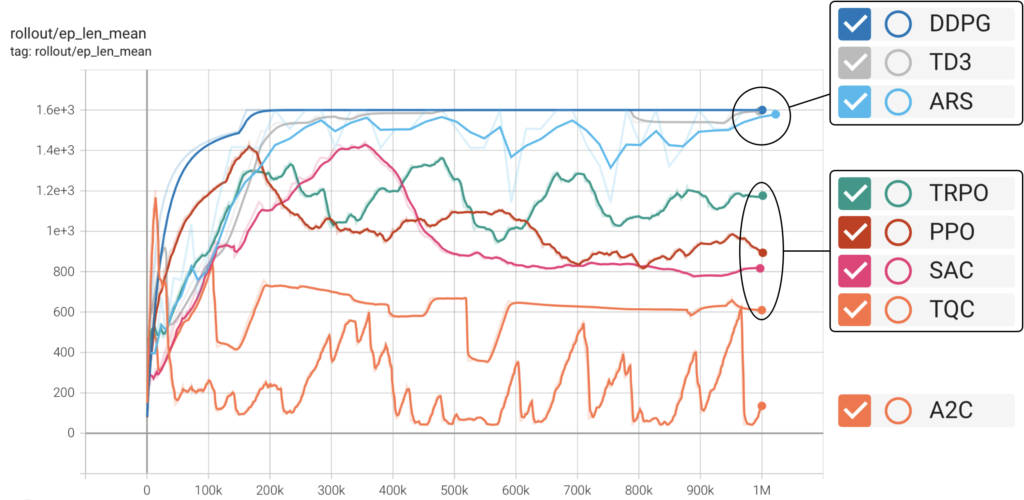
エピソード長の平均
横軸は学習ステップ数、縦軸はエピソード長です。DDPGとTD3、ARSはおおよそエピソードの最大ステップ数に到達していると考えて問題ないでしょう。しかし、これらのアルゴリズムはどれも歩行しませんでした。あくまでも私の解釈ですが、失敗時の大きな負の報酬を避けるあまり、最後まで歩かずに乗り切る選択肢を選んだアルゴリズムと言えます。なかでもDDPGはいち早く歩くのを諦めたアルゴリズムですね。エピソード長が中間ほどに位置する、TRPO、PPO、SAC、TQCはどれも歩いたアルゴリズムです。また、歩いたアルゴリズムの中でも、TQCが最も歩行速度が速く、短い時間でゴールに到達できていると考察できます。A2Cはよくわかりませんね。歩くときもあったのでしょうか。。。
エピソード長の平均から分かることは、歩いたアルゴリズムの中で最も性能が高かったのは、TQCであるということです。
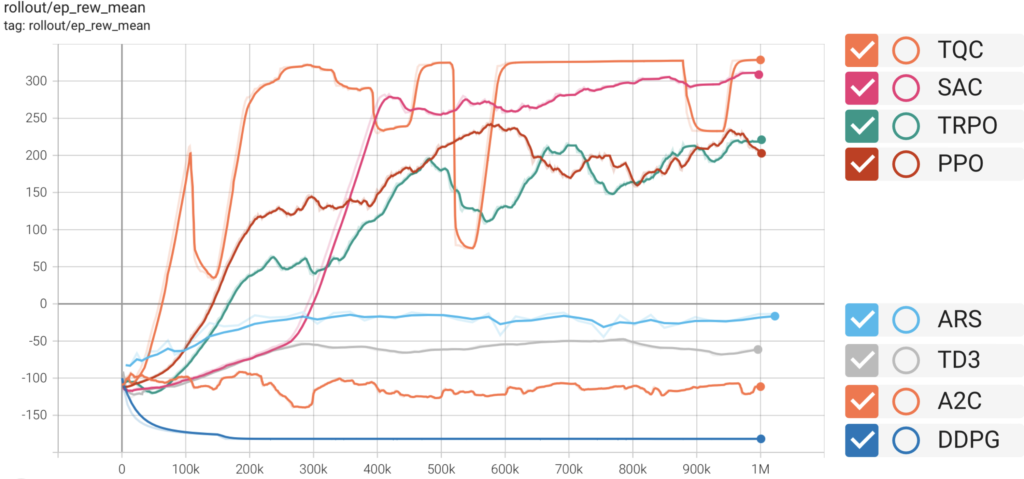
エピソードにおける報酬の平均
次に、エピソードにおける報酬の平均で比較してみます。これは、歩いたアルゴリズムと歩かなかったアルゴリズムで綺麗に2分されました。歩くアルゴリズムは上の4つ、歩かなかったのは下の4つです。先に、歩かなかったアルゴリズムの方を見ると、DDPGについては、学習開始時よりも報酬が悪くなっています。その他の歩かなかったアルゴリズムを含め、このまま学習を続けても改善は見らないことが予想されます。一方で、歩いたアルゴリズムを見ると、少ないステップ数で学習が進んでいるのはTQCで、その後にPPO、TRPO、SACが続いています。補足ですが、学習時間についてはオンポリシー型のPPOが最も早いでしょう。一見、TQCの一本勝ちに見えますが、所々で谷ができており、安定性についてはSACの方が勝っているように見えます。
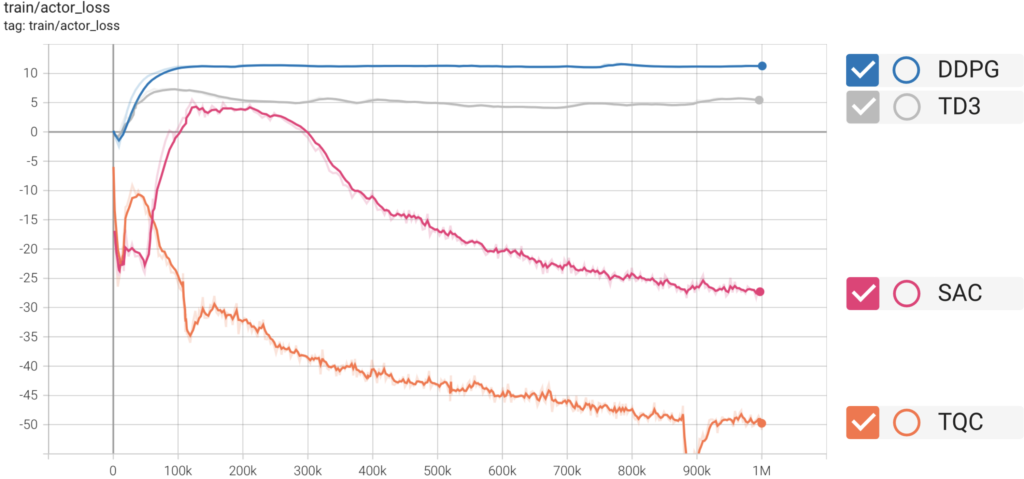
Actorの損失
次に、Actorの損失を比較してみます。損失なので、学習が進むにつれて値が小さくなることが望まれます。最も早く損失が小さくなっているのはTQCです。TQCとSACはともに、学習を進めればまだActorの損失が小さくなると考えられます。
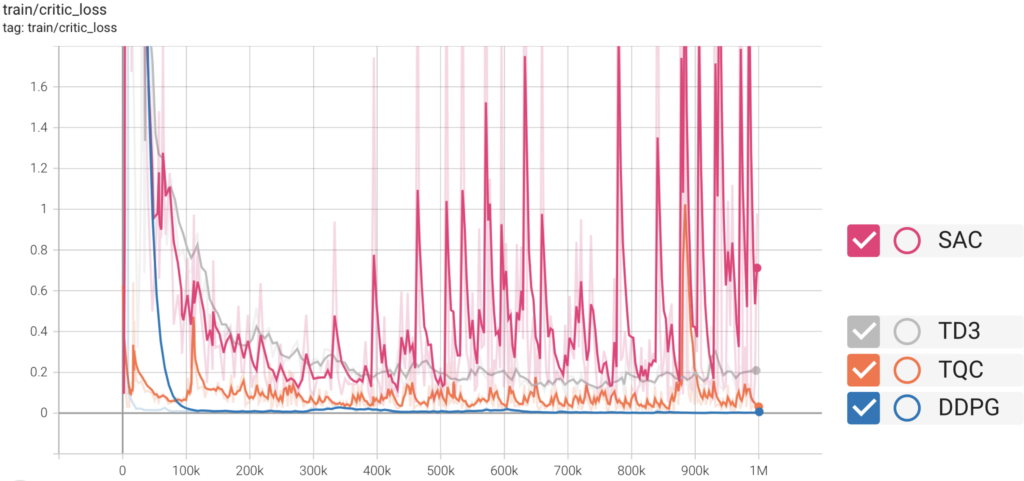
Criticの損失
最後に、Criticの損失です。ここで注目したいのは、SACです。損失の値が大きく振動しています。ただ、これだけでSACは性能が低く安定しないアルゴリズムと考えるのは早いかもしれません。SACは意図的に、行動のランダム性を持たせることで強化学習における活用と探索のトレードオフに対処しています。すなわち、しっかり探索をしているあかしだと考えられます。TQCについてはCriticの損失が安定しており、そこらへんがSACよりも改善されたのでしょう。
まとめ
今回は、BipedalWalker環境を用いて、さまざまな強化学習アルゴリズムを比較しました。SACとTQCが学習能力が高いことが分かりました。
また、BipedalWalker環境で比較した結果がすべてではないと思うので、別の環境でも試してみたいと思います。
動画は以上になります。今後も、週1でWeekly RL with codeを公開していきますので、ぜひチャンネル登録をよろしくお願いいたします。
最後までお読みいただきありがとうございました。