
本記事は、世界モデルを用いた4脚ロボットの歩行学習について調査しまとめたものです。
スライドは以下で公開しています。
また、解説動画も出しています。必要に応じてご利用ください。
ロボットの学習
ロボットの学習では、一般的に強化学習が使われます。理由としては、ロボットには様々な形状があり、動作に関する教師データを動物から取得することが難しく教師あり学習が適用できないからです。教師データが取得できなくても、出力の良し悪しを数値化できれば適用できる強化学習は、ロボットの学習に適しています。強化学習では出力の良し悪しを評価する関数を報酬関数と呼び、その報酬関数から得られる即時報酬を将来にわたり加算(割引報酬和)したものが最大化されるように学習を行います。
また、使用される多くの強化学習アルゴリズムはオンライン型であるため、途中で学習を終了させない限り延々と学習を行わせることが可能で、人間のように継続的かつ適応的な行動を獲得できる可能性を秘めています。
シミュレータを用いた強化学習
ロボットの強化学習は、一般的にシミュレータで行います。主な理由は2つあります。
① 学習速度
② 耐久性
です。①については、実世界で学習を行うと、実時間でしか学習を行うことができません。そのため、何百万回にも及ぶ学習を行おうとすると、何カ月と時間がかかってしまう可能性があります。これが、シミュレータを用いれば、実時間よりも高速で時間を進めることができるため、学習を圧倒的に高速化できます。また、学習環境を複製して同時に学習を進めれさらに高速化できる可能性があります。
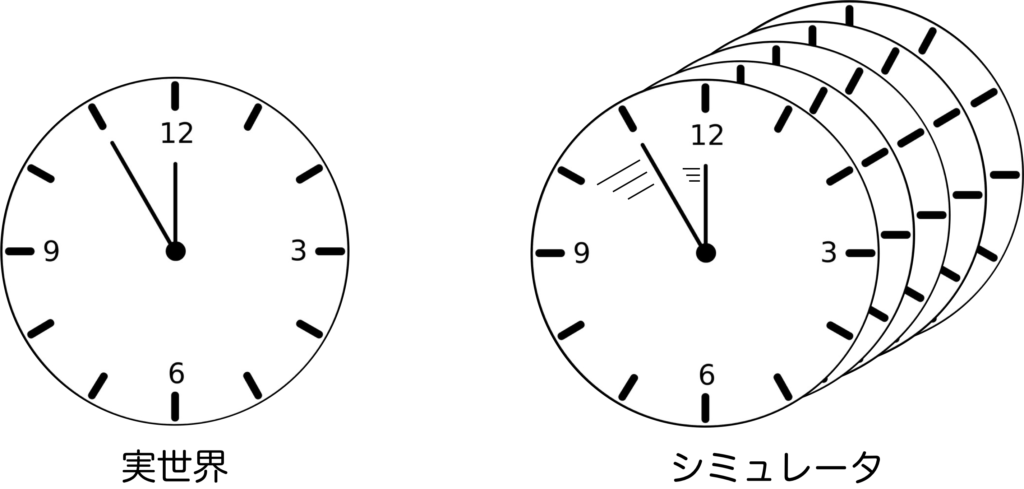
②については、実世界でロボットの学習を行うと、実機を動かす必要があるため、学習中にロボットは故障する可能性があり、耐久性の問題が発生します。これが、シミュレータならロボットの故障の問題を学習から完全に排除できます。

このような利点から、シミュレーション環境をコンピュータ上に作成して、その中でロボットの強化学習を行うのが一般的です。
これにより、ロボットの耐久性を気にすることなく、また高速に強化学習ができます。
シミュレーション環境の欠点
しかし、シミュレーション環境を用いる方法には欠点があります。それは、シミュレーション環境は実世界とは異なるという点です。

シミュレーション環境は、人手でモノを配置したり、各種パラメータを設定したりして作成します(モータの特性、摩擦係数、重力加速度など)。実世界で計測を行いパラメータを正確に設定できればマシですが、計測できないパラメータは、設定のしようがありません。そのため、実世界とシミュレーション環境の特性が一致する領域もありますが一致しない領域もあり、一致しない領域については学習できないため対応できず、実機に適用するときに問題になるのです。それを防ぐために、環境のランダム化を行うなどのテクニックが使われます。簡単に言えば、シミュレーション環境でカバーできる経験パターンを広げることで、実世界と重なる部分を増やしてあげるというものです。これはSim2Realと呼ばれます。今紹介したSim2Realはドメインランダム化と呼ばれるもので、現在はそれ以外の様々な手法が提案されています。
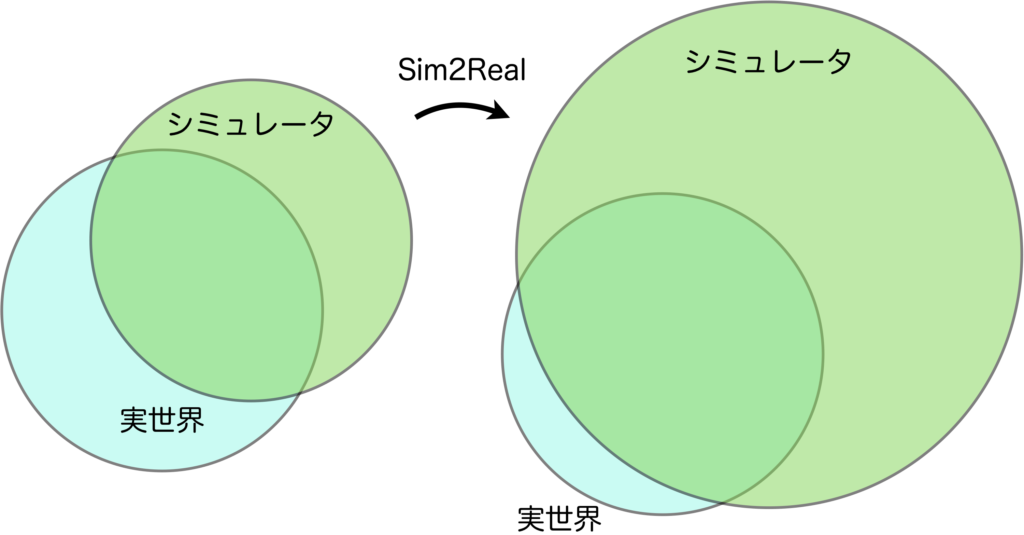
とはいえ、実世界を全てカバーすることは難しいですし、無駄が多い手法のように感じませんか?
ドメインランダム化だと、実世界では起こりえないような部分も含め、学習で獲得しなければいけない領域が広すぎます。すると学習精度を高めるのに必要な学習回数や学習時間が膨大になります。それに、実機適用するにはファインチューニングが必要になる場合が多いでしょう。
実世界の全てをカバーしなくても、よく生起する現象を重点的に学習できれば効率が上がりそうに思いませんか?
そこで、シミュレーション環境を人手で作るのではなく、実世界からサンプリングしたデータを用いて学習し、近似してしまえば良いというアイディアがあります。それが世界モデルです。
世界モデル
世界モデルとは、モデルベース強化学習において、環境の状態遷移(環境ダイナミクス)を学習するモデルになります。世界モデルは英語で、World Modelと呼ばれ、これは初代のモデルベース強化学習フレームワークであるDyna[1]の論文で出てきた古くからある概念です。
ここではモデルベース強化学習について簡単にまとめます。モデルベース強化学習は、方策モデル(Policy)と世界モデルで構成されていています。まずは実世界(下図: World)から状態\(s\)を受け取り、方策モデルから行動\(a\)を出力します。これに基づいて環境が変化するので、次の遷移先\(s'\)と報酬\(r\)を受け取り、経験として\((s,a,s',r)\)を記録します。経験が集まると環境ダイナミクス\(p(s',r|s,a)\)を計算ができるようになるので教師あり学習により学習を行います(世界モデル)。獲得された世界モデルの中で方策を学習することで、実世界を介すことなく方策を最適化することができます。世界モデルの学習と方策モデルの学習を交互に行うことで精度が向上します。
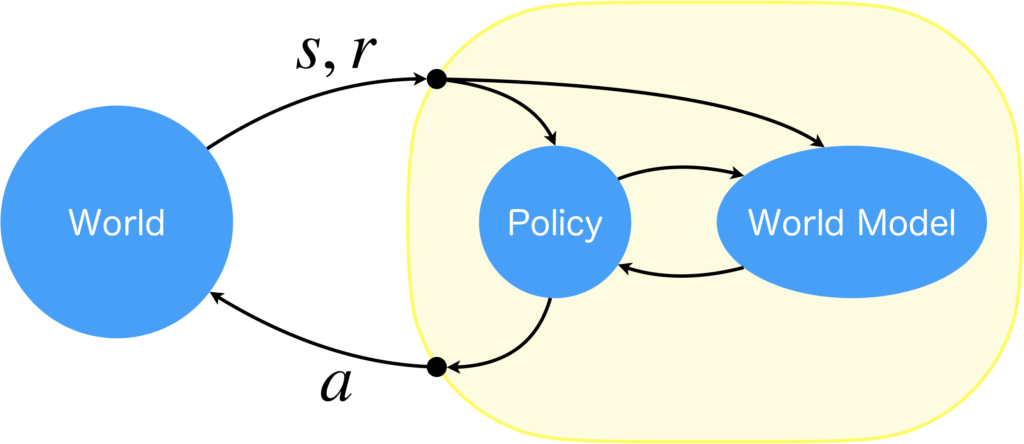
シミュレーション環境を世界モデルに置き換えることで、シミュレーション環境の作成に伴う人的コストを低減でき、また、シミュレーション環境の表現能力の制約を受ける心配がなくなります。そして、シミュレーション環境は初めに作成したものから変更するのが難しいですが、世界モデルなら学習器ですので、環境が変化しても適応することができます。人間的な知能を実現するには、世界モデルの考え方が必要不可欠だとされています。
初めて世界モデルの枠組みが出て以降、この研究は長らく下火でしたが、2018年にWorld Modelsと呼ばれる論文[2]を出して以降、再度注目されはじめ、研究が活発に行われるようになりました。
Dreamer
世界モデルを用いた強化学習として有名なモデルにDreamer[3]があります。Dreamerは3つのステップからなっています。1つ目のステップでは、経験から環境ダイナミクスを学習します。2つ目のステップでは、世界モデルの中で方策を学習します。これが夢の中で学習、すなわち夢想してるように見えるのでDreamerと呼ばれます。3つ目のステップでは、2で学習した方策を用いて実環境の中で行動し、経験を蓄積します。そして、1~3のステップを繰り返し行います。
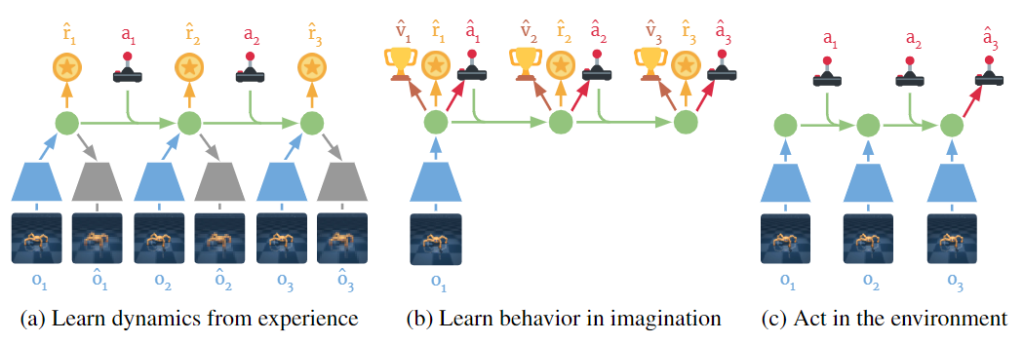
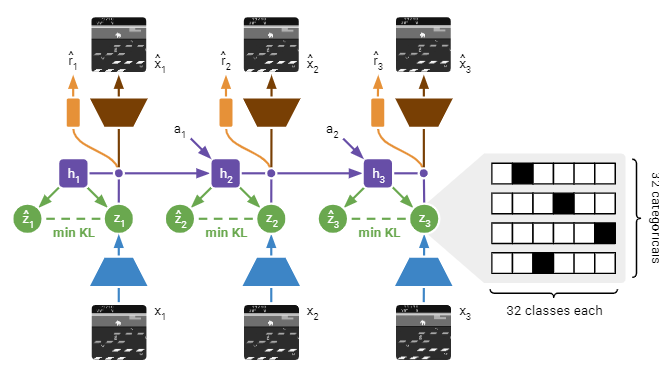
そして、より高精度なDreamerのモデルにDreamerV2[4]があります。DreamerV2は、Dreamerをベースにしつつ、幾つか改良を加えたモデルになっています。一番大きな変更点だけ紹介すると、潜在ベクトルの表現形式が変わり、表現可能な幅が広がりました。
DreamerV2は以下のリポジトリで公開されているので、そこから使用することができます。

DreamerV2による4脚ロボットの歩行学習
DreamerV2はモデルベース強化学習の中でもかなり精度が高いモデルです。これまでは、OpenAI Gymの環境での実験が中心でしたが、実際のロボットを用いて実環境で学習を行った論文が2022年に公開されました。それがDayDreamer[5]です。DayDreamerではDreamerV2を使っているので下図は、上図と描き方が異なるだけで同じものを表しています。異なるのは、入力と出力に画像以外のモダリティも使用している点です。
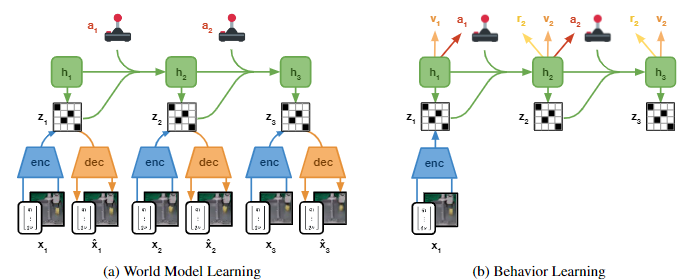
4脚の歩行学習では、寝転んだ状態から始め、約1時間で歩行できるようになりました。一方で、SACの場合は1時間で獲得できたのは寝返りだけだったようです。Dreamerを用いた方がSACよりも優れた結果を出せたという点は、下図右の報酬グラフからも分かります。

そして、強化学習においては外乱に対しても弱いというものがありますが、Dreamerの場合は、横から力を加えて転ばせたときの、復帰も10分程度の追加学習で獲得できたようです。

たった1時間程度で歩けるようになるというのはとても凄いことだと思います。では具体的にどのような観測、行動、報酬を用いたかを紹介します。
観測
観測としては、各モータの角度、姿勢、角速度を扱っています。
行動
各モータの角度を行動出力としています。
その出力を用いてPDコントローラにより20Hzで制御を行います。
報酬
報酬関数は、以下の5つの報酬項の和として表されるようです。
$$
r^{upr} = \frac{1}{2}(\boldsymbol{\hat{z}}^T[0,0,1]+1)
$$
※論文では1を引いているのですがプログラムコードを見る限り足している為、ここには1を加算する式を記載
$$
r^{hip} = 1 - \frac{1}{4}||q^{hip} + 0.2||_1
$$
$$
r^{shoulder} = 1 - \frac{1}{4}||q^{shoulder} + 0.2||_1
$$
$$
r^{knee} = 1 - \frac{1}{4}||q^{knee} - 1.0||_1
$$
$$
r^{velocity} = 5\left(\frac{\max(0, \mathcal{B}_{v_x})}{|| \mathcal{B}_{v}||_2}\cdot \text{clip}\left(\frac{ \mathcal{B}_{v_x}}{0.3}, -1, 1\right) + 1\right)
$$
順番に、働きを確認してみましょう(私の理解が間違っている可能性があるのでご了承を)。
\(r^{upr}\)は、直立報酬(upright reward)で、胴体が歩行に適した向き(=地面に対して水平)になっているかを評価します。
詳細の計算については、胴体の上方向を表すベクトル\(\boldsymbol{z}\)(ロボットの胴体座標におけるz軸の方向ベクトル)と、\([0,0,1]\)(ワールド座標におけるz軸の方向ベクトル)の内積から、ロボットの胴体が歩行に適した向きになっているかを評価しているようです。ですので、転倒していたら胴体が横を向くため、内積の値が小さくなり、胴体が地面に対して水平で歩行に適した向きになっていれば内積の値が大きくなるという評価をしていると考えられます。
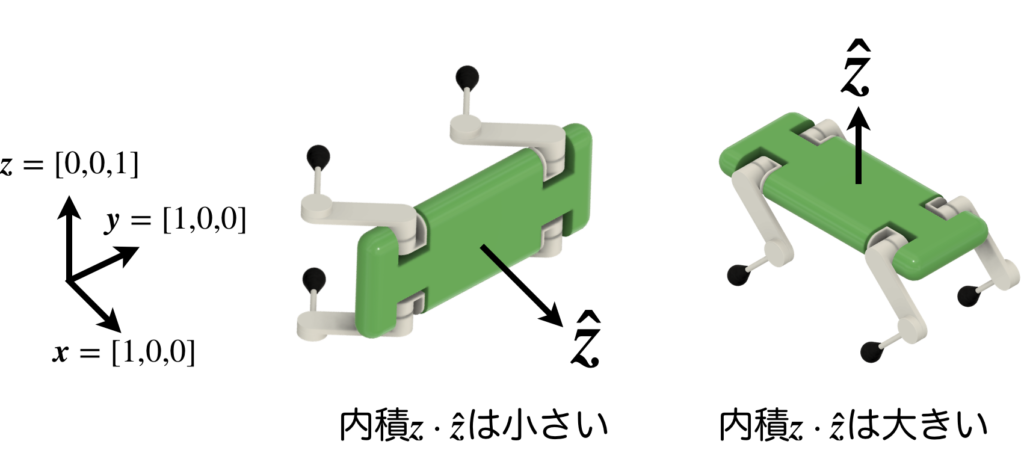
そして、この報酬\(r^{upr}\)の値が0.7よりも小さい場合は、以降で説明する\(r^{hip}, r^{shoulder}, r^{knee}, r^{velocity}\)は得ることができません。それは、これら4つの報酬項は、ロボットの胴体が歩行できる向きになっていて初めて意味を成すものだからです。寝転んでいるときにこれら4つの報酬から高い値を得たとしても意味がありませんので、0.7以下の場合は全て強制的に0になります。
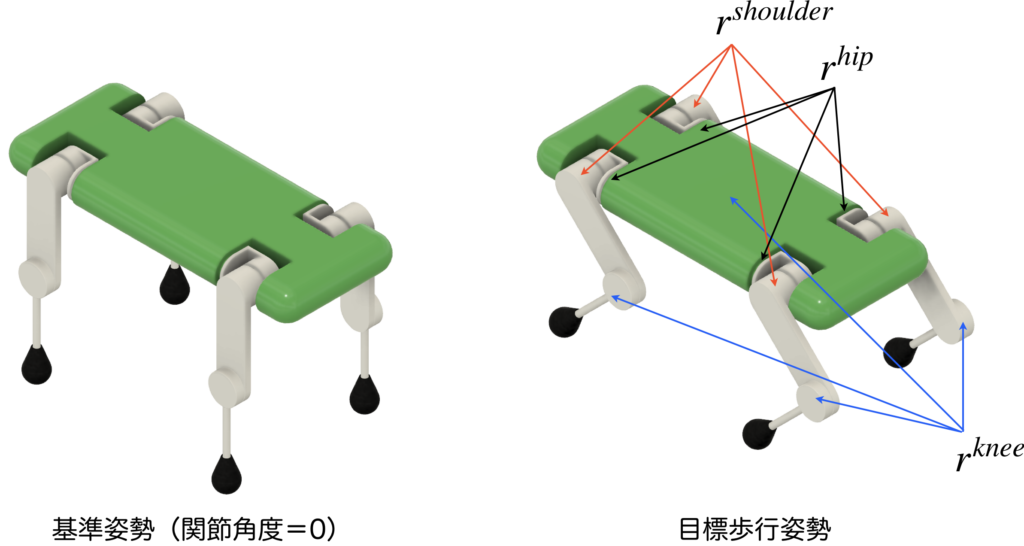
\(r^{hip}\)は、脚の付け根の4つの関節角度の平均値\(q^{hip}\)を評価する報酬です。式より、\(q^{hip}=-0.2\)において値が最大になるので、この報酬項は、該当の4つの関節角度の平均が-0.2付近になるよう促していると考えられます。
\(r^{shoulder}\)は、肩の4つの関節角度の平均値\(q^{shoulder}\)を評価する報酬です。式より、\(q^{shoulder}=-0.2\)において値が最大になるので、この報酬項は、該当の4つの関節角度の平均が-0.2付近になるよう促していると考えられます。
\(r^{knee}\)は、膝の4つの関節角度の平均値\(q^{knee}\)を評価する報酬です。式より、\(q^{knee}=1.0\)において値が最大になるので、この報酬項は、該当の4つの関節角度の平均が1.0付近になるよう促していると考えられます。
\(r^{velocity}\)は、前進速度に関する報酬項です。ロボットの胴体の移動速度を\(\mathcal{B}_{v}\)、ロボットの前進速度を\(\mathcal{B}_{v_x}\)とし、これらを用いて、前進速度に関する評価を行います。
ここまで説明してきた5つの報酬項についてまとめると、歩行するには胴体の向きが地面と水平に近くないといけないため、それを\(r^{upr}\)で獲得させ、歩行時の脚の関節角度については\(r^{hip}, r^{shoulder}, r^{knee}\)で、前進歩行の動作は\(r^{velocity}\)で獲得を目指していると考えられます。
ロボットの研究あるあるですが、報酬関数はかなり恣意的に調節されている印象があります。そのため、報酬関数の中に含まれている係数などの数値は、ロボットごとに調節させる必要があると考えられます。
報酬計算のプログラムは以下のページから見ることができますので、気になる方は読んでみてください。
まとめ
ロボットの学習には強化学習が用いられ、その高速化と耐久性のためにシミュレータを使用することが一般的ですが、シミュレーション環境の作成には人的コストがかかるという問題があります。また、シミュレーション環境は実世界を完全に再現しているわけではないため、世界モデルを用いた強化学習が注目されています。
世界モデルを用いた代表的な強化学習手法には、Dreamerがあります。現在ではDreamerを改良したモデルであるDreamerV2が使われることがあります。また、4脚ロボットの歩行を世界モデルを用いて獲得したものにDayDreamerがあり、DayDreamerは約1時間で寝転んだ状態から歩行動作を獲得しました。
DayDreamerでは、4脚ロボットの歩行軌道の生成に一般的に使用されるCPGやTGを使用せずに獲得されました。現時点では、不整地の歩行などの研究は発表されていませんが、今後は、そのような研究も出てくるのではないかと考えています。
参考文献
何の論文かすぐに分かるように、数字と提案手法を同時に記載しています。
[1, Dyna] Richard S. Sutton, "Integrated architectures for learning, planning, and reacting based on approximating dynamic programming," Machine learning proceedings, 1990.
[2, World Models] David Ha, and Jürgen Schmidhuber, "World Models," arXiv, 2018.
[3, Dreamer] Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi, "Dream to Control: Learning Behaviors by Latent Imagination," in Proc. ICLR, 2020.
[4, DreamerV2] Danijar Hafner, Timothy Lillicrap, Mohammad Norouzi, and Jimmy Ba, "Mastering Atari with Discrete World Models," in Proc. ICLR, 2021.
[5, DayDreamer] Philipp Wu, Alejandro Escontrela, Danijar Hafner, Ken Goldberg, and Pieter Abbeel, "DayDreamer: World Models for Physical Robot Learning," in Proc. CoRL, 2022.