
近年、追加学習無しで新たなデータに対応できる学習方法、すなわち「ゼロショット学習[1]」への関心が高まっています。この興味深い進展は、自然言語処理(Natural Language Processing: NLP)の分野でゼロショット学習の可能性が見出されたことから始まりました。その代表的な成果としてGPT-3[2]が挙げられます。GPT-3は、大量のデータを元に事前学習され、未見のタスクに対してもプロンプトを通じて直ちに対応する能力を持っています。
それに対して、画像処理の分野では、ラベル付きの画像データセットを用いた従来の方法が一般的で、ゼロショット学習の適用はまだ幅広くは実現されていません。しかし、自然言語処理におけるゼロショット学習が可能となった理由として、大量のデータセットを生成しやすい環境があること、文章を扱っていることが考えられます。
この観点から、画像処理においてもゼロショット学習を適用するためには、画像と文章を結びつけた大規模なデータセットが必要になると考えられます。そこで、これが本当に実現可能なのかを確かめるためにCLIP[3]の研究がされました。具体的には、4億組もの画像と文章のペアからなるデータセット(WebImageText)を用いて学習し、画像に対するゼロショット学習が可能であることを実証しました。これはつまり、学習時に認識対象となっていないクラスラベル、つまり初めて見る物体に対しても、後から認識できる能力を示すものです。
そしてCLIPの登場により、「Vision&Language」分野が活発化し、現在のマルチモーダルな大規模モデルや基盤モデルの基礎が形成されるきっかけとなりました。
CLIPの概要
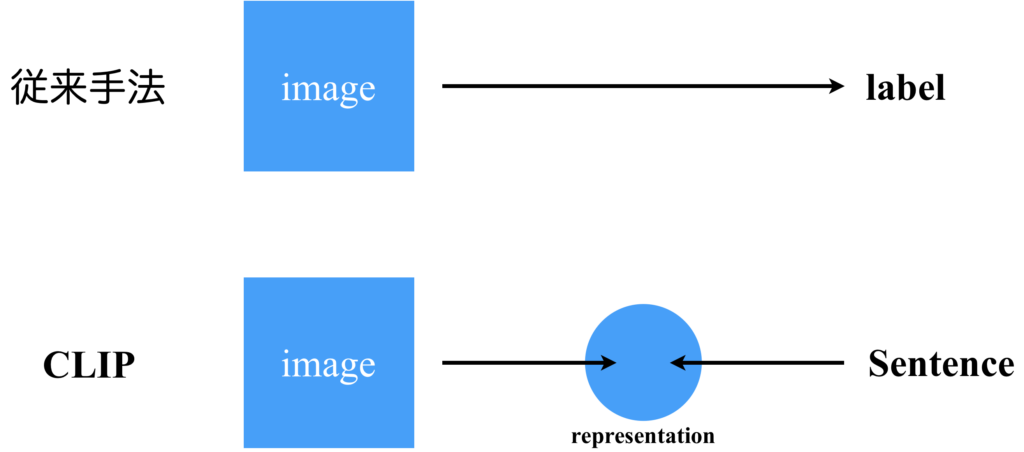
それでは、ChatGPTを例に挙げてCLIP(Contrastive Language-Image Pre-training)の概念を分かりやすく説明します。現在、ChatGPTによってプロンプトを通じて細かな指示を出したり、情報を引き出したりすることが可能となっています。プロンプトとは、私たちがChatGPTのアプリで入力する命令のことを指し、これはすでに学習済みの大規模言語モデルへの入力です。ChatGPTは特定のプロンプトを学習して記憶するのではなく、プロンプトの内容を通じて新しい知識を獲得し、学習データには含まれなかった状況にも対応することができます。ただし、プロンプトが消えれば、その知識も消えてしまいます。これが代表的なゼロショット学習というものです。
このゼロショット学習の概念を画像認識の問題に適応してみるとどうなるでしょうか。学習済みの画像分類モデルに対して、新しいクラスラベルを後からプロンプトのように与えて認識できるように訓練することが可能かどうかが一つの問いとなります。具体的には、犬を認識できる学習モデルに対して、学習時には存在しなかった新しいラベル「コーギー」を認識できるようにするといったシナリオを考えることができます。ここで、どのようにしてこの問題を解決するかがCLIPの核心になります。
従来の画像分類手法では、画像からクラスラベルへの対応を学習していました。しかし、この方法では新しいラベルに対応することが難しいという課題がありました。理由は、出力層のニューロンと任意のラベル情報が一対一で対応しているため、新しいラベルを認識可能にするには新しくニューロンを追加する必要があり、それには必ず追加で学習が必要になるからです。そこで登場したのがCLIPのアプローチです。CLIPでは、画像と文章を紐づけるように学習します。この際、従来手法を踏襲して出力をラベルから文章に変更するだけでは新しいラベルに対応させることが難しいため、画像と文章をそれぞれのニューラルネットワークで中間表現に変換し、対照学習[4]を行います。
具体的なCLIPの構造について詳しく見ていきましょう。CLIPのデータセットは、画像とそれに対応する文章がセットになったデータから成り立っています。このデータをそれぞれのエンコーダに入力します。バッチサイズを\(N\)とした場合、それぞれのエンコーダから\(N\)個の特徴ベクトルが出力されます。次に、画像と文章の特徴ベクトルを近づけるために、これらのベクトル同士の内積をとって\(N\times N\)の行列を生成します。そして、学習過程ではこの行列の対角成分の値が、それ以外よりも大きな値になるように学習されます。
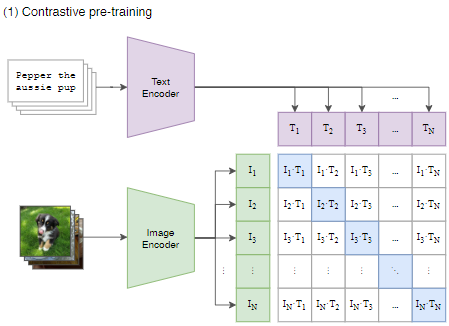
CLIPの対照事前学習は、大量のデータセットを使用するため、学習効率の観点からは必ずしも最適とは言えません。しかし、CLIPの目指すところはゼロショット学習の能力を向上させることにありますから、この点では妥協の余地があります。
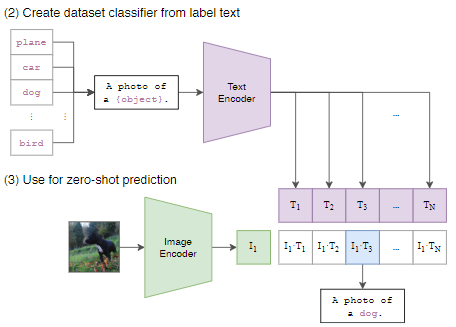
CLIPを用いて推論を行う際は、以下の図のように行います。クラス分類を行いたい画像と、クラスラベルの候補のセットをそれぞれのエンコーダに通します(学習時は画像に対応する文章を直接入力していますが、推論時は定型文のobject部分にラベル候補を入れた文章を入力している点に注意。これは定型文が変われば結果が変わる可能性があるということ)。その結果得られるそれぞれの特徴ベクトル同士の内積を計算し、その値が最大となるラベルを選択します。これにより、未知のラベルに対する認識も可能となり、ゼロショット学習の能力を発揮します。
CLIPの成果
CLIPはVision&Languageやマルチモーダルなモデルの開発において大きな一歩となりました。それは、言語と画像のベクトル計算が可能となることを示した点です。これは何を意味するのでしょうか?例えば、人の顔写真に対して「サングラスをかける」や「サングラスをはずす」といった操作を、数学的な足し算や引き算の手法で実現できるということを示しています。これまで数学的操作は主に言語処理に活用されてきましたが、それが今、画像処理にも応用できるというわけです。
さて、言語をベクトル計算が可能なものとして扱うことができるのは、Word2Vec[5]という技術があるからです。Word2Vecは単語を分散表現という形で表現する技術で、この技術を使えば、たとえば「王」から「男」を引いて「女」を足すと「女王」になるといった、直感的なベクトル計算が可能になります。今回は、この言語のベクトル空間に画像を埋め込むことを試みたわけです。
近年の画像生成AIに、DALL-E[6]やStable Diffusion[7]などがありますが、これらでも本記事で紹介した技術であるCLIPを用いて実現されています。
一見すると単純な発想なCLIPですが、現在のAI技術を支える重要な基盤を築いたというところは大きな成果と言えます。
【余談】CLIPとAttention
最後に、OpenAIが開発した「CLIP」と、Transformerで使用されるような「Attention」との関連性について私なりの考えを紹介します。
CLIPとは、画像とテキストの特徴空間を調整し、ゼロショット学習でさまざまなラベル情報を捉える能力を持つ技術です。その特長として、微細なニュアンスの違いにまで対応可能という点が挙げられます。このメカニズムは、深層学習の一手法である「Attention」に似ていると私は感じています。
Attentionとは、深層学習モデルが注意に基づいて情報を抽出する仕組みで、主にQuery、Key、Valueの3つの入力が存在します。この3つの入力が同一の場合を「Self-Attention」、Queryのみが異なる場合を「SourceTarget Attention」または「Cross Attention」と呼びます。入力の性質からSelf-Attentionはシングルモーダルな処理しか行えませんが、Cross Attentionはマルチモーダルな処理を行うことが可能です。
Attentionについて以下の記事で詳しく説明しているので、興味がありましたらぜひご覧ください。


では、なぜ私がCLIPとAttentionが似ていると考えているのか、その理由を2つ紹介します。
まず一つ目の理由ですが、Attentionにおける「Attention Matrix」は、QueryとKeyに入力されたベクトル同士の内積により求められる点です。この計算過程は、CLIPがテキスト情報の埋め込み表現と画像情報の埋め込み表現の内積を計算することで生成する行列と、非常に似ています。
二つ目の理由は、Attentionの出力がValueとAttention Matrixの内積である点です。具体的には、Attention Matrixの中で値が大きな成分に対応するValue内のベクトルが強調されて出力されるのですが、このメカニズムは、CLIPが内積が最も大きくなるラベル情報を答えとして選択する方法と非常に似ています。
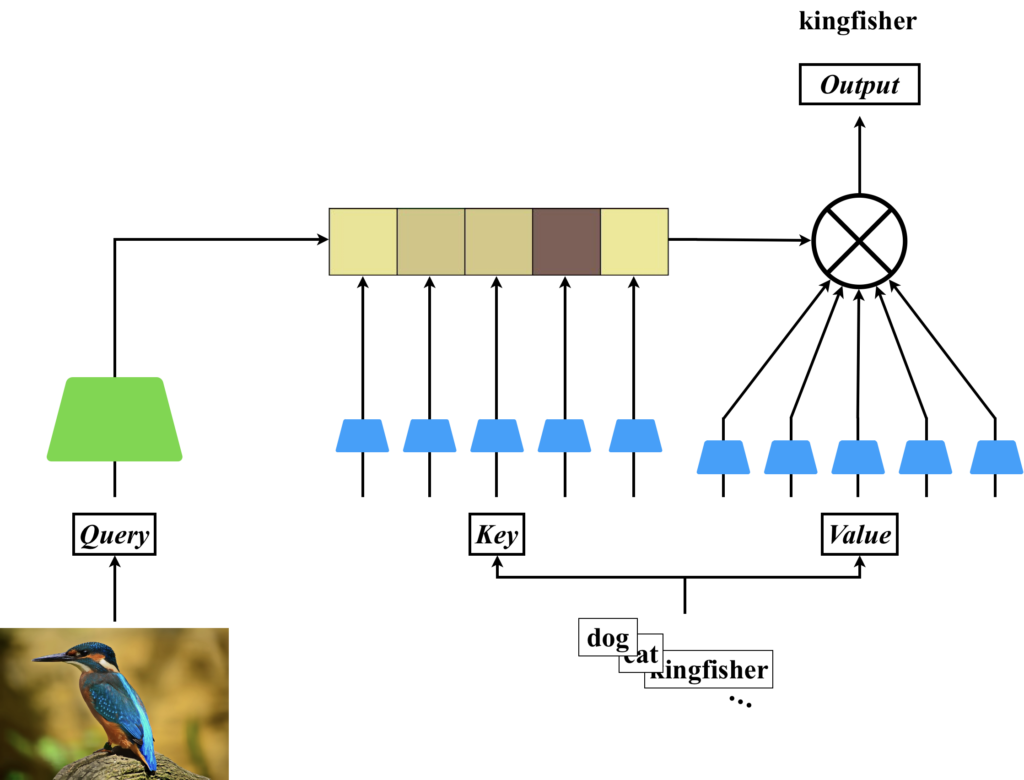
これを具体的に図にすると、以下のように考えられます。カワセミというラベルが存在しないデータセットで学習したCLIPを考えてみてください。CLIPによって計算される行列を「Attention Matrix」とするCross Attentionを想像してみます。ここで、Queryにカワセミの画像を、KeyとValueにはラベルの候補となる文章を入力します。そして、CLIPでは画像と文章の潜在ベクトル同士の内積を計算し、それをValueの行列の重みとして重み付き和を計算します。このようにして、カワセミを選択するという流れです。
まとめ
この記事では、画像のゼロショット学習が可能なCLIPという学習フレームワークについて解説しました。ゼロショット学習は、追加学習無しで新たなデータに対応できる学習方法で、特に自然言語処理の分野でその可能性が見出されました。その一方で、画像処理の分野ではゼロショット学習の適用はまだ確立されていませんでした。しかし、CLIPにより、画像と文章を結びつけた大規模なデータセットを用いて、画像に対するゼロショット学習が可能であることが実証されました。これにより、「Vision&Language」分野が活発化し、現在のマルチモーダルな大規模モデルや基盤モデルの基礎が形成されるきっかけとなりました。
参考文献
[1] Yongqin Xian, Christoph H. Lampert, Bernt Schiele, and Zeynep Akata, "Zero-Shot Learning -- A Comprehensive Evaluation of the Good, the Bad and the Ugly," TPAMI, 2018.
[2] Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei, "Language Models are Few-Shot Learners," arXiv, 2020.
[3] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever, "Learning Transferable Visual Models From Natural Language Supervision," in Proc. ICML, 2021.
[4] Ashish Jaiswal, Ashwin Ramesh Babu, Mohammad Zaki Zadeh, Debapriya Banerjee, and Fillia Makedon, "A Survey on Contrastive Self-supervised Learning," arXiv, 2020.
[5] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean, "Efficient Estimation of Word Representations in Vector Space," arXiv, 2013.
[6] Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever, "Zero-Shot Text-to-Image Generation," arXiv, 2021.
[7] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer, "High-Resolution Image Synthesis with Latent Diffusion Models," in Proc. CVPR, 2022.